标签:log 键值 lis 次方 jpeg 接口 soc 单链表 好的
记录Java容器中的常见概念和原理
参考:
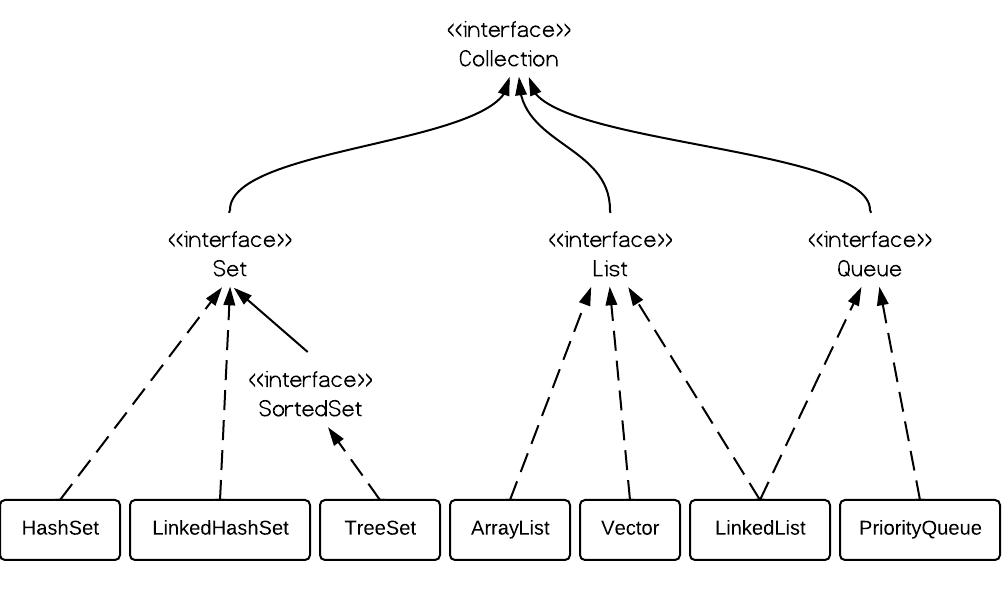
基础容器
ArrayList(动态数组)、LinkedList(带头结点的双向链表)
ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
ArrayList与LinkedList比较
- ArrayList是基于数组的实现,LinkedList是基于带头结点的双向循环链表的实现;
- ArrayList支持随机访问,LinkedList不支持;
- LinkedList可作队列和栈使用,实现了Dequeue接口,而ArrayList没有;
- ArrayList 寻址效率较高,插入/删除效率较低;LinkedList插入/删除效率较高,寻址效率较低
Fast-fail机制
Fail-Fast 是 Java 集合的一种错误检测机制,为了防止在某个线程在对Collection进行迭代时,其他线程对该Collection进行结构上的修改。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险,抛出 ConcurrentModificationException 异常。
Set (HashSet,LinkedHashSet,TreeSet)
Set不包含重复的元素,这是Set最大的特点,也是使用Set最主要的原因。常用到的Set实现有 HashSet,LinkedHashSet 和 TreeSet。一般地,如果需要一个访问快速的Set,你应该使用HashSet;当你需要一个排序的Set,你应该使用TreeSet;当你需要记录下插入时的顺序时,你应该使用LinedHashSet。
- HashSet:委托给HashMap进行实现,实现了Set接口
HashSet是采用hash表来实现的,其中的元素没有按顺序排列,add()、remove()以及contains()等方法都是复杂度为O(1)的方法。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
static final long serialVersionUID = -5024744406713321676L;
// 底层支持,HashMap可以代表一个HashMap,也可以代表一个LinkedHashMap
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object(); // 傀儡对象
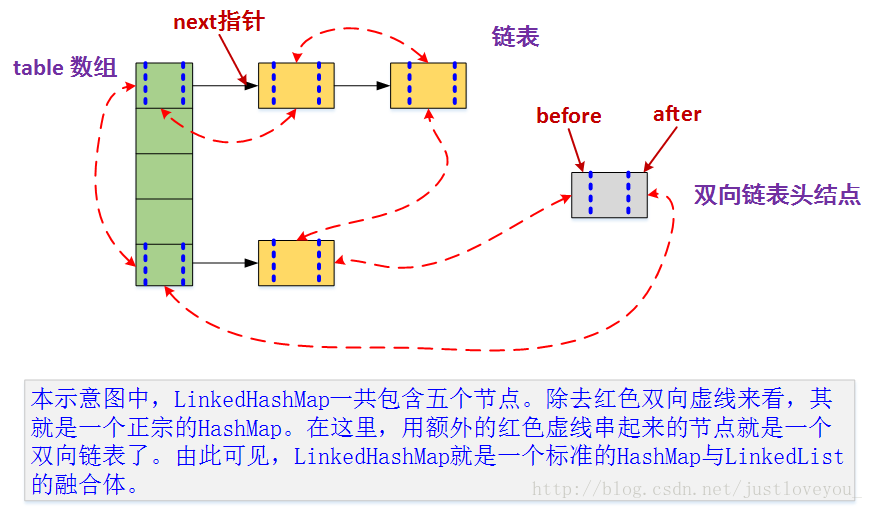
- LinkedHashSet:是HashSet的子类,被委托给HashMap的子类LinkedHashMap进行实现,实现了Set接口
LinkedHashSet继承于HashSet,利用下面的HashSet构造函数即可,注意到,其为包访问权限,专门供LinkedHashSet的构造函数调用。LinkedHashSet性能介于HashSet和TreeSet之间,是HashSet的子类,也是一个hash表,但是同时维护了一个双链表来记录插入的顺序,基本方法的复杂度为O(1)。
- TreeSet:委托给TreeMap(TreeMap实现了NavigableSet接口)进行实现,实现了NavigableSet接口(扩展的 SortedSet)
TreeSet是采用树结构实现(红黑树算法),元素是按顺序进行排列,但是add()、remove()以及contains()等方法都是复杂度为O(log (n))的方法,它还提供了一些方法来处理排序的set,如first()、 last()、 headSet()和 tailSet()等。此外,TreeSet不同于HashSet和LinkedHashSet,其所存储的元素必须是可排序的(元素实现Comparable接口或者传入Comparator),并且不能存放null值。
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m; // 底层支持
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
// 默认构造函数
public TreeSet() {
