标签:释放 读取 安全 sig 无锁 种类 优先 缓存系统 while
如果我们想要在线程安全的场景下使用队列,只有两个选择,一个是上面讲过的 ConcurrentLinkedQueue,还有就是我们要将的阻塞队列。
从名字我们就可以判断出阻塞队列适用的场景,那就是生产者消费者模式。阻塞对垒的添加和删除操作在队列满或者空的时候会被阻塞。这就保证了线程安全。
阻塞队列提供了四种处理方法:
| 方法 | 抛异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入 | add(E e) | offer(e) | put(e) | offer(e,time,unit) |
| 删除 | remove() | poll() | take() | poll(time, unit) |
| 获取 | element() | peek() | 不可用 | 不可用 |
阻塞方法 put 和 take,当队列满时,如果生产者继续 put,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列为空时,如果消费者继续 take,队列也会阻塞消费者线程,直到队列可用。
BlockingQueue 提供了很多安全高效的队列接口,为我们快速搭建高质量的多线程程序带来了极大的便利。
BlockingQueue 的底层基于 ReentrantLock 来实现。
重要成员
| 队列 | 有界性 | 锁 | 底层结构 |
|---|---|---|---|
| ArrayBlockingQueue | 有界 | 锁 | 数组 |
| LinkedBlockingQueue | 有界 | 锁 | 链表 |
| PriorityBlockingQueue | 无界 | 锁 | 堆 |
| DelayQueue | 无界 | 锁 | 堆 |
| SynchronousQueue | 有界 | 锁 | 无 |
| LinkedTransferQueue | 无界 | 锁 | 堆 |
| LinkedBllockingDeque | 无界 | 无锁 | 堆 |
ArrayBlockingQueue
是用数组实现的有界阻塞队列。严格的 FIFO 顺序堆元素进行排序。支持公平锁和非公平锁(从 ReentrantLock 继承来的属性)。
先来看 ArrayBlockingQueue 的构造方法都做了什么。
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair); //重入锁,出队和入队持有这一把锁
notEmpty = lock.newCondition(); //初始化非空等待队列
notFull = lock.newCondition(); //初始化非满等待队列
}offer
public boolean offer(E e) {
checkNotNull(e); //对请求数据做判断
final ReentrantLock lock = this.lock;
lock.lock();
try {
f (count == items.length)
return false;
else {
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x; //通过 putIndex 对数据赋值
if (++putIndex == items.length) // 当putIndex 等于数组长度时,将 putIndex 重置为 0
putIndex = 0;
count++;//记录队列元素的个数
notEmpty.signal();//唤醒处于等待状态下的线程,表示当前队列中的元素不为空,如果存在消费者线程阻塞,就可以开始取出元素
}put
put 总体和 offer 的功能差不多,只不过,在队列满的时候,会调用 await 方法对线程进行阻塞。
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); //这个也是获得锁,但是和 lock 的区别是,这个方法优先允许在等待时由其他线程调用等待线程的 interrupt 方法来中断等待直接返回。而 lock方法是尝试获得锁成功后才响应中断
try {
while (count == items.length)
notFull.await();//队列满了的情况下,当前线程将会被 notFull 条件对象挂起加到等待队列中
enqueue(e);
} finally {
lock.unlock();
}
}poll 和 take
poll 和 take 的实现与 offer 和 put 相差不多。这里给出 take 的代码。
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex]; //默认获取 0 位置的元素
items[takeIndex] = null;//将该位置的元素设置为空
if (++takeIndex == items.length)//这里的作用也是一样,如果拿到数组的最大值,那么重置为 0,继续从头部位置开始获取数据
takeIndex = 0;
count--;//记录 元素个数递减
if (itrs != null)
itrs.elementDequeued();//同时更新迭代器中的元素数据
notFull.signal();//触发 因为队列满了以后导致的被阻塞的线程
return x;
}一个由链表构成的有界队列,最大长度为 Integer.MAX_VALUE。此队列按照先进先出的顺序进行排序。
先来看成员变量
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
//队列容量大小,默认为Integer.MAX_VALUE
private final int capacity;
//队列中元素个数:(与ArrayBlockingQueue的不同)
//出队和入队是两把锁
private final AtomicInteger count = new AtomicInteger(0);
//队列--头结点
private transient Node<E> head;
//队列--尾结点
private transient Node<E> last;
//与ArrayBlockingQueue的不同,两把锁
//读取锁
private final ReentrantLock takeLock = new ReentrantLock();
//出队等待条件
private final Condition notEmpty = takeLock.newCondition();
//插入锁
private final ReentrantLock putLock = new ReentrantLock();
//入队等待条件
private final Condition notFull = putLock.newCondition();
}底层的链表的结构。
//队列存储元素的结点(链表结点):
