标签:参数设置 简单 技术 价值 实时 remember 最大 命令 情况下
上一节:《JVM之GC算法》 知道GC算法的理论基础,我们来看看具体的实现。只有落地的理论,才是真理。
JVM虚拟机规范对垃圾收集器应该如何实现没有规定,因为没有最好的垃圾收集器,只有最适合的场景。
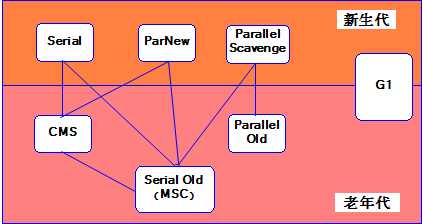
图中展示了7种作用于不同分代的收集器,如果两个收集器之间存在连线,则说明它们可以搭配使用。虚拟机所处的区域则表示它是属于新生代还是老年代收集器。
7种:serial收集器、parnew收集器、parallel scavenge收集器、serial old 收集器、parallel old收集器、cms收集器、g1收集器(整堆收集器)、
串行收集:单垃圾收集线程,进行收集工作,用户进程需要等待
并行收集:工作原理与串行一样,只是在收集垃圾时是多条线程同时进行,收集的效率在一般情况下自然高于单线程。
并发收集:指用户线程与垃圾收集线程同时工作(并发:同一时间间隔)。用户程序在继续运行,而垃圾收集程序运行在另一个CPU上。
吞吐量:吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值(吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间))
1、Serial收集器
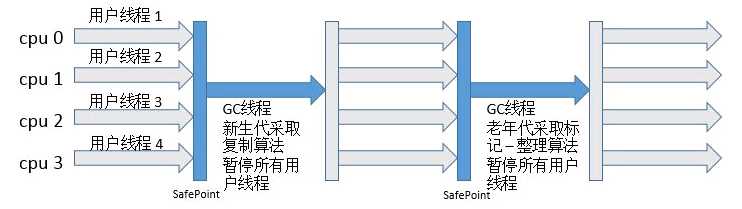
Serial(串行)收集器:最基本,最古老的收集器,只有一个线程进行垃圾收集器的工作,并且在进行垃圾收集工作时需要暂停其他工作线程(stop the word),直到他工作结束;
Serial收集器简单高效,工作时没有线程交互的开销,所以可以获得很高的单线程收集效率,对于运行在Client模式下的虚拟机来说很适合。
"-XX:+UseSerialGC":添加该参数来显式的使用Serial垃圾收集器。
2、Serial Old收集器
Serial Old收集器是Seria收集器的老年代版本,他同样是一个单线程收集器,使用" 标记-整理" 算法。
Serial Old收集器主要用于Client模式下的虚拟机使用。
Server模式下的两大用途:
3、ParNew 收集器
ParNew(并行)收集器就是Serial收集器的多线程版本,除了在收集垃圾时是启用多线程并行执行,其他行为(控制参数、收集算法、回收策略/Stop The Word、对象分配规则)完全一样
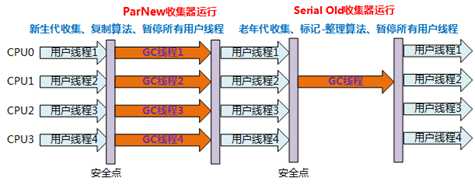
应用场景:ParNew收集器是许多运行在Server模式下的虚拟机中首选的新生代收集器,因为它是除了Serial收集器外,唯一一个能与CMS收集器配合工作的。
"-XX:+UseConcMarkSweepGC":指定使用CMS后,会默认使用ParNew作为新生代收集器。
"-XX:+UseParNewGC":强制指定使用ParNew。
"-XX:ParallelGCThreads":指定垃圾收集的线程数量,ParNew默认开启的收集线程与CPU的数量相同。
4、Parallel Scavenge收集器
Parallel Scavenge收集器 类似于 ParNew 收集器, Parallel Scavenge收集器 更加关注吞吐量(高效的CPU利用率)。CMS等垃圾收集器关注更多的是用户线程的停顿时间(提搞用户体验);Parallel Scavenge 收集器提供很多参数供我们找到最合适的停顿时间或者最大吞吐量。JDK1.8 默认的方式;
Parallel Scavenge收集器提供了两个参数来用于精确控制吞吐量,一是控制最大垃圾收集停顿时间的 -XX:MaxGCPauseMillis参数,二是控制吞吐量大小的 -XX:GCTimeRatio参数;
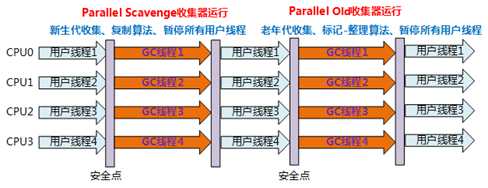
应用场景:注重高吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge+Parallel Old 收集器。
