标签:ring title item style 界面 图片 inf ext htm
完整源码链接: https://pan.baidu.com/s/1CWLXwlJGcq01jww8HXu3zg (加入了部分图形界面)
由于爬取结果都是英语的版本,所以需要翻译。
另外的两个txt文件是翻译,已经完成了大部分基础的翻译,如想需要添加可以按格式填写
运行效果:
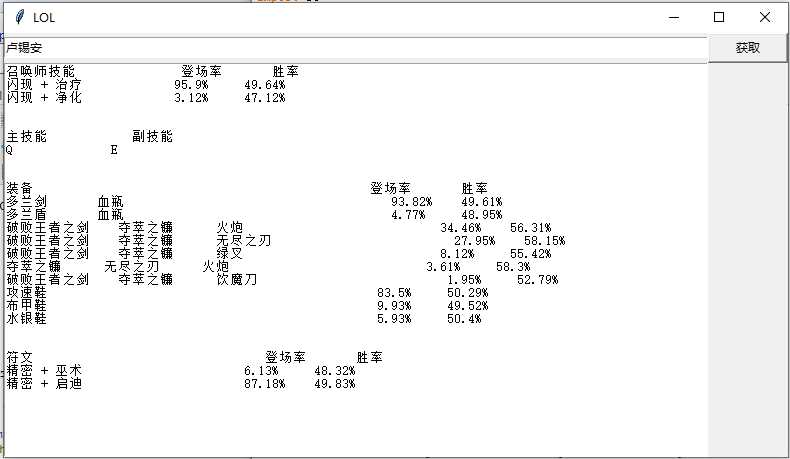
代码思路和步骤:
首先第一步,是获得所有英雄的名字和对应的url:
先观察网页的html,就能发现 <div>的data-champion-key属性中的就是英雄的名字,然后<a>的href属性就是英雄对应url
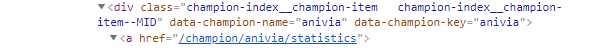
def weburl_get(): url=‘http://www.op.gg‘ addtion=‘/champion/statistics‘ r=requests.get(url+addtion,headers=headers) soup=bs4.BeautifulSoup(r.text,‘html.parser‘) #获取到英雄列表 championList=soup.find(‘div‘,class_=‘champion-index__champion-list‘) #单个英雄div格式匹配 pattern1=re.compile(‘(<div class="champion-index__champion-item .*?</div>)‘) champion_list=re.findall(pattern1,str(championList)) #将英雄名和网址作为一个字典 web_champion={} for champion in champion_list: champion_soup=bs4.BeautifulSoup(champion,‘html.parser‘) if (champion_soup.div)!=None and (champion_soup.div.a)!=None: web_champion[champion_soup.div[‘data-champion-key‘]]=url+champion_soup.div.a[‘href‘] return web_champion
然后第二步就是进入对应英雄的网页爬取相关数据:
先爬取召唤师技能,登场率和胜率

#获取召唤师技能和技能加点 skill_tbody=champion_main.table.tbody #得到第一个tbody也就是包含召唤师技能和加点 #正则匹配召唤师技能名字 skill_name=[] pattern2=re.compile(‘(<img .*?>)‘) user_skill=re.findall(pattern2,str(skill_tbody)) for skill in user_skill: skill_soup=bs4.BeautifulSoup(skill,‘html.parser‘) skill_name_soup=bs4.BeautifulSoup(skill_soup.img[‘title‘],‘html.parser‘) name=skill_name_soup.b.string if name in item.keys(): name=item[name] skill_name.append(name) #正则匹配召唤师技能的登场率和胜率 skill_rate=[] pattern3=re.compile(‘<strong>(.*?)</strong>‘) rate_ls=re.findall(pattern3,str(skill_tbody)) for rate in rate_ls: skill_rate.append(rate) #skill_rate为登场率胜率
然后爬取英雄技能加点

#获取技能加点 skillAdd=skill_tbody.find_next_siblings(‘tbody‘) pattern4=re.compile(r‘<td>([\s,\S]*?)</td>‘) skill_add=re.findall(pattern4,str(skillAdd)) skill_add=‘‘.join(skill_add) pattern5=re.compile(‘(\w*?)‘) skill_add=re.findall(pattern5,skill_add) skill_add=‘‘.join(skill_add) skill_master=[skill_add[3],skill_add[10]] #skill_master为主技能,副技能 # 1 2 3 4 5 6 7 8 10 11 12 14 15 索引对应的等级
再爬取装备

#获取装备信息 equipment_tbody=champion_text.find_next_siblings(‘table‘)[0].tbody equipment=[] pattern6=re.compile(r‘(<tr[\s,\S]*?</tr>)‘) equipment_text=re.findall(pattern6,str(equipment_tbody)) for text in equipment_text: tmp=[] #获取装备名 pattern6=re.compile(‘(<li class="champion-stats__list__item tip"[\s,\S]*?</li>)‘) tmp_equipment=re.findall(pattern6,text) ls=[] for i in tmp_equipment: temp=bs4.BeautifulSoup(i,‘html.parser‘) temp1=bs4.BeautifulSoup(temp.li[‘title‘],‘html.parser‘) if temp1.b.string in item.keys(): ls.append(item[temp1.b.string]) else: ls.append(temp1.b.string) tmp.append(ls) #获取登场率和胜率 pattern7=re.compile(r‘<strong>(.*?)</strong>‘) tmp.append(re.findall(pattern7,text)) equipment.append(tmp) #equipment格式为:[[[装备],[登场率,胜率]]]
最后爬取符文主系和副系

#获取符文信息 runes_tbody=champion_text.find_next_siblings(‘div‘)[0].tbody runes_tag=runes_tbody.tr.td.div runes_div=runes_tag.div.find_next_siblings(‘div‘) runes_div.append(runes_tag.div) rune_ls=[] for rune in runes_div: tmp=[] #匹配符文名 pattern8=re.compile(r‘<div class="champion-stats-summary-rune__name">(.*?)</div>‘) z=[] for i in re.findall(pattern8,str(rune.a)): s=i.split(‘ + ‘) if s[0] in item.keys(): s[0]=item[s[0]] if s[1] in item.keys(): s[1]=item[s[1]] z=‘ + ‘.join(s) tmp.append(z) pattern9=re.compile(r‘<strong>(.*?)</strong>‘) tmp.append(re.findall(pattern9,str(rune.a))) pattern10=re.compile(r‘<span>(\d.*?)</span>‘) tmp.append(re.findall(pattern10,str(rune.a))) rune_ls.append(tmp) #rune_ls格式为[[[符文名],[登场率],[胜率]]]
标签:ring title item style 界面 图片 inf ext htm
原文地址:https://www.cnblogs.com/b1ing/p/12148755.html