static class Node<E> {
//队列元素:
E item;
//链表中指向的下一个结点
Node<E> next;
//结点构造:
Node(E x) { item = x; }
}构造函数。
//默认构造函数:
public LinkedBlockingQueue() {
//默认队列长度为Integer.MAX_VALUE
this(Integer.MAX_VALUE);
}
//指定队列长度的构造函数:
public LinkedBlockingQueue(int capacity) {
//初始化链表长度不能为0
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
//设置头尾结点,元素为null
last = head = new Node<E>(null);
}初始长度为 int 的最大值。
put
核心原理与 ArrayBlockingQueue 几本差不多。
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
/*注意上面这句话,约定所有的put/take操作都会预先设置本地变量,
可以看到下面有一个将putLock赋值给了一个局部变量的操作
*/
int c = -1;
Node<E> node = new Node(e);
/*
在这里首先获取到putLock,以及当前队列的元素数量
即上面所描述的预设置本地变量操作
*/
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
/*
执行可中断的锁获取操作,即意味着如果线程由于获取
锁而处于Blocked状态时,线程是可以被中断而不再继
续等待,这也是一种避免死锁的一种方式,不会因为
发现到死锁之后而由于无法中断线程最终只能重启应用。
*/
putLock.lockInterruptibly();
try {
/*
当队列的容量到底最大容量时,此时线程将处于等待状
态,直到队列有空闲的位置才继续执行。使用while判
断依旧是为了放置线程被"伪唤醒”而出现的情况,即当
线程被唤醒时而队列的大小依旧等于capacity时,线
程应该继续等待。
*/
while (count.get() == capacity) {
notFull.await();
}
//让元素进行队列的末尾,enqueue代码在上面分析过了
enqueue(node);
//首先获取原先队列中的元素个数,然后再对队列中的元素个数+1.
c = count.getAndIncrement();
/*注:c+1得到的结果是新元素入队列之后队列元素的总和。
当前队列中的总元素个数小于最大容量时,此时唤醒其他执行入队列的线程
让它们可以放入元素,如果新加入元素之后,队列的大小等于capacity,
那么就意味着此时队列已经满了,也就没有必须要唤醒其他正在等待入队列的线程,因为唤醒它们之后,它们也还是继续等待。
*/
if (c + 1 < capacity)
notFull.signal();
} finally {
//完成对锁的释放
putLock.unlock();
}
/*当c=0时,即意味着之前的队列是空队列,出队列的线程都处于等待状态,
现在新添加了一个新的元素,即队列不再为空,因此它会唤醒正在等待获取元素的线程。
*/
if (c == 0)
signalNotEmpty();
}
/*
唤醒正在等待获取元素的线程,告诉它们现在队列中有元素了
*/
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//通过notEmpty唤醒获取元素的线程
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
offer
offer 方法在队列满的时候会直接返回 false。其他与 put 没有差别。
/**
在BlockingQueue接口中除了定义put方法外(当队列元素满了之后就会阻塞,
直到队列有新的空间可以方法线程才会继续执行),还定义一个offer方法,
该方法会返回一个boolean值,当入队列成功返回true,入队列失败返回false。
该方法与put方法基本操作基本一致,只是有细微的差异。
*/
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
/*
当队列已经满了,它不会继续等待,而是直接返回。
因此该方法是非阻塞的。
*/
if (count.get() == capacity)
return false;
int c = -1;
Node<E> node = new Node(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
/*
当获取到锁时,需要进行二次的检查,因为可能当队列的大小为capacity-1时,
两个线程同时去抢占锁,而只有一个线程抢占成功,那么此时
当线程将元素入队列后,释放锁,后面的线程抢占锁之后,此时队列
大小已经达到capacity,所以将它无法让元素入队列。
下面的其余操作和put都一样,此处不再详述
*/
if (count.get() < capacity) {
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}take
Take 方法的实现思路与 ArrayBlockingQueue 没有任何差别,只不过这里使用 takeLock。
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
//通过takeLock获取锁,并且支持线程中断
takeLock.lockInterruptibly();
try {
//当队列为空时,则让当前线程处于等待
while (count.get() == 0) {
notEmpty.await();
}
//完成元素的出队列
x = dequeue();
/*
队列元素个数完成原子化操作-1,可以看到count元素会
在插入元素的线程和获取元素的线程进行并发修改操作。
*/
c = count.getAndDecrement();
/*
当一个元素出队列之后,队列的大小依旧大于1时
当前线程会唤醒其他执行元素出队列的线程,让它们也
可以执行元素的获取
*/
if (c > 1)
notEmpty.signal();
} finally {
//完成锁的释放
takeLock.unlock();
}
/*
当c==capaitcy时,即在获取当前元素之前,
队列已经满了,而此时获取元素之后,队列就会
空出一个位置,故当前线程会唤醒执行插入操作的线
程通知其他中的一个可以进行插入操作。
*/
if (c == capacity)
signalNotFull();
return x;
}
/**
* 让头部元素出队列的过程
* 其最终的目的是让原来的head被GC回收,让其的next成为head
* 并且新的head的item为null.
