标签:需要 dig 字符串 存储 两种方法 image ima 限制 其他
Hash算法在应用中又称为指纹(fingerprint)或者摘要(digest)算法,是一种将任意长度的明文串映射为较短的数据串(hash值)的算法,目前的Hash算法主要是MD5系列算法与SHA系统算法
一个好的Hash算法需要具有四个特性,即正向快速 ,逆向困难,输入敏感 ,冲突避免
正向快速 :给定明文和 Hash 算法,在有限时间和有限资源内能计算得到 Hash 值
逆向困难:给定Hash 值,在有限时间内难以逆推出明文
输入敏感:原始输入信息发生任何改变,新产生的 Hash 值都应该出现很大不同
冲突避免:很难找到两段内容不同的明文,使得它们的 Hash 值一致 。冲突避免也叫做抗碰撞性,分为强抗碰撞性与弱抗碰撞性。如果给定明文前提下,无法找到与之碰撞的其他明文,则算法具有弱抗碰撞性;如果无法找到任意两个Hash 碰撞的明文,则称算法具有强抗碰撞性
由于Hash可以将任意内容映射到一个固定长度的字符串,而且不同内容映射到相同串的概率很低 。因此,这就构成了一个很好的“内容→索引”的生成关系。对于给定的内容与存储数组,可以通过构造合适的Hash函数,使内容计算得出的Hash值不超过数组的大小,从而实现快速的基于内容的查找,用以判断"某个元素是否在一个集合内"的问题。但是将映射的Hash值限制在数组大小的范围内,会造成大量的Hash冲突,从而导致性能的急速下降,所以人们基于Hash算法设计出了布隆过滤器
布隆过滤器采用了多个 Hash 函数来提高空间利用率。 对同一个给定输入来说,多个Hash函数计算出多个地址,分别在数组的这些地址上标记为1,进行查找时,进行同样的计算过程,并查看对应元素,如果都为1,则说明较大概率是存在该输入,如下图所示,根据内容执行Hash1,Hash2,HashK等函数,计算出h1,h2,hk等位置,如果这些位置全部是1,则说明abc@gmail.com有很大概率存在
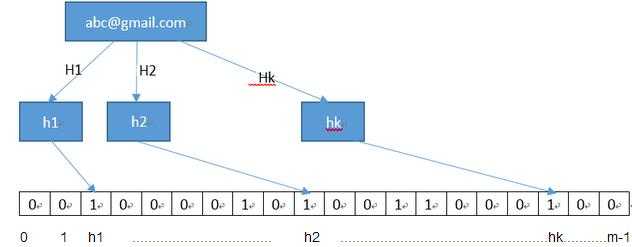
之所以说有很大概率,是因为不管是单一的Hash算法还是布隆过滤器,其思想是一致的,都是基于内容的编码,但是由于存储限制,都可能存在冲突,即两种方法都可能存在误报的问题,同时都不会存在错报的问题。不过在应用中布隆过滤器的误报率远低于单一Hash算法的误报率
标签:需要 dig 字符串 存储 两种方法 image ima 限制 其他
原文地址:https://www.cnblogs.com/yytxdy/p/12168019.html