标签:获取 接口 数字 aci 注意 参考 传参 扫描 使用方法
我们在做接口自动化的时候,处理接口依赖的相关数据时,通常会使用正则表达式来进行提取相关的数据,今天在这边和大家聊聊如何在python中使用正则表达式。在python使用正则表达式,可以使用官方库re来实现
在python中使用正则表达式,需要用到re模块来进行操作,这边给大家介绍几个re模块中常用的方法。
参数说明:接收两个参数,
re.match尝试从字符串的起始位置匹配一个模式,匹配成功 返回的是一个匹配对象(这个对象包含了我们匹配的信息),如果不是起始位置匹配成功的话,match()返回的就是空。

2、re.search方法
参数说明:接收两个参数,
re.search 扫描整个字符串并返回第一个成功的匹配。
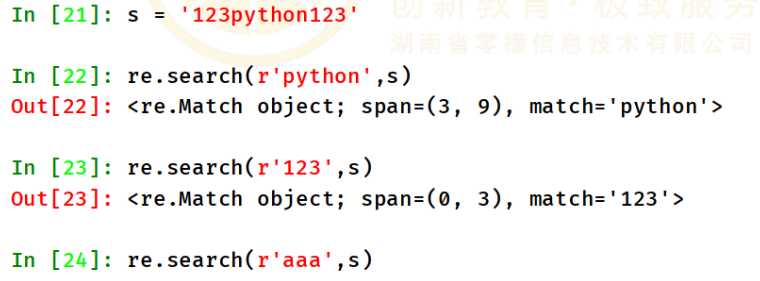
re.match与re.search的区别
参数说明:接收两个参数,
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
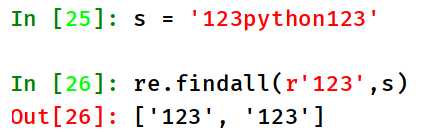
注意: match 和 search 是匹配一个结果, findall 匹配处所有符合规则的结果。
替换字符串中的某些字符,可以用正则表达式来匹配被选子串。
re.sub(pattern, repl, string, count=0 )
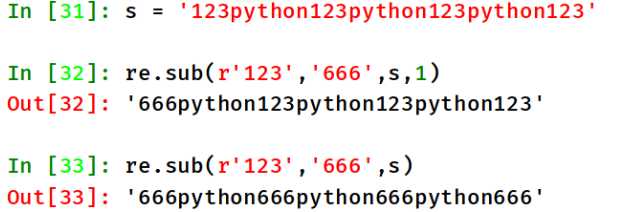
5、贪婪模式说明:
如下案例:有一个字符串s,我们需要在字符串中匹配3个以上的数字,字符串中数字有8个,贪婪模式会尽可能匹配更多字符,3个以上,8个也是3个以上,那么这里匹配的结果就是8个数字。
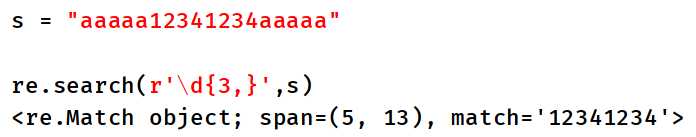
非贪婪模式:总是尝试匹配尽可能少的字符,在"*","?","+","{m,n}",{m,}后面加上?,可以关闭贪婪模式
关闭贪婪模式之后,尽可能获取更少的,如下,只获取到最前面的3个数值(规则时至少3个,非贪婪就是匹配最前面符合规则的3个数组)

关于re模块,更多的使用方法,本文不做过多的介绍,大家自行研究,谢谢!下面附上正则表达式的基本的匹配供大家参考
单字符:即表示一个单独的字符,比如匹配数字用\d ,匹配非数字使用\D,具体规则如下:
|
字符 |
功能 |
|
. |
匹配任意1个字符(\n除外) |
|
[7a ] |
匹配[ ]中列举的字符,这里就是匹配7或者a这两个字符其中的一个 |
|
\d |
匹配数字,即0-9 |
|
\D |
匹配非数字,即不是数字 |
|
\s |
匹配空白,即 空格,tab键 |
|
\S |
匹配非空白 |
|
\w |
匹配单词字符,即a-z、A-Z、0-9、_ |
|
\W |
匹配非单词字符 |
如果要匹配某个字符多次,就可以在字符后面加上数量进行表示,具体规则如下:
|
字符 |
功能 |
|
* |
匹配前一个字符出现0次或者无限次,即可有可无 |
|
+ |
匹配前一个字符出现1次或者无限次,即至少有1次 |
|
? |
匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
|
{m} |
匹配前一个字符出现m次 |
|
{m,} |
匹配前一个字符至少出现m次 |
|
{m,n} |
匹配前一个字符出现从m到n次 |
用来表示字符串或者单词的边界 如字符串开头,单词开头等
|
字符 |
功能 |
|
^ |
匹配字符串开头 |
|
$ |
匹配字符串结尾 |
|
\b |
匹配单词的边界 |
|
\B |
匹配非单词边界 |
对匹配的内容做分组处理
|
字符 |
功能 |
|
(aaa) |
将括号中字符作为一个分组 |
|
\number |
引用分组number匹配到的字符串 |
|
(?P<g1>) |
分组起别名为g1 |
|
(?P=g1) |
引用别名为g1分组匹配到的字符串 |
标签:获取 接口 数字 aci 注意 参考 传参 扫描 使用方法
原文地址:https://www.cnblogs.com/htx18/p/11749489.html