* 因为LinkedBlockingQueue的头部具有一致性:即元素为null。
*/
private E dequeue() {
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
选择 LinkedBlockingQueue 的理由
固定线程数的线程池里面就选用了 LinkedBlockingQueue 这个无界队列。
/**
下面的代码是Executors创建固定大小线程池的代码,其使用了
LinkedBlockingQueue来作为任务队列。
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}对于固定大小的线程池来说,线程数量有限,很容易出现所有线程都在工作的情况。此时如果再给一个有界队列,很容易导致任务无法提交而出现拒绝的情况。LinkedBlockingQueue 由于其良好的存储容量伸缩性,可以很好的去缓冲任务,非常灵活。
PriorityBlockingQueue 是一个基于优先级的无界阻塞队列。基于优先级是因为它的底层是通过堆这种数据结构来实现的,堆可以通过数组来实现。之所以说是无界,是因为它的底层数组可以动态扩容。
出队方式是根据权重来出队。并不是严格的先进先出或者先进后出。
先来看 PriorityBlockingQueue 的属性。
/**
* 默认数组长度
*/
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* 最大达容量,分配时超出可能会出现 OutOfMemoryError 异常
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 队列,存储我们的元素
*/
private transient Object[] queue;
/**
* 队列长度
*/
private transient int size;
/**
* 比较器,入队进行权重的比较
*/
private transient Comparator<? super E> comparator;
/**
* 显示锁
*/
private final ReentrantLock lock;
/**
* 空队列时进行线程阻塞的 Condition 对象
*/
private final Condition notEmpty;
offer
整体代码与上面两个阻塞队列并没有什么不同,只不过需要根据比较器来对堆中元素进行上浮操作(新加的元素会被放到队尾)。
public void put(E e) {
offer(e); // never need to block
}
public boolean offer(E e) {
//判断是否为空
if (e == null)
throw new NullPointerException();
//显示锁
final ReentrantLock lock = this.lock;
lock.lock();
//定义临时对象
int n, cap;
Object[] array;
//判断数组是否满了
while ((n = size) >= (cap = (array = queue).length))
//数组扩容
tryGrow(array, cap);
try {
//拿到比较器
Comparator<? super E> cmp = comparator;
//判断是否有自定义比较器
if (cmp == null)
//堆上浮
siftUpComparable(n, e, array);
else
//使用自定义比较器进行堆上浮
siftUpUsingComparator(n, e, array, cmp);
//队列长度 +1
size = n + 1;
//唤醒休眠的出队线程
notEmpty.signal();
} finally {
//释放锁
lock.unlock();
}
return true;
}
出队方法也与其他队列类似,只不过在删除堆顶部的元素后,需要把队尾的元素放到堆的顶部然后进行下沉操作。
DelayQueue 中的每个元素都有过期时间,只有过期时间为 0 时这个元素才能被取出。并且这个队列是一个优先级队列。优先级队列的队首位置是即将到期的元素。
来看 DelayQueue 的构造函数。
private final transient ReentrantLock lock = new ReentrantLock();
private final PriorityQueue<E> q = new PriorityQueue<E>();
private Thread leader = null;
private final Condition available = lock.newCondition();offer
