标签:算法 最小化 元组 and http 机器学习 播放 变化 com
原文地址:https://blog.csdn.net/yubei2155/article/details/79343942
Netflix大部分的推荐机制都是采用机器学习的算法。传统方式上,我们会收集一组用户如何使用我们服务的数据,然后在这组数据上采用一种新的机器学习算法。接下来我们会通过A/B测试的方式测试这个算法与当前的系统进行比较。A/B 测试通过一组随机的用户数据去测试新的算法是否比当前的系统更好。A组的成员会得到通过现在的系统生成的图片而B组会得到新的算法所生成的图片。如果B组的用户在Netflix有更高的转化率,那我们就会把这个新的算法推广到整个客户群。但有一点不好的是,这种方式会产生损失(Regret):许多用户在很长一段时间内无法得到这种更好的用户体验。下图展示了这一过程: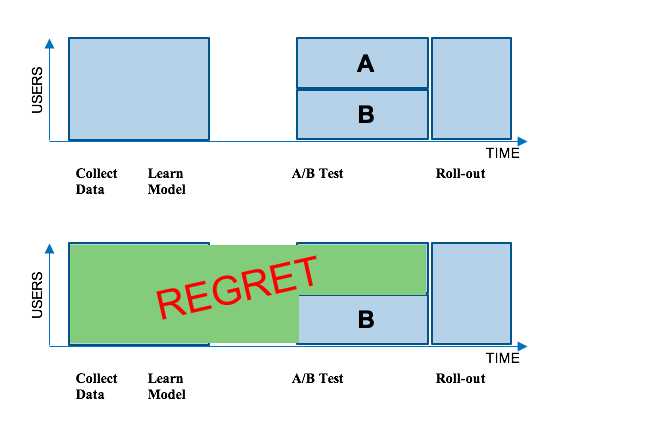
为了降低损失(Regret),我们不再采用批量机器学习的方式,而是考虑在线机器学习。针对配图的个性化定制,我们采用的线上学习框架是“上下文老虎JI”(contextual bandits)。相比于以前等着收集一整批次的数据,等着学习一个模型,然后等着一个A/B测试来得出结论,“上下文老虎JI”能针对每个用户和情境快速找出最优的个性化配图选择。简要地说,“上下文老虎JI”是一类在线学习算法,这类算法通过在一个变化的情况下不断将所学模型应用于每个用户情景的好处来平衡收集足够的数据去学习一个无偏模型的代价。在我们之前非个性化的图片筛选框架中,我们用的是“非上下文情境的老虎JI”(non-contextual bandits),这种方法在寻找最佳配图时不考虑上下文情境。而对于个性化来说,用户就是上下文情境,因为我们期望不同的用户对配图有不同的回应。
“上下文老虎JI”的一个重要属性是它们天生就能将损失(Regret)最小化。“上下文老虎JI”的训练数据是通过在学习模型的预测中注入受控的随机化变量获得的。随机化方案的复杂程度可以变化,从具有均匀随机性的简单ε贪婪公式(epsilon-greedy formulations)到能够根据模型的不确定性自适应地改变闭环方案。我们笼统地称之为数据探索(data exploration)。一个影片的所有备选配图数量和系统部署到的用户总体大小决定了数据探索策略的选择。有了这样的探索,我们需要记录关于每个配图选择的随机化的信息。这个记录允许我们修正偏斜的选择倾向,从而如下所述,用不偏倚的方式执行离线模型评估。
由于实际上有的用户的配图呈现选择可能并不会用那次预测中最好的图像,所以“上下文老虎JI”里的数据探索一般都是有一定代价的(Regret)。这一随机化对于用户体验(进而对于我们的指标)有怎样的影响呢?对于超过一亿用户来说,数据探索导致的损失(Regret)一般都很小,而且被隐式地分摊到了我们庞大用户群的每个用户,来帮助提供目录中的一小部分配图的反馈。这使得平均每个用户的数据探索代价微不足道,这对于选择“上下文老虎JI”来运转我们用户体验中的关键部分,是一个非常重要的考量。如果数据探索的代价很高,那用“上下文老虎JI”做随机化和数据探索就会不太合适。
在我们的线上探索方案中,我们获得的训练数据集记录了对于每个(用户,影片名,图片)元组,其对应的影片是否被播放。此外,我们还能够控制数据探索使得配图筛选结果不要改变得太过频繁。这使得特定的配图与用户是否播放影片之间的归因变得清晰。我们还通过关注用户参与的质量来仔细地确定每个观察值的标签,从而避免学习的模型推荐了“标题党”图片:那些诱使用户开始播放,但最终导致低质量参与(很快就关掉)的图片。
