标签:ota 本地 inf 教程 音乐 nload 进度 更新 log
downloader.py:文件下载小助手
一个可以用于下载图片、视频、文件的小工具,有下载进度显示功能。稍加修改即可添加到自己的爬虫中。
动态示意图:
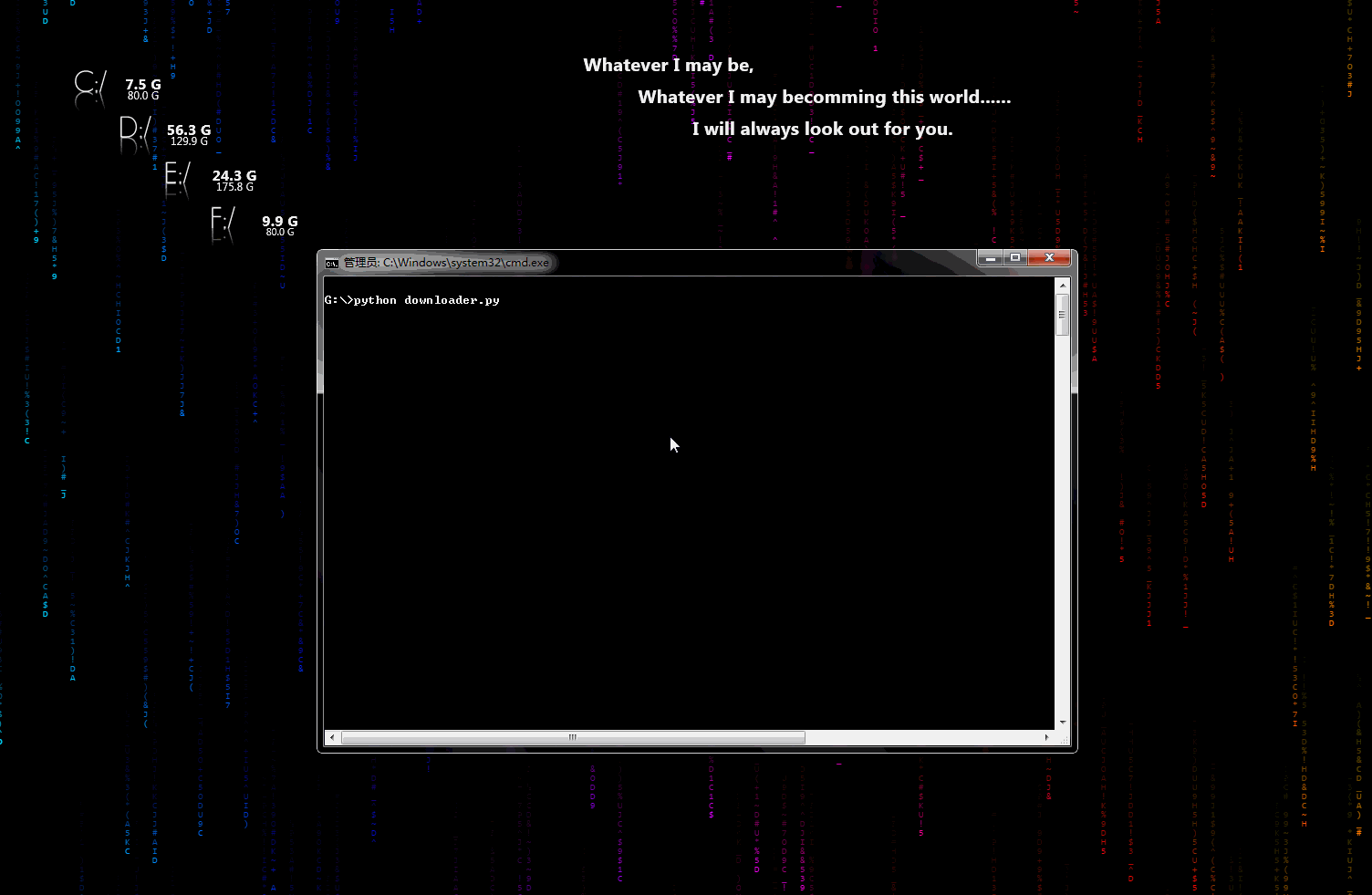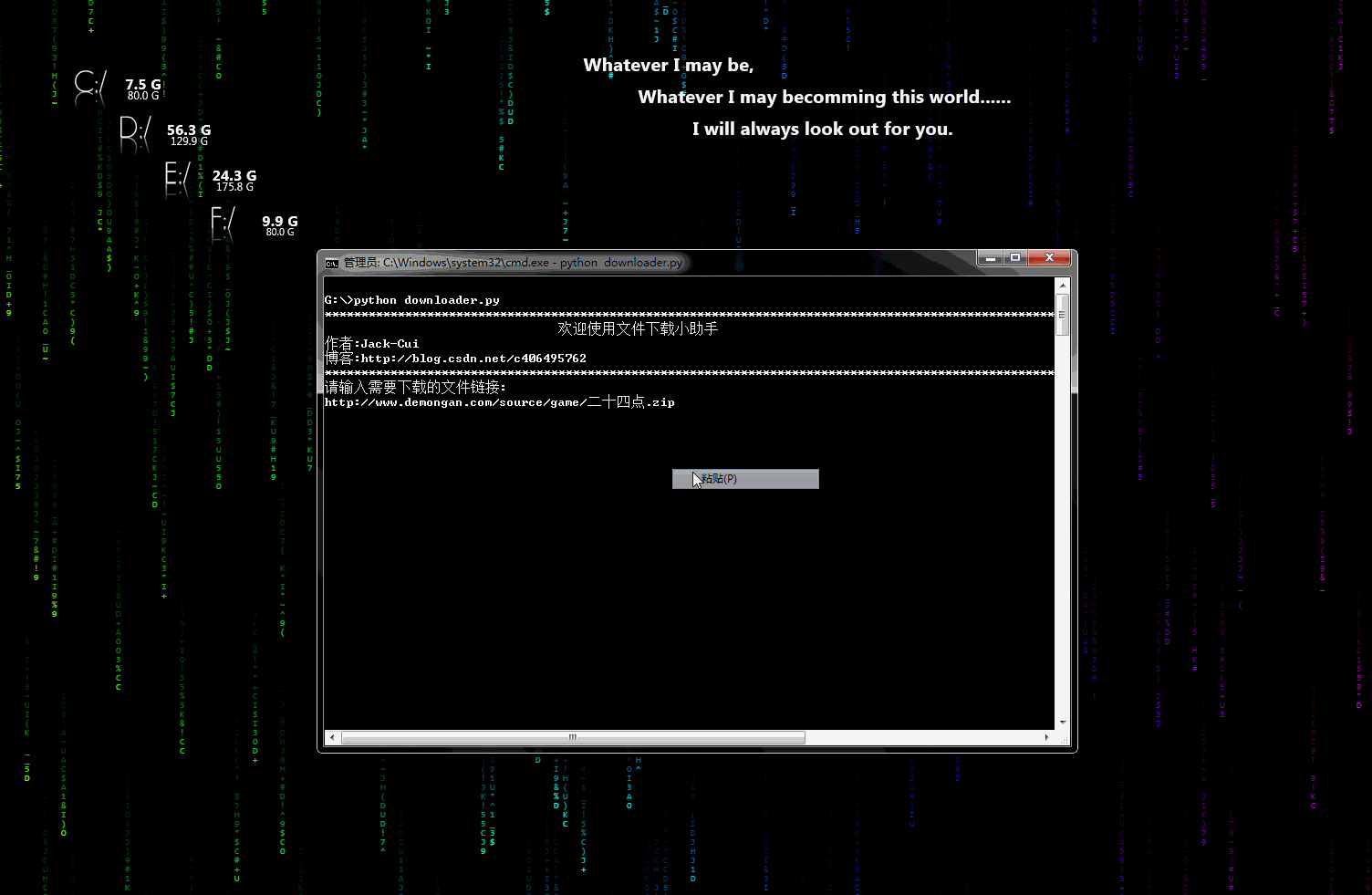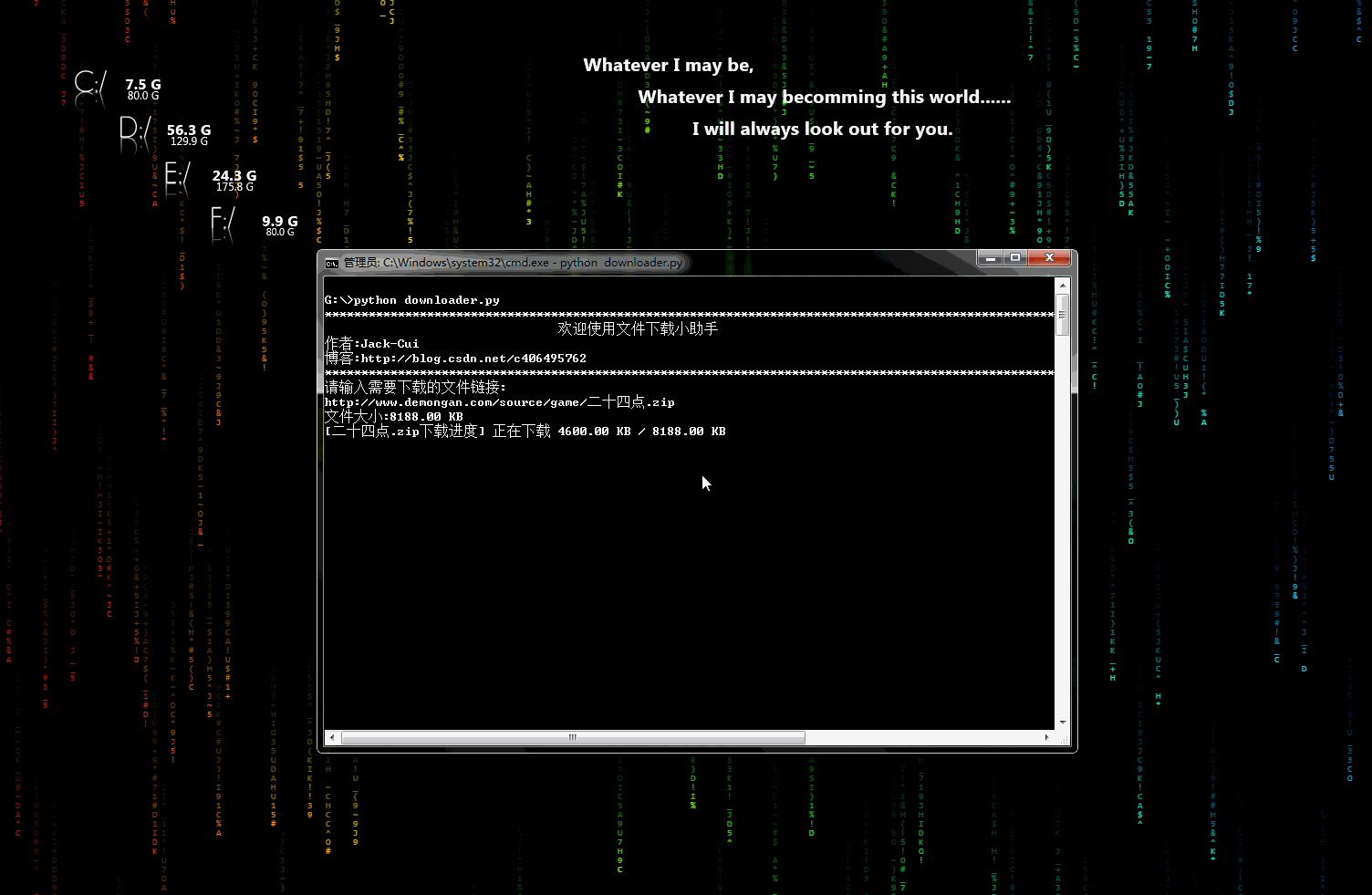