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
if (q.peek() == e) {(2)
leader = null;
available.signal();
}
return true;
} finally {
lock.unlock();
}
}take
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null) {
available.await();
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay > 0) {
long tl = available.awaitNanos(delay);
} else {
E x = q.poll();
assert x != null;
if (q.size() != 0)
available.signalAll(); // wake up other takers
return x;
}
}
}
} finally {
lock.unlock();
}
}应用场景
可以把它看成 LinkedBlockingQueue 和 SynchronousQueue 的合体。SynchronousQueue 内部无法存储元素,当要添加元素的时候,需要阻塞,而 LinkedBlockingQueue 则内部使用了大量的锁,性能不高。
相比于普通阻塞队列增加的方法:
public interface TransferQueue<E> extends BlockingQueue<E> {
// 如果可能,立即将元素转移给等待的消费者。
// 更确切地说,如果存在消费者已经等待接收它(在 take 或 timed poll(long,TimeUnit)poll)中,则立即传送指定的元素,否则返回 false。
boolean tryTransfer(E e);
// 将元素转移给消费者,如果需要的话等待。
// 更准确地说,如果存在一个消费者已经等待接收它(在 take 或timed poll(long,TimeUnit)poll)中,则立即传送指定的元素,否则等待直到元素由消费者接收。
void transfer(E e) throws InterruptedException;
// 上面方法的基础上设置超时时间
boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException;
// 如果至少有一位消费者在等待,则返回 true
boolean hasWaitingConsumer();
// 返回等待消费者人数的估计值
int getWaitingConsumerCount();
}
逻辑总结:
找到 head 节点,如果 head 节点是匹配的操作,就直接赋值,如果不是,添加到队列中。队列中永远只有一种类型的操作,要么是 put 要么是 take。
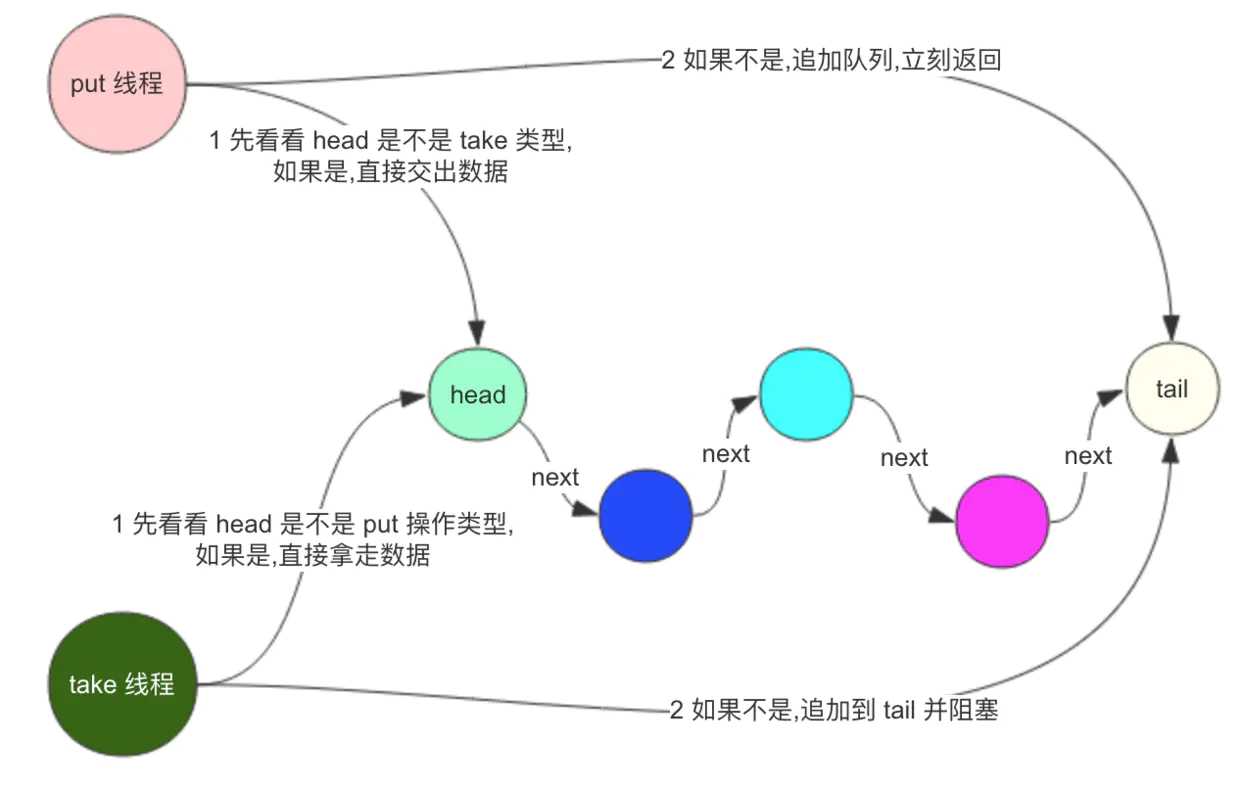
SynchronousQueue 是一个内部只包含一个元素的队列。插入元素到队列的线程被阻塞,直到另一个线程从队列中获取到了队列中存储的元素。同理,如果线程尝试获取元素并且当前不存在任何元素,则线程将被阻塞,直到线程将元素插入队列。
SynchronousQueue 是一个无存储空间的阻塞队列。也可以实现公平或者非公平获取。它的每个插入操作都需要等待其他线程相应的删除操作。比较适合切换或者传递的场景。
SynchronousQueue 内部没有容量,所以不能通过 peek 方法来获取头部元素。也不能单独插入元素,可以理解为插入和移除是配对的。
SynchronousQueue 的使用场景是在线程池里。Executors.newCachedThreadPool 就使用了 SynchronousQueue。这个线程池根据需要(新任务到来时)创建新的线程,如果又空闲线程就重复使用,线程超过 60 秒就被删除。很多高性能的服务器中,如果并发很高,普通的 LinkedQueue 就会成为瓶颈,换上 SynchronousQueue 会好很多。
数据结构
SynchronousQueue 支持公平和非公平策略,所以底层有两种数据结构:队列(公平)和栈(非公平)。
内部类结构
其中比较重要的是左边的三个类,Transferer 定义了转移数据的公共操作,由 TransferStack 和 TransferQueue 具体实现。后面的三各类是为了兼容以前的版本,不做具体解释了。
abstract static class Transferer<E> {
/**
* Performs a put or take.
