标签:指定 keep tab 分布式 -- schema 压力 线程 简单
随着微服务这种架构的兴起,我们应用从一个完整的大的应用,切分为很多可以独立提供服务的小应用。每个应用都有独立的数据库。

数据的切分分为两种:
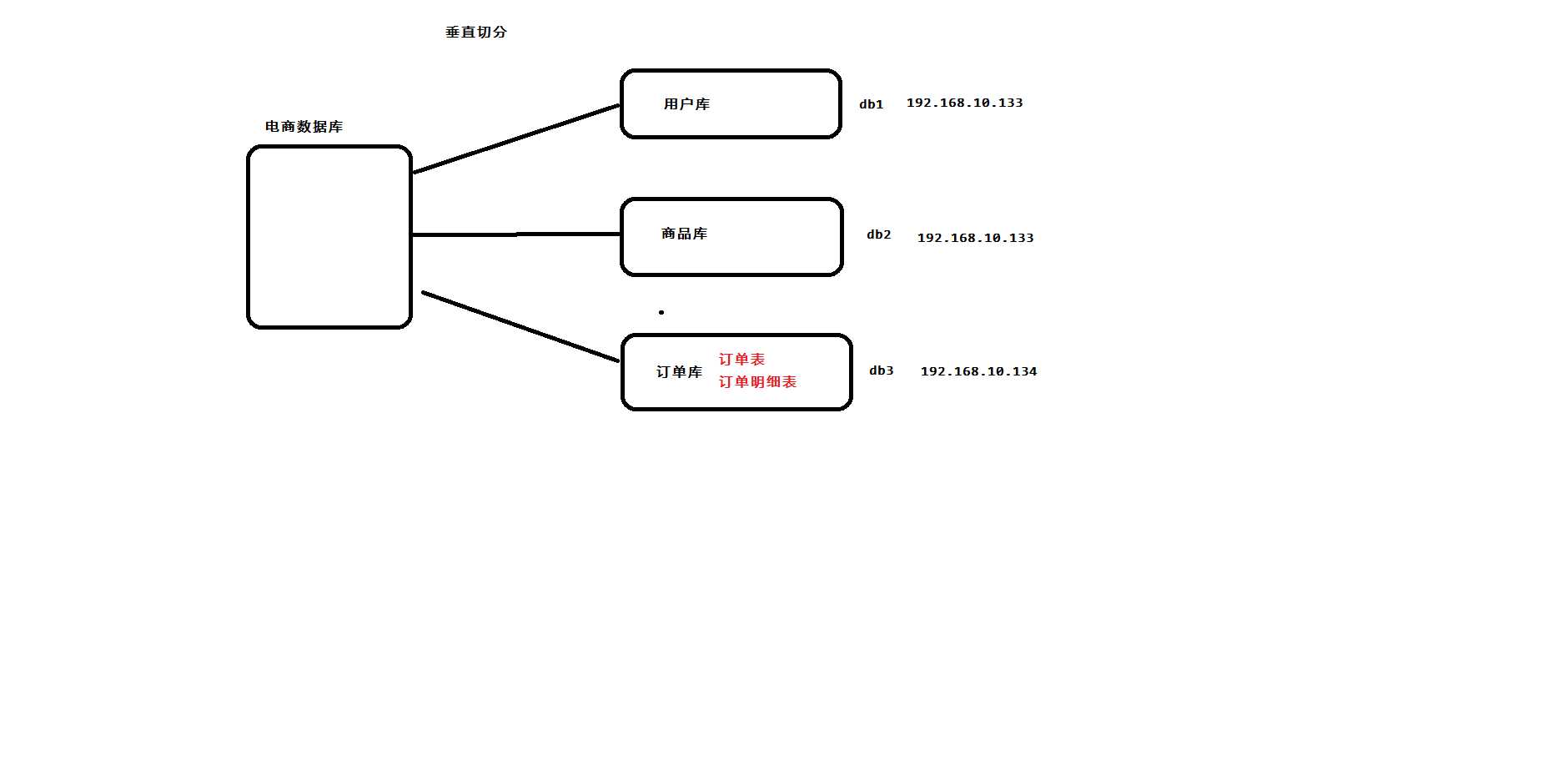
垂直切分:按照业务模块进行切分,将不同模块的表切分到不同的数据库中。
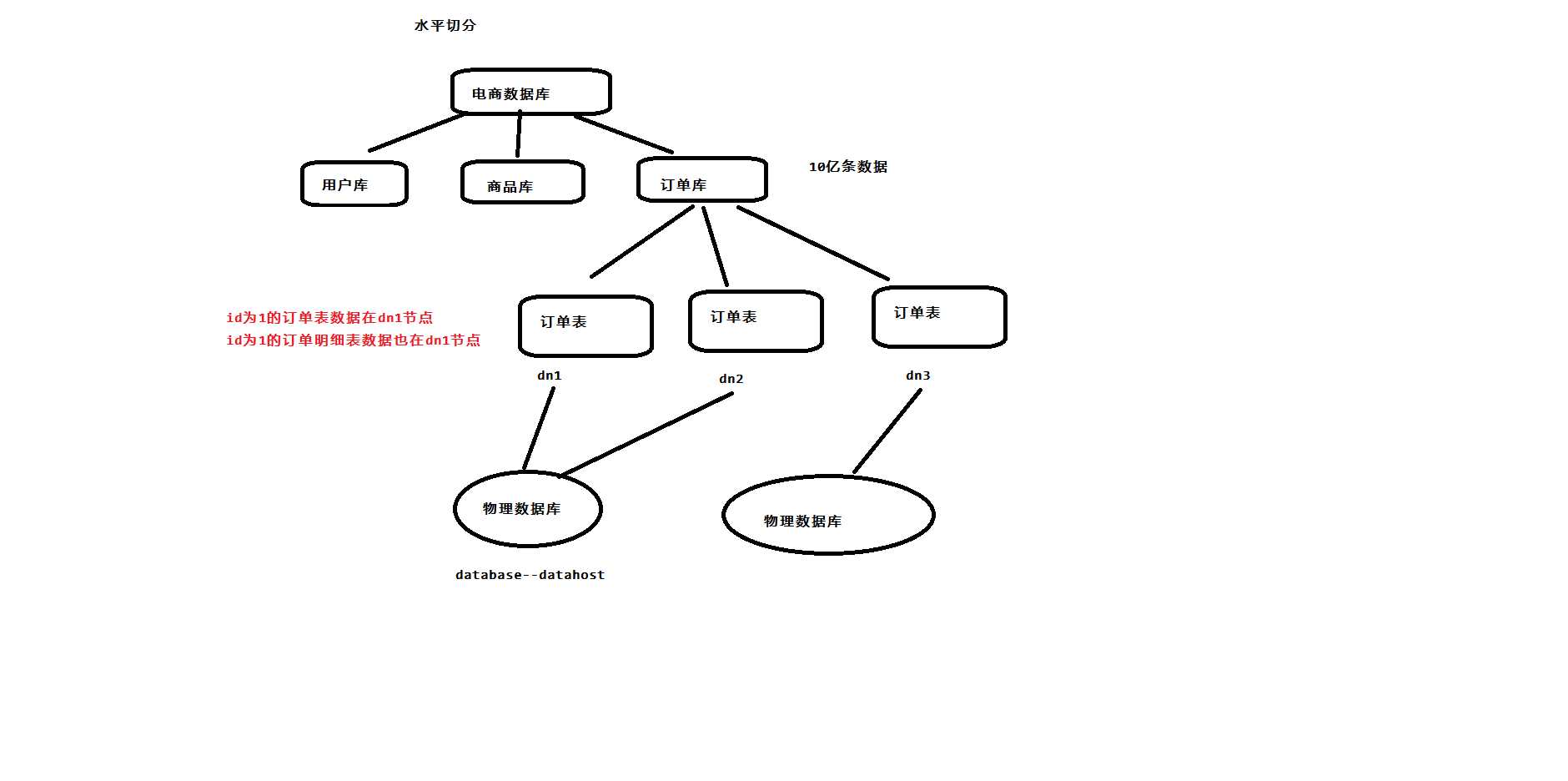
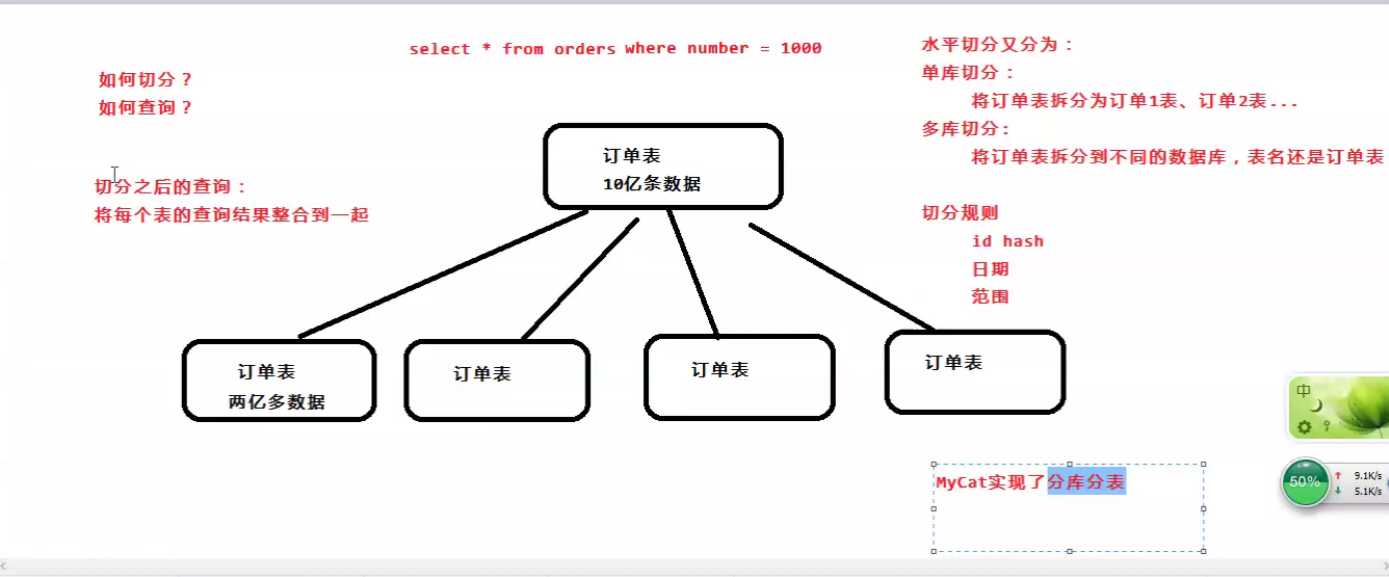
水平切分:将一张大表按照一定的切分规则,按照行切分到不同的表或者不同的库中。
网站链接:http://www.mycat.io/
·一个彻底开源的,面向企业应用开发的“大数据库集群”
·支持事务、ACID、可以替代Mysql的加强版数据库
