标签:python path url 没有 word web ace import edit
需求:想要实现这样的功能:用户输入喜欢的电影名字,程序即可在电影天堂https://www.ygdy8.com爬取电影所对应的下载链接,并将下载链接打印出来
遇到的问题:获取磁力的链接中包含中文,打印出来后乱码
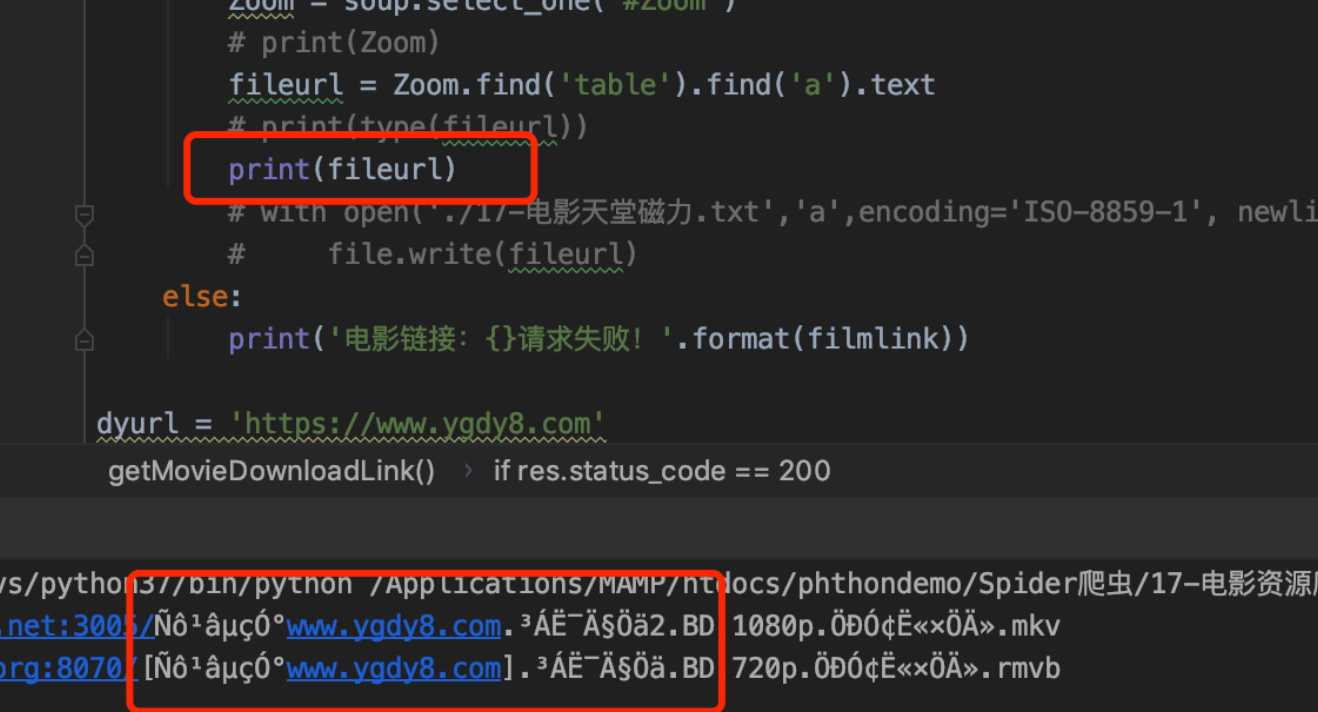
解决办法:手动指定编码方式:
if res.encoding == ‘ISO-8859-1‘: encodings = requests.utils.get_encodings_from_content(res.text) if encodings: encoding = encodings[0] else: encoding = res.apparent_encoding else: encoding = res.encoding encode_content = res.content.decode(encoding, ‘replace‘).encode(‘utf-8‘, ‘replace‘)
# 想要实现这样的功能:用户输入喜欢的电影名字,程序即可在电影天堂https://www.ygdy8.com爬取电影所对应的下载链接,并将下载链接打印出来 import requests from bs4 import BeautifulSoup from urllib.request import pathname2url # 为躲避反爬机制,伪装成浏览器的请求头 headers = {‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 OPR/65.0.3467.78 (Edition Baidu)‘} # 获取电影磁力链接 def getMovieDownloadLink(filmlink): res = requests.get(filmlink, headers=headers) if res.status_code == 200: # 请求后的内容中文乱码处理办法: # 当response编码是‘ISO-8859-1’,我们应该首先查找response header设置的编码;如果此编码不存在,查看返回的Html的header设置的编码 if res.encoding == ‘ISO-8859-1‘: encodings = requests.utils.get_encodings_from_content(res.text) if encodings: encoding = encodings[0] else: encoding = res.apparent_encoding else: encoding = res.encoding encode_content = res.content.decode(encoding, ‘replace‘).encode(‘utf-8‘, ‘replace‘) soup = BeautifulSoup(encode_content, ‘html.parser‘) Zoom = soup.select_one(‘#Zoom‘) fileurl = Zoom.find(‘table‘).find(‘a‘).text with open(‘./17-电影天堂磁力.txt‘,‘a‘, newline=‘‘) as file: file.write(fileurl + ‘\n‘) else: print(‘电影链接:{}请求失败!‘.format(filmlink)) def main(): dyurl = ‘https://www.ygdy8.com‘ # movie = input(‘请输入电影名称:‘) movie = ‘沉睡魔咒‘ movie = movie.encode(‘gbk‘) url = ‘http://s.ygdy8.com/plus/s0.php?typeid=1&keyword={0}‘.format(pathname2url(movie)) res = requests.get(url, headers=headers) if res.status_code == 200: htmltext = res.text soup = BeautifulSoup(htmltext, ‘html.parser‘) co_content8 = soup.find(‘div‘, class_=‘co_content8‘) tables = co_content8.find(‘ul‘).find_all(‘table‘) if len(tables) <= 0: print(‘没有找到相关的资源,可到站点上搜索 {0}‘.format(dyurl)) else: for table in tables: filmlink = dyurl + table.find(‘a‘)[‘href‘] getMovieDownloadLink(filmlink) else: print(‘请求失败!‘) main()
结果:

参考:
https://blog.csdn.net/guoxinian/article/details/82978067
http://blog.csdn.net/a491057947/article/details/47292923
http://docs.python-requests.org/en/latest/user/quickstart/#response-content
标签:python path url 没有 word web ace import edit
原文地址:https://www.cnblogs.com/KeenLeung/p/12160712.html