this(new TreeMap<E,Object>());
}
Map(HashMap, LinkedHashMap, TreeMap)
HashMap
TreeMap:红黑树的实现
- 排序二叉树 Vs. 红黑树
排序二叉树虽然可以快速检索,但在最坏的情况下:如果插入的节点集本身就是有序的,要么是由小到大排列,要么是由大到小排列,那么最后得到的排序二叉树将变成链表:所有节点只有左节点(如果插入节点集本身是大到小排列);或所有节点只有右节点(如果插入节点集本身是小到大排列)。在这种情况下,排序二叉树就变成了普通链表,其检索效率就会很差。
- 红黑树
为了改变排序二叉树存在的不足,Rudolf Bayer 与 1972 年发明了另一种改进后的排序二叉树:红黑树,他将这种排序二叉树称为“对称二叉 B 树”,而红黑树这个名字则由 Leo J. Guibas 和 Robert Sedgewick 于 1978 年首次提出。
红黑树是一个更高效的检索二叉树,因此常常用来实现关联数组。典型地,JDK 提供的集合类 TreeMap 本身就是一个红黑树的实现。红黑树在原有的排序二叉树增加了如下几个要求:
- 性质 1:每个节点要么是红色,要么是黑色;
- 性质 2:根节点永远是黑色的;
- 性质 3:所有的叶节点都是空节点(即 null),并且是黑色的;
- 性质 4:每个红色节点的两个子节点都是黑色(从每个叶子到根的路径上不会有两个连续的红色节点);
- 性质 5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
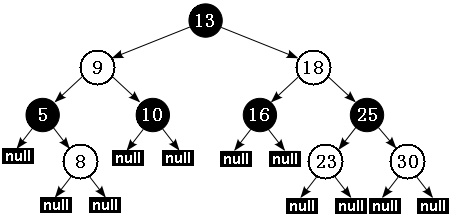
- 红黑树的性质
上面的性质3中指出:红黑树的每个叶子节点都是空节点,而且并叶子节点都是黑色。但 Java 实现的红黑树将使用null来代表空节点,因此遍历红黑树时将看不到黑色的叶子节点,反而看到每个叶子节点都是红色的。根据性质 5,红黑树从根节点到每个叶子节点的路径都包含相同数量的黑色节点,因此从根节点到叶子节点的路径中包含的黑色节点数被称为树的“黑色高度(black-height)”。性质 4 则保证了从根节点到叶子节点的最长路径的长度不会超过任何其他路径的两倍。
假如有一棵黑色高度为 3 的红黑树:从根节点到叶节点的最短路径长度是 2,该路径上全是黑色节点(黑节点 - 黑节点 - 黑节点)。最长路径也只可能为 4,在每个黑色节点之间插入一个红色节点(黑节点 - 红节点 - 黑节点 - 红节点 - 黑节点),性质 4 保证绝不可能插入更多的红色节点。由此可见,红黑树中最长路径就是一条红黑交替的路径。由此我们可以得出结论:对于给定的黑色高度为 N 的红黑树,从根到叶子节点的最短路径长度为 N-1,最长路径长度为 2 * (N-1)。
- 红黑树的查找、插入与删除操作
由于红黑树只是一个特殊的排序二叉树,因此对红黑树上的只读操作与普通排序二叉树上的只读操作完全相同,只是红黑树保持了大致平衡,因此检索性能比排序二叉树要好很多。但在红黑树上进行插入操作和删除操作会导致树不再符合红黑树的特征,因此插入操作和删除操作都需要进行一定的维护,以保证插入节点、删除节点后的树依然是红黑树。
- 红黑树和平衡二叉树
我们知道,在AVL树中,任何节点的两个子树的最大高度差为1,所以它也被称为高度平衡树;而红黑树并不追求 完全平衡,它只要求大致地达到平衡要求,降低了对旋转的要求,从而提高了性能。实际上,由于红黑树的设计,任何不平衡都会在三次旋转之内解决。
红黑树能够以O(log2 n) 的时间复杂度进行搜索、插入、删除操作。此外,由于它的设计,任何不平衡都会在三次旋转之内解决。当然,还有一些更好的,但实现起来更复杂的数据结构,能够做到一步旋转之内达到平衡,但红黑树能够给我们一个比较“便宜”的解决方案。红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高。
红黑树并不是真正的平衡二叉树,但在实际应用中,红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高。
排序二叉树的深度直接影响了检索的性能,正如前面指出,当插入节点本身就是由小到大排列时,排序二叉树将变成一个链表,这种排序二叉树的检索性能最低:N 个节点的二叉树深度就是 N-1。