·一个可以视为“Mysql”集群的企业级数据库,用来替代昂贵的Oracle集群
·一个融合内存缓存技术、Nosql技术、HDFS大数据的新型SQL Server
·结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
·一个新颖的数据库中间件产品
MyCAT的目标是:低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
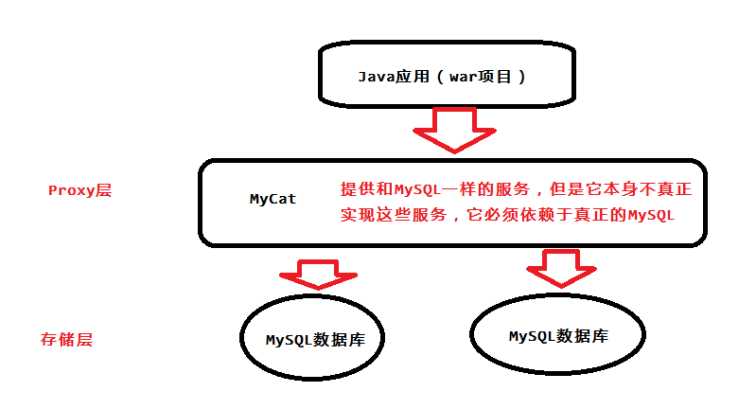
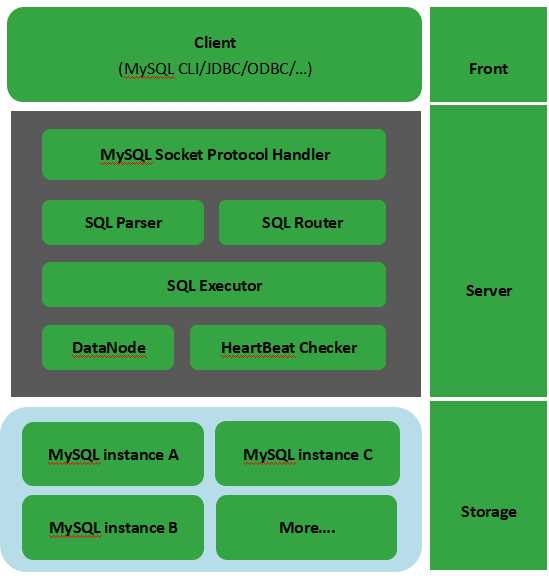
Schema:由它指定逻辑数据库
Table:逻辑表
DataNode:真正存储节点
DataHost:真正的数据库主机