*/
// 转移数据,put或者take操作
abstract E transfer(E e, boolean timed, long nanos);
}transfer 方法用于 put 和 take 数据。
TransQueue
构造方法:
创建一个初始化的链表,第一个值为 null,头尾节点都指向它。
TransferQueue() {
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}节点类:
/** Node class for TransferQueue. */
static final class QNode {
volatile QNode next; // next node in queue
volatile Object item; // CAS'ed to or from null
volatile Thread waiter; // to control park/unpark
final boolean isData;
}
来看 transfer 方法:
QNode s = null; // constructed/reused as needed
boolean isData = (e != null);// 当输入的是数据时,isData 就是 ture,表明这个操作是一个 put 的操作;同理,当调用者输入的是 null,则是 take 的操作。
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // 如果并发导致未"来得及"初始化
continue; // 自旋重来
// 以下分成两个部分进行
// 1. 头尾相同(表明队列中啥都没有) 或者 当前节点和 操作模式与尾节点的操作模式相同,需要进行链表追加操作。
if (h == t || t.isData == isData) {
QNode tn = t.next;
if (t != tail) // 如果 t 和 tail 不一样,说明,tail 被其他的线程改了,重来
continue;
if (tn != null) { // 如果 tail 的 next 不是空。当前的 tail 不是真正的 tail。
advanceTail(t, tn); // 使用 CAS 将 tail.next 变成 tail,
continue;
}
if (timed && nanos <= 0) // 时间到了,不自旋等待,返回 null,插入失败,获取也是失败的。
return null;
if (s == null) // 如果能走到这里,说明 tail 的 next 是 null,这里的判断是避免重复创建 Qnode 对象。
s = new QNode(e, isData);// 创建一个新的节点。
if (!t.casNext(null, s)) // 尝试 CAS 将这个刚刚创建的节点追加到 tail 的 next 节点上.
continue;// 如果失败,则重来
advanceTail(t, s); // 当新的节点成功追加到 tail 节点的 next 上了, 就尝试将 tail.next 节点覆盖 tail 节点,称之为推进。就是将新插入的节点设置尾 tail。
// s == 新节点,“可能”是新的 tail;e 是实际数据。
Object x = awaitFulfill(s, e, timed, nanos);// 该方法作用就是,让当前线程等待。排除意外情况和超时的话,就是等待其他线程拿走数据并替换成 isData 不同的数据。
if (x == s) { // x == s 是什么意思呢? 表明在 awaitFulfill 方法中,这个数据被取消了,tryCancel 方法就是将 item 覆盖了 QNode。说明这次操作失败了。
clean(t, s);// 操作失败则需要清理数据,并返回 null。
return null;
}
// 如果一切顺利,确实被其他线程唤醒了,其他线程也交换了数据。
