标签:pdf转word 自己 步骤 自己的 word2013 缺陷 加载宏 占用 解决问题
2020年第一波更新,再来个重量级的刚需场景,文件互转。有Excel催化剂后,不再需要频繁到处找寻各种网页在线版的转换操作,数据安全很重要,不要轻易将自己文件上传到网上,哪天出事了,没人可怜!
文件转换的确是一个非常刚需的功能,滋生了大量的网页在线转换应用,当然也有不少是收费性质的,至于免费的也是有功能限制的如文件大小限制或转换页数限制。
因着没有过硬的数据管理能力,大量的本该在Excel上做结构化存储的数据,被分散地存储在pdf、word、甚至ppt上,这些数据的回收再加工,就有了非常刚需的场景。
同样地在人员往来过程中,为了文档的保护和查阅方便,也催生了大量的pdf版本的文件数据。pdf文件,其致命之处是,已经失去了日常我们文档中的结构化信息,如一、二级标题、正文、图片、表格等。除非用非常专业的Adobe软件才能做一些的还原。同样最大的痛点是可编辑能力几乎为0。
在一些系统导出的报表文件中,可能就出现有pdf格式的数据,对程序输出来说容易,但输出后,再加工的余地非常少。
所以pdf文件的转换,可以说是文件转换中的刚需中的刚需,为了能拿到可重新编辑的数据,重中之重,可不能让人工去一遍又一遍的复制粘贴的操作。
Excel催化剂倡导从源头解决问题,如本该使用Excel来整理数据,存储数据源的,最大可能性地培训教导一线人员做好此工作,其他各式各样的用于展现、打印、查看需求的,可灵活应用在pdf、word、ppt、html等不同场景需求的文件上。数据源是根本,务必管理好自己的数据源。
当然理想很丰满,现实很骨感,企业运作过程中,生产出大量不规范的数据及不规范的数据存储方式,也需要有一些工具功能来亡羊补牢一下。
Excel催化剂也对其做了一些补充,让数据转换过程更流畅,更重要的是转换后,能够再次轻松地从其中重新采集到所需的数据,作二次加工整理。
具体的功能实现有如下几种
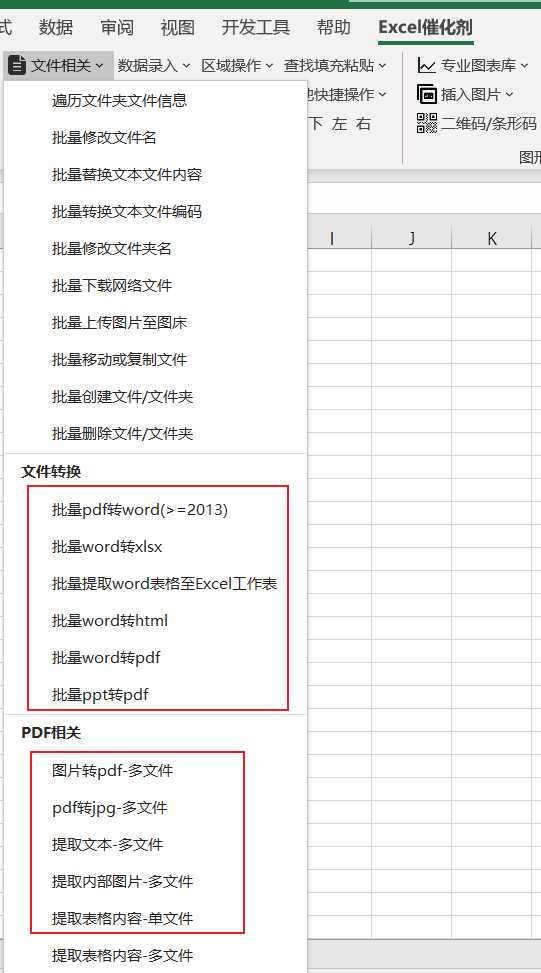
更佳的找寻菜单方式,使用搜索。

此功能对文档类型的数据非常刚需,只有数据回到Word中,才能重新有编辑的余地。此功能使用Word原生的功能,在Word2013及之后的版本中,可以直接在Word中打开pdf文件,在Excel催化剂的场景中,仅对其做了批量性操作处理,一次性处理多个Word文档。
此转换已经在2019年的功能中作了实现,可轻松完成pdf的文本信息、图片信息提取及pdf图片化保护操作。但有可能在数据提取后的再加工上,仍然不是最佳的方式,特别是需要在pdf文件中获取结构化信息时,一些表格类数据获取能力较弱。
此功能将是本篇的一大亮点功能,虽然实现起来,很不起眼, 只是很粗爆地将Word文件的数据全选后,再粘贴到Excel中。为何将其抬举到如此重要的环节?