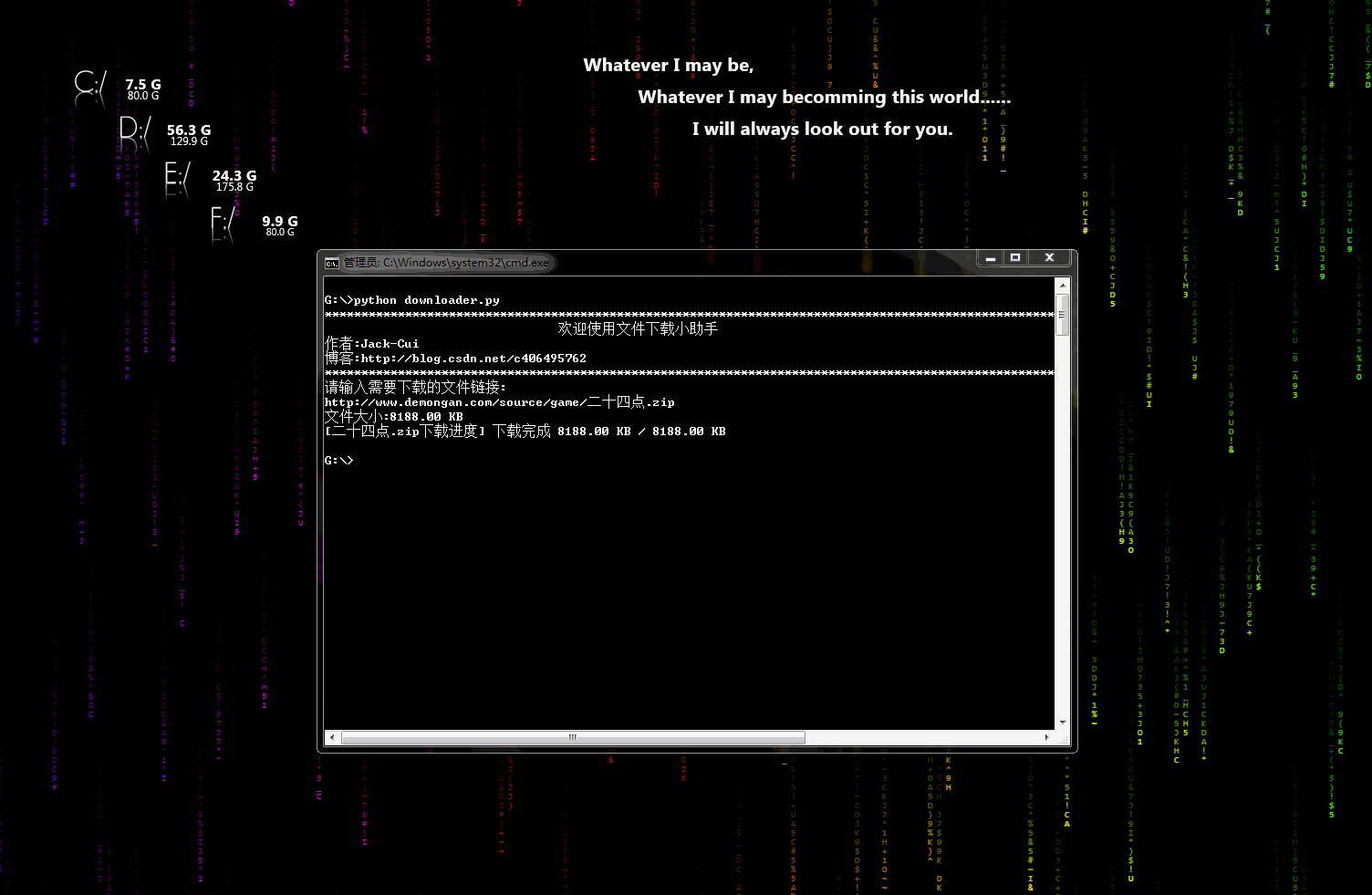
biqukan.py:《笔趣看》盗版小说网站,爬取小说工具
第三方依赖库安装:
pip3 install beautifulsoup4
使用方法:
python biqukan.py
baiduwenku.py: 百度文库word文章爬取
原理说明:http://blog.csdn.net/c406495762/article/details/72331737
代码不完善,没有进行打包,不具通用性,纯属娱乐。
shuaia.py: 爬取《帅啊》网,帅哥图片
《帅啊》网URL:http://www.shuaia.net/index.html
原理说明:http://blog.csdn.net/c406495762/article/details/72597755
第三方依赖库安装:
pip3 install requests beautifulsoup4
daili.py: 构建代理IP池
原理说明:http://blog.csdn.net/c406495762/article/details/72793480
carton: 使用Scrapy爬取《火影忍者》漫画
代码可以爬取整个《火影忍者》漫画所有章节的内容,保存到本地。更改地址,可以爬取其他漫画。保存地址可以在settings.py中修改。
原理说明:http://blog.csdn.net/c406495762/article/details/72858983
hero.py: 《王者荣耀》推荐出装查询小助手
网页爬取已经会了,想过爬取手机APP里的内容吗?