// 这个判断:next != this,说明了什么?当这个 tail 节点的 next 不再指向自己,说明了
if (!s.isOffList()) { // not already unlinked
// 这一步是将 S 节点设置为 Head,并且将新 Head 的 next 指向自己,让 Head 和之前的 next 断开。
advanceHead(t, s); // unlink if head
// 当 x 不是 null,表明对方线程是存放数据的。
if (x != null) // and forget fields
// 这一步操作将自己的 item 设置成自己。
s.item = s;
// 将 S 节点的持有线程变成 null。
s.waiter = null;
}
// x 不是 null 表明,对方线程是生产者,返回他生产的数据;如果是 null,说明对方线程是消费者,那他自己就是生产者,返回自己的数据,表示成功。
return (x != null) ? (E)x : e;
}
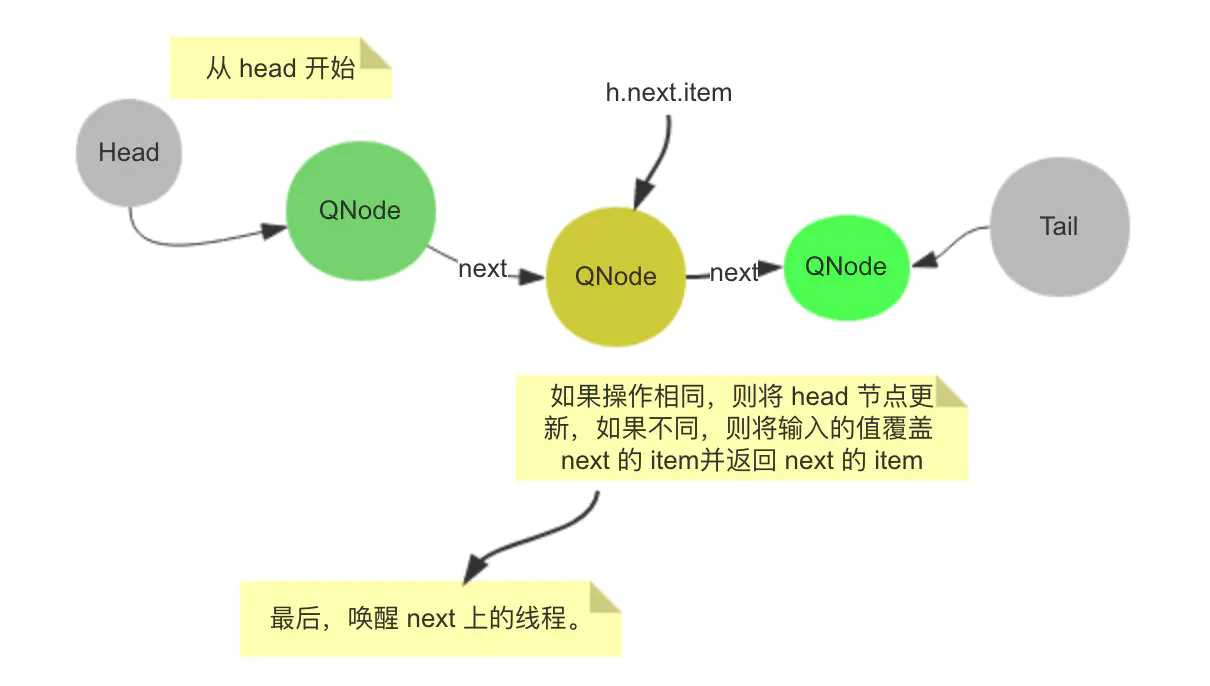
// 2. 如果当前的操作类型和 tail 的操作不一样。称之为互补。
else { // complementary-mode
QNode m = h.next; // node to fulfill
// 如果下方这些判断没过,说明并发修改了,自旋重来。
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
// 如果 head 节点的 isData 和当前操作相同,
// 如果 操作不同,但 head 的 item 就是自身,也就是发生了取消操作,tryCancel 方法会做这件事情。
// 如果上面2个都不满足,尝试使用 CAS 将 e 覆盖 item。
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
// CAS 失败了,Head 的操作类型和当前类型相同,item 被取消了,都会走这里。
// 将 h.next 覆盖 head。重来。
advanceHead(h, m); // dequeue and retry
continue;
}
// 这里也是将 h.next 覆盖 head。能够走到这里,说明,上面的 CAS 操作成功了,当前线程已经将 e 覆盖了 next 的 item 。
advanceHead(h, m); // successfully fulfilled
// 唤醒 next 的 线程。提醒他可以取出数据,或者“我”已经拿到数据了。
LockSupport.unpark(m.waiter);
// 如果 x 不是 null,表明这是一次消费数据的操作,反之,这是一次生产数据的操作。
return (x != null) ? (E)x : e;
}
}
总结一下:
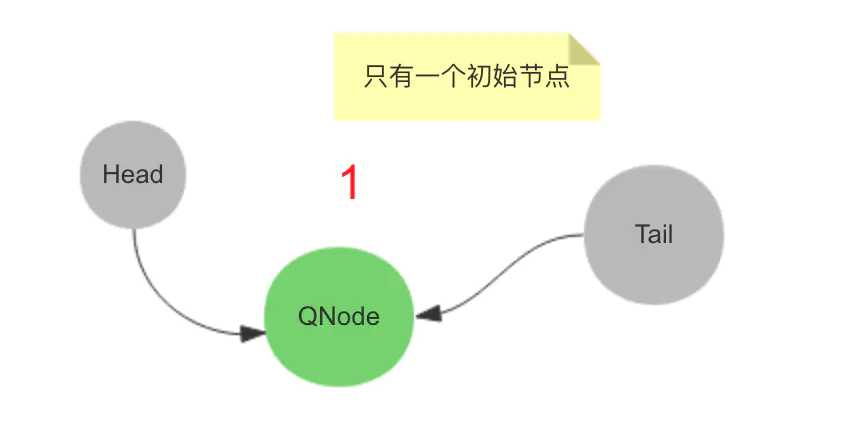
用图来解释一下:
初始化时只有一个空的 node。
一个线程尝试 offer 或者 poll 数据,会插入新节点。
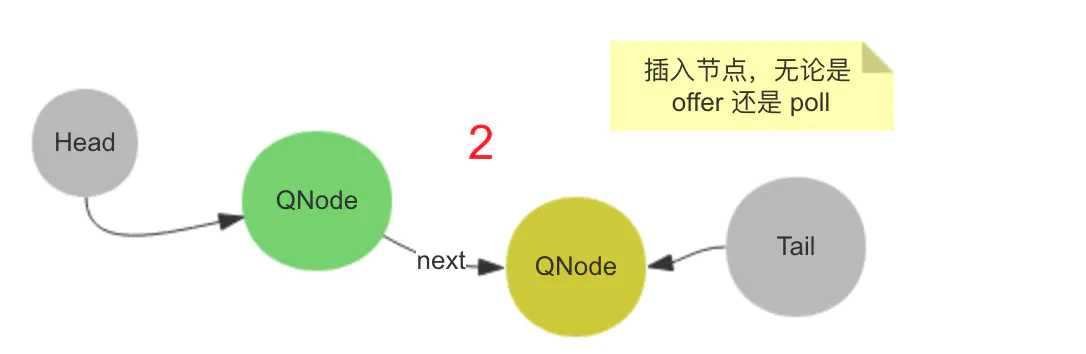
又有一个线程尝试 offer 或者 poll 数据并且与上一个操作的线程的模式相同。
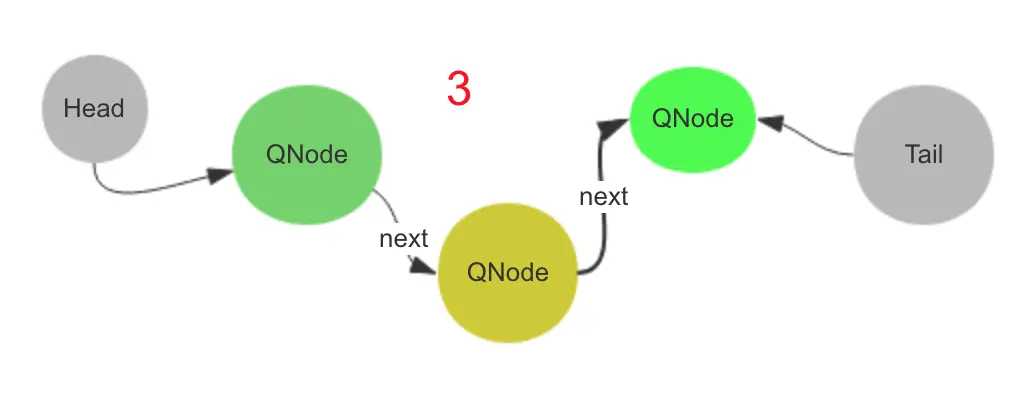
这时队列中有两个真是数据并且线程都是 wait 的,因为没有人接收数据,此时再来一个线程,与上面两个线程进行相反模式的操作。
为什么某些情况下,比 LinkedBlockingQueue 性能高那?原因是没有使用锁,另外线程之间交换数据的方式也比较高效。
TransferStack
TransferStack 由三种不同的状态,REQUEST 表示消费数据的消费者,DATA 表示生产数据的生产者,FUFILLING 表示匹配另一个生产者或消费者。任何线程对 TransferStack 的操作都属于上面三个的一种,同时还包含一个 head 表示头节点。