如图所示:MyCAT使用Mysql的通讯协议模拟成了一个Mysql服务器,并建立了完整的Schema(数据库)、Table (数据表)、User(用户)的逻辑模型,并将这套逻辑模型映射到后端的存储节点DataNode(MySQL Instance)上的真实物理库中,这样一来,所有能使用Mysql的客户端以及编程语言都能将MyCAT当成是Mysql Server来使用,不必开发新的客户端协议。
跨库join问题
* 通过业务分析,将不同库的join查询拆分成多个select
* 建立全局表(每个库都有一个相同的表)
* 冗余字段(不符合数据库三范式)
* E-R分片(将有关系的记录都存储到一个库中)
* 最多支持跨两张表跨库的join
分布式事务(弱事务)
* 强一致性事务(同步)
* 最终一致性事务(异步思想)
分布式主键
* redis incr命令
* 数据库(生成主键)
* UUID
* snowflake算法
MyCat的读写分离是建立在MySQL主从复制基础之上实现的。
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。对于MySQL来说,标准的读写分离是主从模式,一个写节点Master后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1-3个读节点的配置
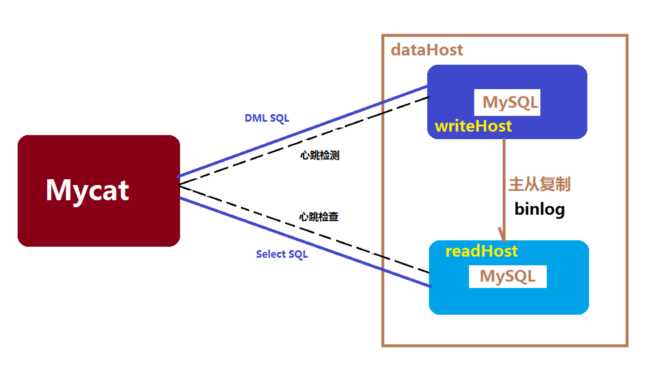
Mycat读写分离和自动切换机制,需要mysql的主从复制机制配合。
标签:指定 keep tab 分布式 -- schema 压力 线程 简单
原文地址:https://www.cnblogs.com/caocw/p/12134069.html