标签:jpg ima 情况 data 技术 info article 信息 存储引擎
Mysql加快数据查找使用B-Tree数据结构存储索引数据,InnoDB存储引擎实际使用B+Tree。下面首先介绍下B-Tree和B+Tree的区别:
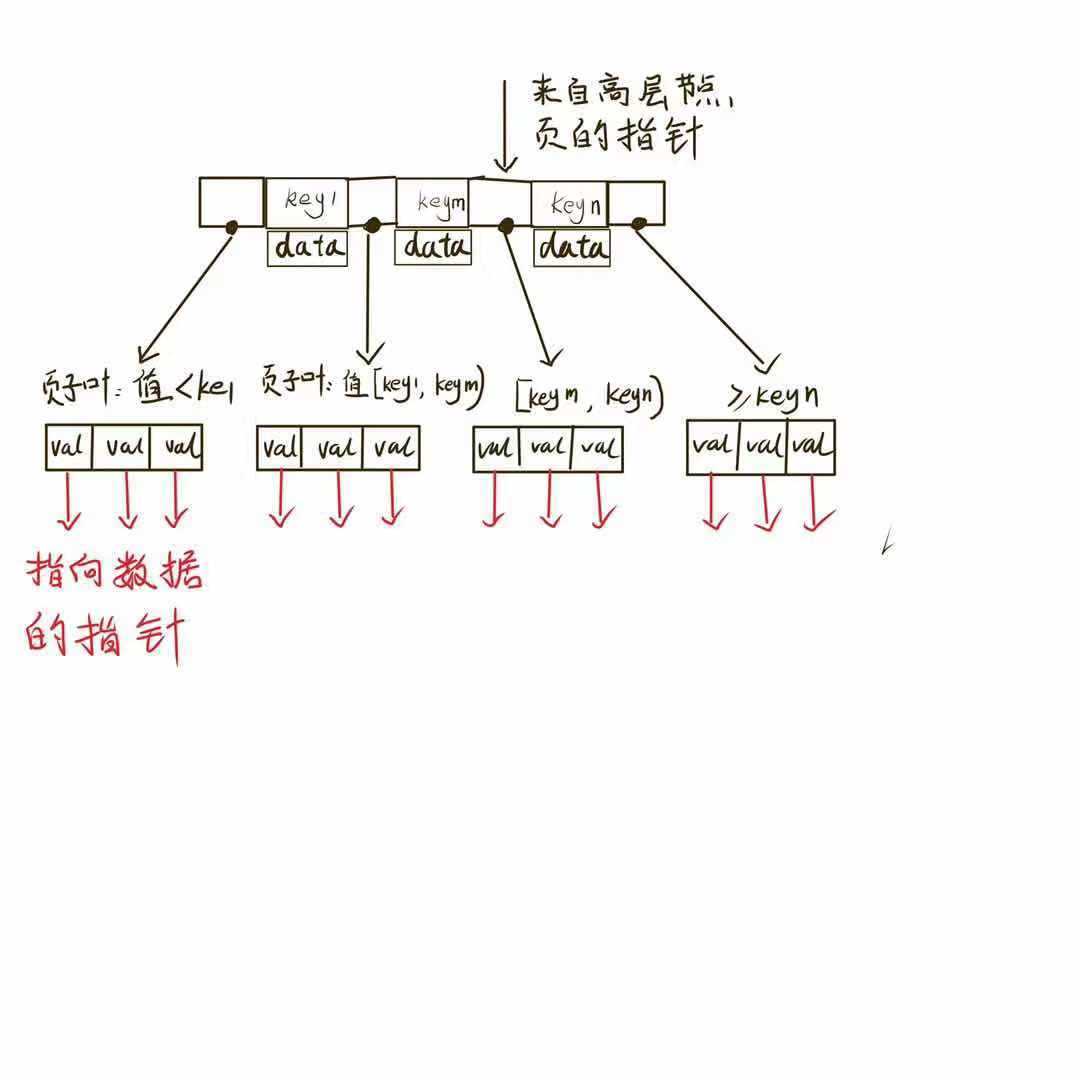
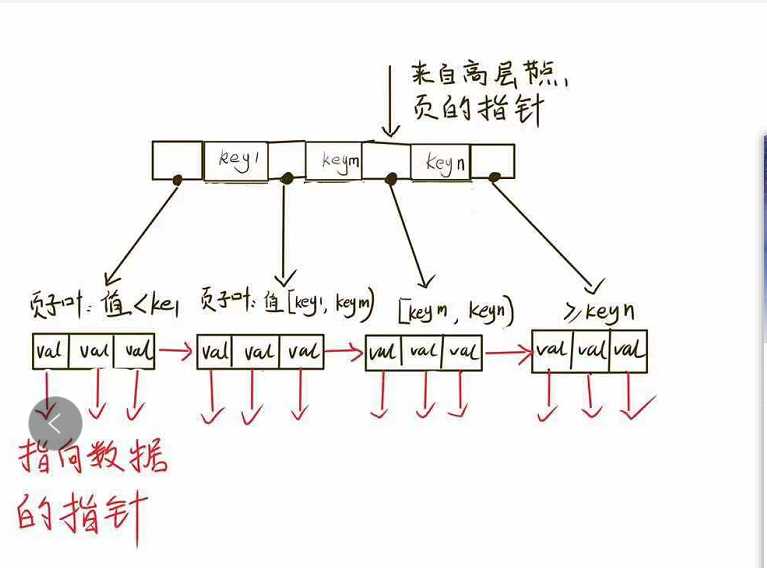
非叶子节点存储索引关键字,叶子节点指针指向的是被索引的数据。节点槽中存放了指向子节点的指针(可以理解为两个关键字之间),存储引擎根据这些指针向下层查找。通过比较节点页的值和要查找的值可以找到合适的指针进入下层子节点,这些指针实际上定义了子节点页中值的上限和下限。
1)B-Tree非叶子节点不仅存储索引关键字还保存除关键字外的其他字段信息,而B+Tree非叶子节点只保存索引关键字。
2) B+Tree叶子每个叶子节点保存了指向下一叶子节点的指针(链表串联),而B-Tree没有。
扩展:MySQL的InnoDB引擎索引要使用B+树而不是B树
(因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出)
指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
看过一篇比较好的博客文章介绍的很清晰:https://www.seoxiehui.cn/article-155967-1.html )
标签:jpg ima 情况 data 技术 info article 信息 存储引擎
原文地址:https://www.cnblogs.com/learn-ontheway/p/12150429.html