static final class TransferStack<E> extends Transferer<E> {
/* Modes for SNodes, ORed together in node fields */
/** Node represents an unfulfilled consumer */
// 表示消费数据的消费者
static final int REQUEST = 0;
/** Node represents an unfulfilled producer */
// 表示生产数据的生产者
static final int DATA = 1;
/** Node is fulfilling another unfulfilled DATA or REQUEST */
// 表示匹配另一个生产者或消费者
static final int FULFILLING = 2;
/** The head (top) of the stack */
// 头结点
volatile SNode head;
}tryMatch
boolean tryMatch(SNode s) {
if (match == null &&
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) { // 本结点的match域为null并且比较并替换match域成功
// 获取本节点的等待线程
Thread w = waiter;
if (w != null) { // 存在等待的线程 // waiters need at most one unpark
// 将本结点的等待线程重新置为null
waiter = null;
// unpark等待线程
LockSupport.unpark(w);
}
return true;
}
// 如果match不为null或者CAS设置失败,则比较match域是否等于s结点,若相等,则表示已经完成匹配,匹配成功
return match == s;
}使用 CAS 尝试将本节点与 s 节点进行配对。如果匹配成功,则 unpark 当前节点。
transfer 函数
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
// 根据e确定此次转移的模式(是put or take)
int mode = (e == null) ? REQUEST : DATA;
for (;;) { // 无限循环
// 保存头结点
SNode h = head;
if (h == null || h.mode == mode) { // 头结点为null或者头结点的模式与此次转移的模式相同 // empty or same-mode
if (timed && nanos <= 0) { // 设置了timed并且等待时间小于等于0,表示不能等待,需要立即操作 // can't wait
if (h != null && h.isCancelled()) // 头结点不为null并且头结点被取消
casHead(h, h.next); // 重新设置头结点(弹出之前的头结点) // pop cancelled node
else // 头结点为null或者头结点没有被取消
// 返回null
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) { // 生成一个SNode结点;将原来的head头结点设置为该结点的next结点;将head头结点设置为该结点
// Spins/blocks until node s is matched by a fulfill operation.
// 空旋或者阻塞直到s结点被FulFill操作所匹配
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // 匹配的结点为s结点(s结点被取消) // wait was cancelled