Netflix大部分的推荐机制都是采用机器学习的算法。传统方式上,我们会收集一组用户如何使用我们服务的数据,然后在这组数据上采用一种新的机器学习算法。接下来我们会通过A/B测试的方式测试这个算法与当前的系统进行比较。A/B 测试通过一组随机的用户数据去测试新的算法是否比当前的系统更好。A组的成员会得到通过现在的系统生成的图片而B组会得到新的算法所生成的图片。如果B组的用户在Netflix有更高的转化率,那我们就会把这个新的算法推广到整个客户群。但有一点不好的是,这种方式会产生损失(Regret):许多用户在很长一段时间内无法得到这种更好的用户体验。下图展示了这一过程: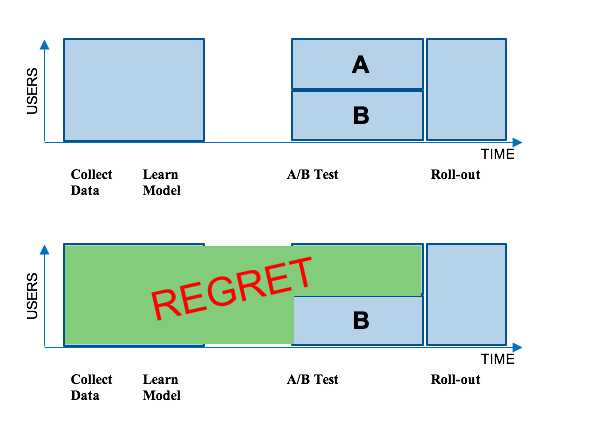
为了降低损失(Regret),我们不再采用批量机器学习的方式,而是考虑在线机器学习。针对配图的个性化定制,我们采用的线上学习框架是“上下文老虎JI”(contextual bandits)。相比于以前等着收集一整批次的数据,等着学习一个模型,然后等着一个A/B测试来得出结论,“上下文老虎JI”能针对每个用户和情境快速找出最优的个性化配图选择。简要地说,“上下文老虎JI”是一类在线学习算法,这类算法通过在一个变化的情况下不断将所学模型应用于每个用户情景的好处来平衡收集足够的数据去学习一个无偏模型的代价。在我们之前非个性化的图片筛选框架中,我们用的是“非上下文情境的老虎JI”(non-contextual bandits),这种方法在寻找最佳配图时不考虑上下文情境。而对于个性化来说,用户就是上下文情境,因为我们期望不同的用户对配图有不同的回应。
“上下文老虎JI”的一个重要属性是它们天生就能将损失(Regret)最小化。“上下文老虎JI”的训练数据是通过在学习模型的预测中注入受控的随机化变量获得的。随机化方案的复杂程度可以变化,从具有均匀随机性的简单ε贪婪公式(epsilon-greedy formulations)到能够根据模型的不确定性自适应地改变闭环方案。我们笼统地称之为数据探索(data exploration)。一个影片的所有备选配图数量和系统部署到的用户总体大小决定了数据探索策略的选择。有了这样的探索,我们需要记录关于每个配图选择的随机化的信息。这个记录允许我们修正偏斜的选择倾向,从而如下所述,用不偏倚的方式执行离线模型评估。
由于实际上有的用户的配图呈现选择可能并不会用那次预测中最好的图像,所以“上下文老虎JI”里的数据探索一般都是有一定代价的(Regret)。这一随机化对于用户体验(进而对于我们的指标)有怎样的影响呢?对于超过一亿用户来说,数据探索导致的损失(Regret)一般都很小,而且被隐式地分摊到了我们庞大用户群的每个用户,来帮助提供目录中的一小部分配图的反馈。这使得平均每个用户的数据探索代价微不足道,这对于选择“上下文老虎JI”来运转我们用户体验中的关键部分,是一个非常重要的考量。如果数据探索的代价很高,那用“上下文老虎JI”做随机化和数据探索就会不太合适。
在我们的线上探索方案中,我们获得的训练数据集记录了对于每个(用户,影片名,图片)元组,其对应的影片是否被播放。此外,我们还能够控制数据探索使得配图筛选结果不要改变得太过频繁。这使得特定的配图与用户是否播放影片之间的归因变得清晰。我们还通过关注用户参与的质量来仔细地确定每个观察值的标签,从而避免学习的模型推荐了“标题党”图片:那些诱使用户开始播放,但最终导致低质量参与(很快就关掉)的图片。
-------------------------------------------------------------------------------------------------------------------------------------------------
————————————————
版权声明:本文为CSDN博主「执著Duang」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yubei2155/article/details/79343942
标签:算法 最小化 元组 and http 机器学习 播放 变化 com
原文地址:https://www.cnblogs.com/boonya/p/12154240.html