移动GPU渲染原理的流派——IMR、TBR及TBDR
移动GPU相对桌面级的GPU只能算是未长大的小孩子,虽然小孩子在某些场合也能比成人更有优势(比如杂技、柔术之类的表演),但在力量上还是有先天的差别,主要表现在理论性能和带宽上。
与桌面GPU动辄256bit甚至384bit的位宽、1.2-1.5GHz的高频显存相比,移动GPU不仅要和CPU共享内存带宽,而且普遍使用的是双32bit位宽、LPDDR2-800或1066左右的内存系统,总带宽普遍在10GB/s以内,悲催的Tegra 3使用的还是单通道内存模式,搭配DDR3L的带宽不过6.4GB/s。
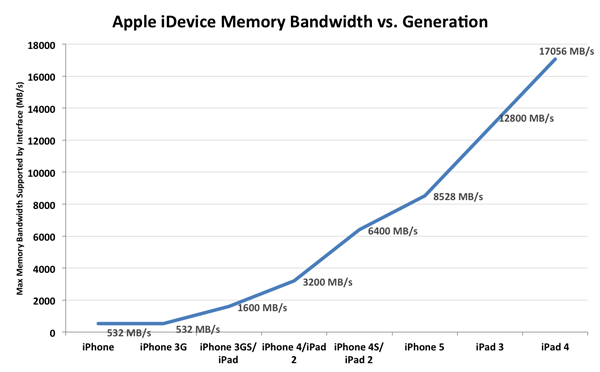
目前GPU性能最强大的iPad 4带宽也不过17GB/s(图片源于Anandtech)
移动处理器中内存带宽最高的是iPad 3/4,因为他们使用Retina屏幕,2048x1536的高分辨率对GPU带宽要求更高,不过就算是这两款产品,17GB/s的带宽与PC显卡上动辄200GB/s以上的带宽相比还是小儿科了。
没有高带宽就没有大容量纹理数据,也就不会有高画质。尽管带宽不是制约移动GPU发展的唯一因素,但是在目前的限制下,移动GPU厂商关心的头等大事就是如何在尽可能小的带宽需求下提升GPU性能及画质,前面介绍的纹理压缩是一个方法,还有一种就是使用不同的渲染方式,主要有IMR、TBR及TBDR等。
伤不起的“立即渲染模式”——IMR

IMR(Immediate Mode Rendering)就如字面意思一样——提交的每个渲染要求都会立即开始,这是一种简单而又粗暴的思路,优点缺点都非常明显,如果不用为性能担忧,这种方式会很省事,但是IMR的渲染实行的是无差别对待,那些遮蔽处理的部分依然会被渲染处理器,这也导致无意义的读写操作更多,浪费了大量性能和带宽。
总之,IMR这种渲染方式在移动GPU上的评价只能是“负分,滚粗!”。
变聪明了的“贴图渲染”——TBR

IMR傻大粗的做法不可取,那就来一个聪明点的方式——TBR(Tile Based Rendering,贴图渲染),它将需要渲染的画面分成一个个的区块(tile),每个区块的坐标通过中间缓冲器以列表形式保存在系统内存中。这种渲染方式的好处就是相对IMR减少了不必要的渲染任务,缺点就是遮蔽碎片依然会少量存在,而且需要中间缓冲器。

TBR渲染将游戏画面分为不同的区块
再次进化的渲染方式登场——TBDR
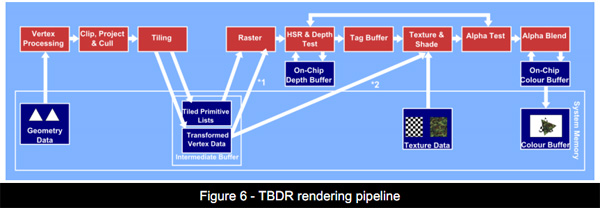
TBR虽然比IMR聪明多了,不过还是存在不少缺陷,TBDR(Tile Based Deferred Rendering,贴图延迟渲染)闪亮登场,它跟TBR原理相似,但是使用的是延迟渲染(Deferred Rendering),合并了完美像素,通过HSR(Hidden Surface Removal,隐藏面消除)等进一步减少了不需要渲染的过程,降低了带宽需求。实际上这些改变和PC上的渲染有些相似。

TBDR渲染的一个关键是延迟渲染
其他几家厂商用的都是TBR技术,TBDR主要是Imagination在使用,这也是他们最大的筹码之一。
在微软的DX11.1升级中也有提到支持TBDR,因为Windows 8系统还专门为平板和触控优化,对TBDR这种移动平台常用的技术加以优化也是必然的。
原文地址:http://blog.csdn.net/u013467442/article/details/40684479