红黑树通过上面这种限制来保证它大致是平衡的——因为红黑树的高度不会无限增高,这样保证红黑树在最坏情况下都是高效的,不会出现普通排序二叉树的情况。
容器中判断两个对象是否相等的步骤
- 判断两个对象的hashCode是否相等:如果不相等,认为两个对象也不相等,完毕;如果相等,转入2);
- 判断两个对象用equals运算是否相等:如果不相等,认为两个对象也不相等;如果相等,认为两个对象相等。
同步容器
主要参考:https://github.com/wangzhiwubigdata/God-Of-BigData#%E4%B8%89Java%E5%B9%B6%E5%8F%91%E5%AE%B9%E5%99%A8
- List和Set
JUC(java.util.concurrent)集合包中的List和Set实现类包括: CopyOnWriteArrayList CopyOnWriteArraySet ConcurrentSkipListSet
- CopyOnWriteArrayList相当于线程安全的ArrayList,它实现了List接口。CopyOnWriteArrayList是支持高并发的。
- CopyOnWriteArraySet相当于线程安全的HashSet,它继承于AbstractSet类。CopyOnWriteArraySet内部包含一个CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。
- Map
JUC集合包中Map的实现类包括: ConcurrentHashMap和ConcurrentSkipListMap。
- ConcurrentHashMap是线程安全的哈希表(相当于线程安全的HashMap);它继承于AbstractMap类,并且实现ConcurrentMap接口。ConcurrentHashMap是通过“锁分段”来实现的,它支持并发。
- ConcurrentSkipListMap是线程安全的有序的哈希表(相当于线程安全的TreeMap); 它继承于AbstractMap类,并且实现ConcurrentNavigableMap接口。ConcurrentSkipListMap是通过“跳表”来实现的,它支持并发。
- ConcurrentSkipListSet是线程安全的有序的集合(相当于线程安全的TreeSet);它继承于AbstractSet,并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,它也支持并发。
JUC集合包中Map的实现类包括: ConcurrentHashMap和ConcurrentSkipListMap。
- Queue
JUC集合包中Queue的实现类包括: ArrayBlockingQueue, LinkedBlockingQueue, LinkedBlockingDeque, ConcurrentLinkedQueue和ConcurrentLinkedDeque。
- ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列。
- LinkedBlockingQueue是单向链表实现的(指定大小)阻塞队列,该队列按 FIFO(先进先出)排序元素。
- LinkedBlockingDeque是双向链表实现的(指定大小)双向并发阻塞队列,该阻塞队列同时支持FIFO和FILO两种操作方式。
- ConcurrentLinkedQueue是单向链表实现的无界队列,该队列按 FIFO(先进先出)排序元素。
- ConcurrentLinkedDeque是双向链表实现的无界队列,该队列同时支持FIFO和FILO两种操作方式。
CopyOnWrite
CopyOnWrite 容器即写时复制的容器,从JDK1.5开始,Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器 —— CopyOnWriteArrayList 和 CopyOnWriteArraySet,它们适用于 读操作远多于写操作 的并发场景中。关于写时复制容器,通俗的理解是,当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是,我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以,CopyOnWrite容器也是一种 读写分离思想,读和写不同的容器。写时复制容器也存在一些缺点,比如:
