标签:span src dal https pil 首页 一个 result baidu
string = "Poythonpty" pat = "p.*?y" pat1 = "y.*" rst = re.match(pat, string, re.I) rst1 = re.match(pat1, string, re.I) print(rst) print(rst1)
打印结果:
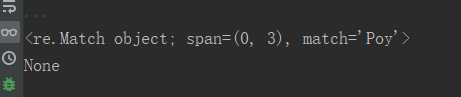
string = "Poythonpty" pat = "p.*?y" rst = re.search(pat, string, re.I) print(rst)
打印结果:

string = "PoythonptyohphyjkPdsy" pat = "p.*?y" rst = re.compile(pat, re.I).findall(string) print(rst)
打印结果:

实例1:.com和.cn网址
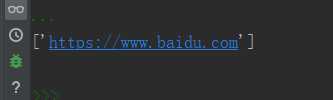
string = "< a helf=‘https://www.baidu.com‘>百度首页</a>" # pat = ‘http.*.com‘ pat = "[a-zA-Z]+:[^\s]*[.com|.cn]" # [a-zA-Z]+ :任意字符开头 [^\s]* :非空字符多次匹配 [.com|.cn] :原子表中包含.com或.cn result = re.compile(pat).findall(string) print(result)
打印结果:
实例2:匹配电话号码
string = "shhgy020-876380287jku0768-8937690789e132514512012" pat = "\d{4}-\d{7}|\d{3}-\d{8}|1\d{10}" rst = re.compile(pat).findall(string) print(rst)
打印结果:

标签:span src dal https pil 首页 一个 result baidu
原文地址:https://www.cnblogs.com/CesareZhang/p/12148853.html