最开始想做这个转换的动机是,因前面pdf提取表格信息有缺陷,识别率有限,若要将pdf的表格信息拿到Excel中使用,想到的迂回方式是将其转换成Word,再通过Word作中间桥梁,Word里有表格的结构化信息,可轻松提取。
后来在朋友的公众号推文中认识了Doc2Xls这款小工具,由Excel加载宏开发而成,如下图所示。
了解了一翻后,发现其实现的原理,类似于笔者之前开发过的报表结构数据源转换标准数据源的逻辑,思维定性地往此作者的实现方式的方向去思考,直到某一天一个灵光出现,直接将Word文档复制粘贴到Excel文档中,最符合笔者对此功能的期待。
Doc2xls工具,也迭代了好多年,但总体看回来,功能还是非常单薄,只能处理一对一关系的数据结构(可能未深入学习了解全面,有不对的地方请指正)。
在Excel催化剂的报表结构数据源转换标准数据源功能中,实现的效果是可以满足一对多的数据源,也是最为常见的订单、发货单、采购单等样式,符合实际的业务场景。
由Word直接转为Excel,数据到了Excel环境,在Excel催化剂过往的大量文本处理、格式处理、数据转换的功能支持下,比起Doc2Xls很机械地作一些简单配置,必然要通用强大得多。
Excel环境下采集指定内容及转换的功能大概会有以下几个大的功能支持,日后有好的示例将通过视频的方式给大家展示其强大及灵活之处。
同样地配合之前所提到的场景,对Word中的表格数据,进行额外的提取操作,方便数据更合理地被Excel环境所识别和提取到。一个表格占用一个工作表,若是规范性的文档,表格结构一致,位置顺序一致,将非常方便将Word的数据输出到Excel中重新利用。
此功能个人理解,仅仅用于数据保护和数据查阅需要,可能的场景只是手中大量的Word文档,想一次性转换为Pdf格式,Word的原生功能可以轻松对Word文档转Pdf,只是一次只转换一个文档,本功能也只是调用Word的转换接口,进行循环批量操作而已。
和第四点完全一致的场景,功能实现也没特别之处,仍然是内部原生功能即可完成。
基于前期的网页采集功能的开发,将Word转换为Html,就比较有场景需求了,若在前面第3点上直接转Xlsx文件,不能很好地拿到想要的数据(会丢失一些格式、标题、层级等信息或字段名和内容不分离等问题),将其转换为Html,再使用xPath的提取方式来重新提取,未尝不是一个非常好的方式,类似使用网页采集的原理,采集一些结构化的数据。
同时另一刚需场景为,可以轻松地提取到Word里面的图片,转换成Html后,图片将会在一个文件夹中存放,更多的技能是如何将这些文件夹里的无意义的命名图片,重新快速地进行筛选,拿到自己最终所需的图片子集。
在此给出大概的操作步骤及用到的功能:
Excel文件结构,类似数据库结构,有多个工作表,所以更科学的转换方式是按指定工作表转换,此功能也在过往的功能中得以实现,详见文章:
源头没摆正,最终衍生出大量稀奇古怪的各种神操作,当然文件转换过程,也必然很大原因归咎于没有规范科学的数据管理,没有树立科学的数据管理方法论,最终只能是无穷无尽地各种问题各种低效。
Excel催化剂倡导,从源头中处理,正确地理解好数据源与报表的两者关系,并在实际工作中加以应用,将减少非常多这些文件转换的工作。
还是那句话,你足够优秀,但你不能阻碍你的队友拖你大大的后腿,此篇一系列的转换功能,相信每个人都有不同程度的使用机会。
文字太苍白,后续有机会将以视频的方式给大家演示其威力所在。欢迎提供脱敏的原始示例数据,以便更有针对性地讲解。
个人永久性免费-Excel催化剂功能第115波-word、pdf、Excel、ppt、html等文件互转
标签:pdf转word 自己 步骤 自己的 word2013 缺陷 加载宏 占用 解决问题
原文地址:https://www.cnblogs.com/ExcelCuiHuaJi/p/12133123.html