- 容器对象的复制需要一定的开销,如果对象占用内存过大,可能造成频繁的YoungGC和Full GC,对内存的消耗太大;
- CopyOnWriteArrayList不能保证数据严格的实时一致性,只能保证最终一致性。
LinkedBlockingQueue
LinkedBlockingQueue是一个单向链表实现的阻塞队列。该队列按 FIFO(先进先出)排序元素,新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。
此外,LinkedBlockingQueue还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。
- LinkedBlockingQueue继承于AbstractQueue,它本质上是一个FIFO(先进先出)的队列。
- LinkedBlockingQueue实现了BlockingQueue接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。
- LinkedBlockingQueue是通过单链表实现的: (01) head是链表的表头。取出数据时,都是从表头head处插入。 (02) last是链表的表尾。新增数据时,都是从表尾last处插入。(03) count是链表的实际大小,即当前链表中包含的节点个数。(04) capacity是列表的容量,它是在创建链表时指定的。 (05) putLock是插入锁,takeLock是取出锁;notEmpty是“非空条件”,notFull是“未满条件”。通过它们对链表进行并发控制。 LinkedBlockingQueue在实现“多线程对竞争资源的互斥访问”时,对于“插入”和“取出(删除)”操作分别使用了不同的锁。对于插入操作,通过“插入锁putLock”进行同步;对于取出操作,通过“取出锁takeLock”进行同步。 此外,插入锁putLock和“非满条件notFull”相关联,取出锁takeLock和“非空条件notEmpty”相关联。通过notFull和notEmpty更细腻的控制锁。
LinkedBlockingDeque
LinkedBlockingDeque是双向链表实现的双向并发阻塞队列。该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除);并且,该阻塞队列是支持线程安全。
此外,LinkedBlockingDeque还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。
- LinkedBlockingDeque继承于AbstractQueue,它本质上是一个支持FIFO和FILO的双向的队列。
- LinkedBlockingDeque实现了BlockingDeque接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。
- LinkedBlockingDeque是通过双向链表实现的。
- first是双向链表的表头, last是双向链表的表尾,count是LinkedBlockingDeque的实际大小,即双向链表中当前节点个数,capacity是LinkedBlockingDeque的容量,它是在创建LinkedBlockingDeque时指定的
- lock是控制对LinkedBlockingDeque的互斥锁,当多个线程竞争同时访问LinkedBlockingDeque时,某线程获取到了互斥锁lock,其它线程则需要阻塞等待,直到该线程释放lock,其它线程才有机会获取lock从而获取cpu执行权。
- notEmpty和notFull分别是“非空条件”和“未满条件”。通过它们能够更加细腻进行并发控制。
CopyOnWriteArraySet
CopyOnWriteArrayList
ConcurrentSkipListSet
ConcurrentSkipListMap
ConcurrentLinkedQueue
ConcurrentHashMap
ArrayBlockingQueue
Java容器的常见问题
标签:log 键值 lis 次方 jpeg 接口 soc 单链表 好的
原文地址:https://www.cnblogs.com/xlsryj/p/12149669.html