// 清理s结点
clean(s);
// 返回
return null;
}
if ((h = head) != null && h.next == s) // h重新赋值为head头结点,并且不为null;头结点的next域为s结点,表示有结点插入到s结点之前,完成了匹配
// 比较并替换head域(移除插入在s之前的结点和s结点)
casHead(h, s.next); // help s's fulfiller
// 根据此次转移的类型返回元素
return (E) ((mode == REQUEST) ? m.item : s.item);
}
} else if (!isFulfilling(h.mode)) { // 没有FULFILLING标记,尝试匹配 // try to fulfill
if (h.isCancelled()) // 被取消 // already cancelled
// 比较并替换head域(弹出头结点)
casHead(h, h.next); // pop and retry
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) { // 生成一个SNode结点;将原来的head头结点设置为该结点的next结点;将head头结点设置为该结点
for (;;) { // 无限循环 // loop until matched or waiters disappear
// 保存s的next结点
SNode m = s.next; // m is s's match
if (m == null) { // next域为null // all waiters are gone
// 比较并替换head域
casHead(s, null); // pop fulfill node
// 赋值s为null
s = null; // use new node next time
break; // restart main loop
}
// m结点的next域
SNode mn = m.next;
if (m.tryMatch(s)) { // 尝试匹配,并且成功
// 比较并替换head域(弹出s结点和m结点)
casHead(s, mn); // pop both s and m
// 根据此次转移的类型返回元素
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // 匹配不成功 // lost match
// 比较并替换next域(弹出m结点)
s.casNext(m, mn); // help unlink
}
}
} else { // 头结点正在匹配 // help a fulfiller
// 保存头结点的next域
SNode m = h.next; // m与h可以匹配 // m is h's match
if (m == null) // next域为null // waiter is gone
// 比较并替换head域(m被其他结点匹配了,需要弹出h)
casHead(h, null); // pop fulfilling node
else { // next域不为null
// 获取m结点的next域
SNode mn = m.next;
if (m.tryMatch(h)) // m与h匹配成功 // help match
// 比较并替换head域(弹出h和m结点)
casHead(h, mn); // pop both h and m
else // 匹配不成功 // lost match
// 比较并替换next域(移除m结点)
h.casNext(m, mn); // help unlink
}
}
}
}标签:释放 读取 安全 sig 无锁 种类 优先 缓存系统 while
原文地址:https://www.cnblogs.com/paulwang92115/p/12184823.html