5、Paraller Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。
在JDK1.6中才出现。
6、CMS(Conturrent Mark Sweep)收集器
CMS收集器是一种以获取最短回收停顿时间为目标的收集器。CMS收集器是基于“标记-清除”算法实现,它的整个运行过程可以分为:
CMS收集器运行的整个过程中,最耗费时间的是并发标记和并发清除,GC收集器线程和用户线程是一起工作的,所以总体来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。
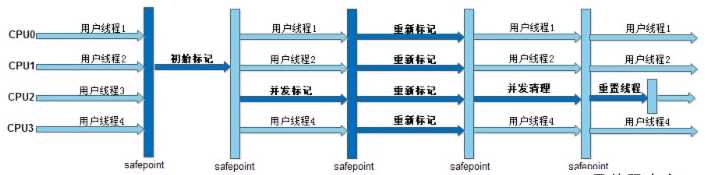
优点:并发收集、低停顿。
缺点:
7、G1(Garbage-First)收集器
G1的内存模型
G1收集器没有新生代和老年代的概念,而是将Java堆划分为一块块独立的大小相等的Region。当要进行垃圾收集时,首先估计每个Region中的垃圾数量,每次都从垃圾回收价值最大的Region开始回收,因此可以获得最大的回收效率
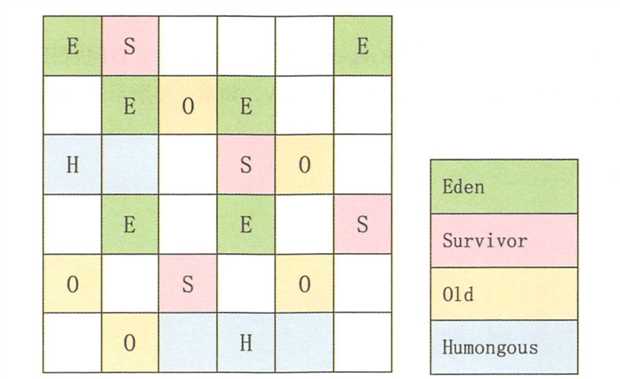
Humongous是特殊的Old类型,专门放置大型对象.这样的划分方式意味着不需要一个连续的内存空间管理对象.G1将空间分为多个区域,优先回收垃圾最多的区域.
G1采用的是Mark-Copy ,有非常好的空间整合能力,不会产生大量的空间碎片
G1的一大优势在于可预测的停顿时间,能够尽可能快地在指定时间内完成垃圾回收任务,在JDK11中,已经将G1设为默认垃圾回收器,通过jstat命令可以查看垃圾回收情况,在YGC时S0/S1并不会交换.
一个对象和它内部所引用的对象可能不在同一个Region中,那么当垃圾回收时,是否需要扫描整个堆内存才能完整地进行一次可达性分析?
当然不是,每个Region都有一个Remembered Set,用于记录本区域中所有对象引用的对象所在的区域,从而在进行可达性分析时,只要在GC Roots中再加上Remembered Set即可防止对所有堆内存的遍历.
回收步骤
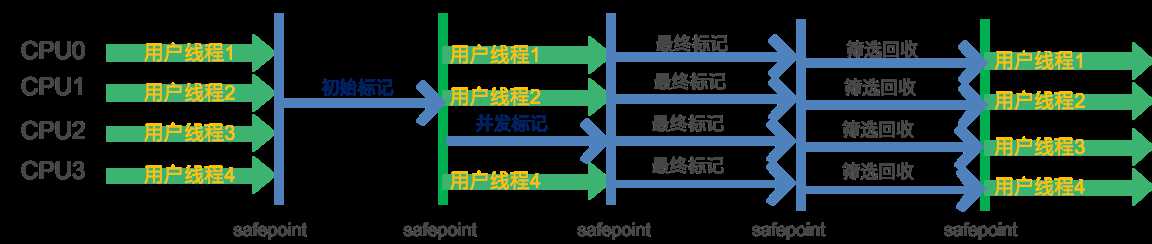
初始标记:标记与GC Roots直接关联的对象,停止所有用户线程,只启动一条初始标记线程,这个过程很快.
并发标记:进行全面的可达性分析,开启一条并发标记线程与用户线程并行执行.这个过程比较长.
最终标记:标记出并发标记过程中用户线程新产生的垃圾.停止所有用户线程,并使用多条最终标记线程并行执行.
筛选回收:回收废弃的对象.此时也需要停止一切用户线程,并使用多条筛选回收线程并行执行.
G1为什么能建立可预测的停顿时间模型?
因为它有计划的避免在整个Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆积的大小,在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region。这样就保证了在有限的时间内可以获取尽可能高的收集效率。
G1与其他收集器的区别?
其他收集器的工作范围是整个新生代或者老年代、G1收集器的工作范围是整个Java堆。在使用G1收集器时,它将整个Java堆划分为多个大小相等的独立区域(Region)。虽然也保留了新生代、老年代的概念,但新生代和老年代不再是相互隔离的,他们都是一部分Region(不需要连续)的集合。
1、单CPU或者小内存,单机程序 — -XX:+UseSerialGC
2、多CPU,需要大吞吐量,如后台计算型应用,允许工作线程停顿超过1秒 -XX:+UseParallelGC + -XX:+UseParallelOldGC
3、多CPU,追求低停顿时间,快速响应如互联网应用 -XX:+UseParNewGC + -XX:+UseConcMarkSweepGC
4、JVM自己选择
5、官方推荐G1,高性能
标签:参数设置 简单 技术 价值 实时 remember 最大 命令 情况下
原文地址:https://www.cnblogs.com/jalja365/p/12182064.html