原理说明:http://blog.csdn.net/c406495762/article/details/76850843
financical.py: 财务报表下载小助手
爬取的数据存入数据库会吗?《跟股神巴菲特学习炒股之财务报表入库(MySQL)》也许能给你一些思路。
原理说明:http://blog.csdn.net/c406495762/article/details/77801899
动态示意图:

one_hour_spider:一小时入门Python3网络爬虫。
原理说明:
本次实战内容有:
douyin.py:抖音App视频下载
抖音App的视频下载,就是普通的App爬取。
原理说明:
douyin_pro:抖音App视频下载(升级版)
抖音App的视频下载,添加视频解析网站,支持无水印视频下载,使用第三方平台解析。
原理说明:
douyin:抖音App视频下载(升级版2)
抖音App的视频下载,添加视频解析网站,支持无水印视频下载,通过url解析,无需第三方平台。
原理说明:
动态示意图:

geetest.py:GEETEST验证码识别
原理说明:
无
12306.py:用Python抢火车票简单代码
可以自己慢慢丰富,蛮简单,有爬虫基础很好操作,没有原理说明。
baiwan:百万英雄辅助答题
效果图:

原理说明:
功能介绍:
服务器端,使用Python(baiwan.py)通过抓包获得的接口获取答题数据,解析之后通过百度知道搜索接口匹配答案,将最终匹配的结果写入文件(file.txt)。
手机抓包不会的朋友,可以看下我的早期手机APP抓包教程。
Node.js(app.js)每隔1s读取一次file.txt文件,并将读取结果通过socket.io推送给客户端(index.html)。
亲测答题延时在3s左右。
声明:没做过后端和前端,花了一天时间,现学现卖弄好的,javascript也是现看现用,百度的程序,调试调试而已。可能有很多用法比较low的地方,用法不对,请勿见怪,有大牛感兴趣,可以自行完善。
Netease:根据歌单下载网易云音乐
效果图:

原理说明:
暂无
功能介绍:
根据music_list.txt文件里的歌单的信息下载网易云音乐,将自己喜欢的音乐进行批量下载。
bilibili:B站视频和弹幕批量下载
原理说明:
暂无
使用说明:
python bilibili.py -d 猫 -k 猫 -p 10
三个参数:
-d 保存视频的文件夹名
-k B站搜索的关键字
-p 下载搜索结果前多少页
jingdong:京东商品晒单图下载
效果图:

原理说明:
暂无
使用说明:
python jd.py -k 芒果
三个参数:
-d 保存图片的路径,默认为fd.py文件所在文件夹
-k 搜索关键词
-n 下载商品的晒单图个数,即n个商店的晒单图
zhengfang_system_spider:对正方教务管理系统个人课表,个人学生成绩,绩点等简单爬取
效果图:

使用说明:
cd zhengfang_system_spider
pip install -r requirements.txt
python spider.py
#-*- coding: UTF-8 -*-
import requests
from contextlib import closing
class ProgressBar(object):
def __init__(self, title, count=0.0, run_status=None, fin_status=None, total=100.0, unit=‘‘, sep=‘/‘, chunk_size=1.0):
super(ProgressBar, self).__init__()
self.info = "[%s] %s %.2f %s %s %.2f %s"
self.title = title
self.total = total
self.count = count
self.chunk_size = chunk_size
self.status = run_status or ""
self.fin_status = fin_status or " " * len(self.status)
self.unit = unit
self.seq = sep
def __get_info(self):
#[名称] 状态 进度 单位 分割线 总数 单位
_info = self.info % (self.title, self.status, self.count/self.chunk_size, self.unit, self.seq, self.total/self.chunk_size, self.unit)
return _info
def refresh(self, count = 1, status = None):
self.count += count
self.status = status or self.status
end_str = "\r"
if self.count >= self.total:
end_str = ‘\n‘
self.status = status or self.fin_status
print(self.__get_info(), end=end_str, )
if __name__ == ‘__main__‘:
#url = ‘http://www.demongan.com/source/game/二十四点.zip‘
#filename = ‘二十四点.zip‘
print(‘*‘ * 100)
print(‘\t\t\t\t欢迎使用文件下载小助手‘)
print(‘作者:Jack-Cui\n博客:http://blog.csdn.net/c406495762‘)
print(‘*‘ * 100)
url = input(‘请输入需要下载的文件链接:\n‘)
filename = url.split(‘/‘)[-1]
with closing(requests.get(url, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers[‘content-length‘])
if response.status_code == 200:
print(‘文件大小:%0.2f KB‘ % (content_size / chunk_size))
progress = ProgressBar("%s下载进度" % filename
, total = content_size
, unit = "KB"
, chunk_size = chunk_size
, run_status = "正在下载"
, fin_status = "下载完成")
with open(filename, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
progress.refresh(count=len(data))
else:
print(‘链接异常‘)
标签:ota 本地 inf 教程 音乐 nload 进度 更新 log
原文地址:https://www.cnblogs.com/cilisousuo/p/12130369.html