标签:部分 try erro 图案 osi 导入 file read span
一、机器学习能做什么?
1、识别图像,比如可以通过训练得到模型,识别该张图片是否包含数字,是否是人像,是否是猫狗等。
2、识别文字,提取文本含义。
3、查找数值之间的关系。
二、iOS里面的机器学习
Create ML 可以与 Swift 和 macOS Playground 等您所熟悉的工具搭配使用,在 Mac 上创建和训练自定的机器学习模型。
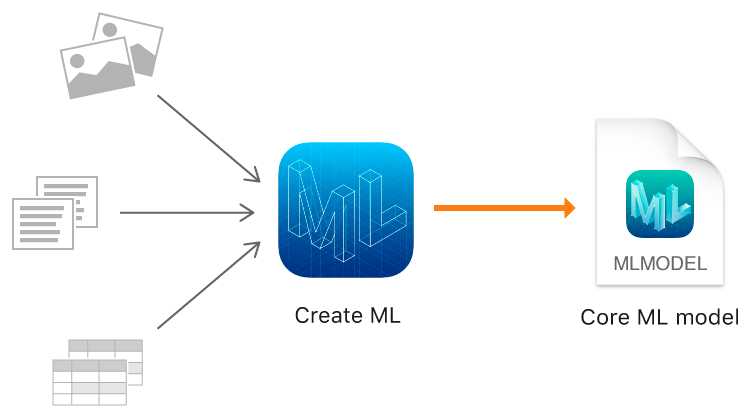
您可以通过向模型展示训练样本来训练模型识别图案。例如,您可以通过向模型展示大量不同犬类的图像来训练模型识别犬类。在完成模型训练后,您可使用模型之前未曾见过的数据来测试模型,并评估模型完成这个任务的表现情况。如果模型表现良好,就可以使用 Core ML 将它整合到 app 中。
最关键的一步就是要生成模型,通过特定的数据输入,指定输出格式来生成模型,不断的训练让识别率达到99%以上才可用于实际开发,否则误差将会很大。
我们先来看下文本筛选吧!开始吧!
三、创建文本分类器模型
选择创建的模型功能,这边我们先来创建一个识别影评的模型,判断当前这条影评是好评,差评还是中评。
怎么做呢?开始吧
1、收集文本数据,并导入到 MLDataTable (英文) 实例中。也就是创建你训练数据源。
举个栗子:一个 JSON 文件中包含您按情绪分类的影评。每个条目都包含 text 和 label 这样一对属性。这些属性值就是用来训练模型的输入样本。
[ { "text": "The movie was fantastic!", "label": "positive" }, { "text": "Very boring. Fell asleep.", "label": "negative" }, { "text": "It was just OK.", "label": "neutral" } ... ]
开始写代码了,创建一个playground文件,导入 CreateML 库,上代码
import CreateML //训练源地址 let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/path/to/read/data.json"))
注:得到的数据表包含两列,分别名为 text 和 label,这两列从 JSON 文件中的属性数据派生而来。列可以使用任意名称,只要对您有意义即可,因为您将会在其他方法中将列名用作参数。
2、准备数据和评估数据
用于训练模型的数据需要与用来评估模型的数据是不同的。
您可以使用 MLDataTable (英文) 的 randomSplit(by:seed:) 方法将数据拆分到两个表格中,一个用于训练,一个用于测试。
训练数据表包含大部分数据,测试数据表包含其余 10% - 20% 的数据。
let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5)
3、创建和训练文本分类器
使用训练数据表和列名创建 MLTextClassifier (英文) 实例。训练便会立即开始。
let sentimentClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label")
在训练期间,Create ML 会分离出一小部分训练数据,供在训练阶段用来验证模型的进度。
验证数据让训练过程能够使用模型未训练过的示例来衡量模型的表现情况。
根据验证准确性,训练算法可以调整模型内部的值,甚至能在准确性已达到足够高时停止训练过程。
由于拆分是随机的,因此每次训练模型时可能会得到不同的结果。
验证识别的准确性,用下面两个属性:
// Training accuracy as a percentage let trainingAccuracy = (1.0 - sentimentClassifier.trainingMetrics.classificationError) * 100 // Validation accuracy as a percentage let validationAccuracy = (1.0 - sentimentClassifier.validationMetrics.classificationError) * 100
4、评估分类器的准确性
使用新的句子对经过训练的模型进行测试,评估模型的表现情况。
然后将测试数据表传递给 evaluation(on:) 方法,这个方法会返回一个 MLClassifierMetrics 实例。
let evaluationMetrics = sentimentClassifier.evaluation(on: testingData)
let evaluationAccuracy = (1.0 - evaluationMetrics.classificationError) * 100注:如果模型准确率不理想,就要考虑加大训练数据源了,更多的提高准确率的方法我们下次再说。
5、存储模型
如果您对模型表现满意,就可以存储模型以便在 app 中使用了。
使用 write(to:metadata:) (英文) 方法将 Core ML 模型文件 (SentimentClassiifer.mlmodel) 写入磁盘。在 MLModelMetadata (英文) 实例中提供有关模型的任何信息,例如作者、版本或描述。
let metadata = MLModelMetadata(author: "John Appleseed", shortDescription: "A model trained to classify movie review sentiment", version: "1.0") try sentimentClassifier.write(to: URL(fileURLWithPath: "<#/path/to/save/SentimentClassifier.mlmodel#>"), metadata: metadata)
6、模型添加到APP,使用
在 Xcode 中打开 app 后,将 SentimentClassifier.mlmodel 文件拖到导航面板中。
Xcode 会编译模型并生成 SentimentClassifier 类,供在 app 中使用。
在 Xcode 中选择 SentimentClassifier.mlmodel 文件可以查看关于模型的更多信息。
import NaturalLanguage let sentimentPredictor = try NLModel(mlModel: SentimentClassifier().model) sentimentPredictor.predictedLabel(for: "It was the best I‘ve ever seen!")
先讲到这,对于模型数据源这块还有点疑惑,下次再讲吧。
标签:部分 try erro 图案 osi 导入 file read span
原文地址:https://www.cnblogs.com/qiyiyifan/p/12154324.html