标签:需要 之间 导致 并且 也会 root 大于 创建 EAP
简单来说数据结构是计算机存储,组织数组的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
数组结构的分类:数组、栈、堆、队列、链表、树、图、散列表,本文主要介绍栈和堆。
一、定义
栈(Stack)又名堆栈,它作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。
栈是允许在同一端进行插入和删除操作的特殊线性表。允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。
堆(Heap)通常是一个可以被看做一棵完全二叉树的数组对象。每个节点有一个值,堆中某个节点的值总是不大于或不小于其父节点的值。常用来实现优先队列,堆的存取方式跟顺序没有关系,无序存取,根据引用直接获取。
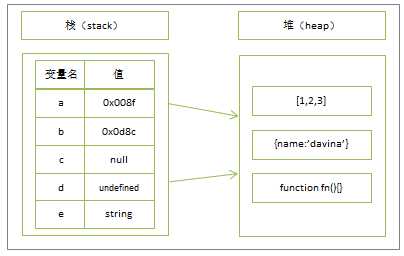
内存一般指的是计算机的随机存储器(RAM)程序一般在此运行。JS内存空间分为栈(stack)、堆(heap)、池(一般也会归类为栈中)。 其中栈存放变量,堆存放复杂对象,池存放常量,所以也叫常量池。
基本类型:保存在栈内存中,因为这些类型在内存中分别占有固定大小的空间,通过按值来访问。基本类型:Undefined、Null、Boolean、Number 、String。大致来说栈内存有如下特点:存储基本数据类型,按值访问,存储的值大小固定,系统自动分配和释放空间,主要是用来执行程序,空间小运行效率高,先进后出,后进先出
引用类型 :如对象,数组,函数等它们是通过拷贝和new出来的,保存在堆内存中。因为这种值的大小不固定,因此不能把它们保存到栈内存中,因此保存在堆内存中,其实,说存储于堆中不太准确,因为引用类型的数据的地址指针是存储于栈中的,当我们想要访问引用类型的值,需要先从栈中获得对象的地址指针然后在通过地址指针找到堆中的所需要的数据。堆内存的特点:存储引用数据类型,按引用访问,存储的值大小不定,可动态调整,手动分配和释放空间,主要用来存放对象,空间大,运行效率较低,是一种无序的存储,可根据引用直接获取。
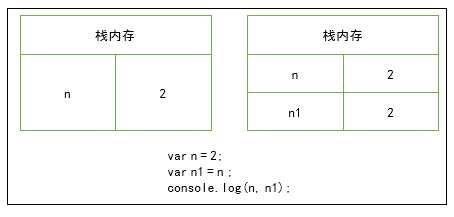
基本数据类型:某本数据类型的值保存在栈内存中,访问方式是按值访问,从一个变量向一个变量复制时,会在栈中创建一个新值,然后把值复制到为新变量分配的位置上。
<script>
//基本数据类型的赋值就是把值复制了一下
var n = 2;
var n1 = n ;
console.log(n, n1); //2 2
//复杂数据类型的赋值,它不光复制了值,还复制了内存中的引用地址
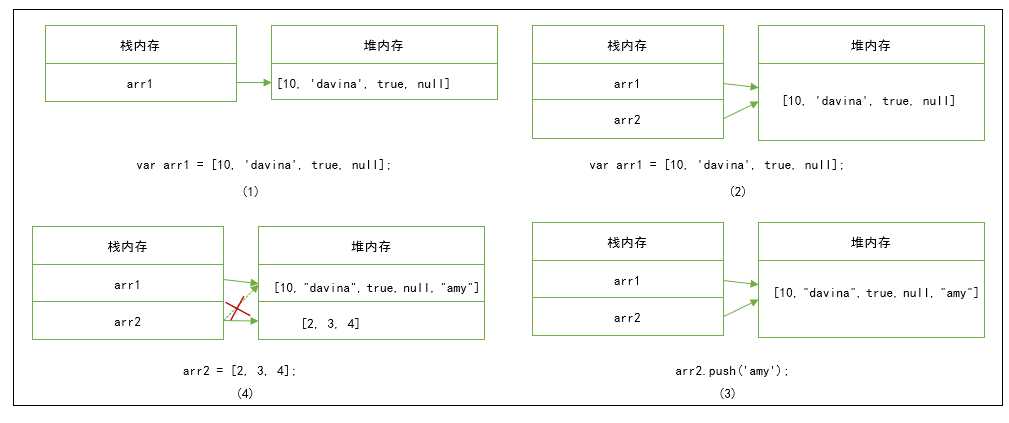
var arr1 = [10, ‘davina‘, true, null];
var arr2 = arr1;
var str1 = arr1[3];
arr2.push(‘amy‘); //arr1与arr2的引用地址是相同的所以不论修改了哪个,两个都会一起改变
console.log(arr2); // [10, "davina", true, null, "amy"]
console.log(arr1); // [10, "davina", true, null, "amy"]
arr2 = [2, 3, 4]; //因为arr2又重新赋值了,所以又开辟了一块内存,引用地址就不一样
console.log(arr2); // [2, 3, 4]
console.log(arr1); // [10, "davina", true, null, "amy"]
console.log(str1); //null
str1 = 6;
console.log(arr1[3]); //null
</script>
引用数据类型:从上面的代码可以看出,当改变arr2时,arr1中的数据也发生了变化。这是因为arr1是数组属于引用类型,所以它赋值给arr2的时候传的是栈中的地址(相当于新建了一个不同名“指针”),而不是堆内存中对象的值。arr1和arr2都指向同一块堆内存,arr2修改堆内存时,也会影响到arr1。当arr2重新赋值时,又开辟了一块内存,arr2的引用指向这块新的内存,但arr1的指向并没有发生改变,所以这时arr2和arr1又不一样了。
str1得到的是一个基本的数据类型的赋值,所以str1只是从arr1堆内存中获取了一个数值并且直接保存在了栈中,,str1是直接在栈中修改,并不能直接影响到arr1堆内存的数据。
二、生命周期
不管什么程序,内存生命周期分为以下三步:1、分配所需要的内存 2、使用分配到的内存 3、不需要时将其释放(归放)。
js环境中分配的内存有如下声明周期:
a. 内存分配:声明变量,函数,对象的时候,系统会自动为他们分配内存
b. 内存使用: 即读写内存,也就是使用变量,函数
c. 内存回收: 由垃圾回收机制自动回收不再使用内存
js的内存分配:一般来说,js在定义变量时就完成了内存的分配。
<script>
var n = 2; //给数值变量分配内存
var s = ‘davina‘ //给字符分配内存
var o = { //给对象及其包含的值分配内存
a: 1,
b: 2
}
function fn(c) {
return c; //给函数分配内存
}
//有些函数调用结果是分配对象内存
var d = new Date() // 分配一个Date对象
</script>
变量的生命周期:一个变量与人一样都会有生命周期的,从定义到不再使用就是这个变量的生命周期,如果变量的生命周期已经到头,那这个变量就会被垃圾回收机制回收然后释放它的内存,局部变量的生命周期在函数执行完毕后就会结束,全局变量的生命周期在页面关闭后才结束。
js的内存使用:使用值的过程实际上是对分配内存进行读取与写入的操作,读取与写入可能是写入一个变量或者一个对象的属性值,甚至传递函数的参数。
<script>
var n = 2; //给数值变量分配内存
console.log(n) //对内存的使用
</script>
三、垃圾回收机制
垃圾回收机制一般有以下几点:
1、用来释放内存
2、当一个数据使用完成后,垃圾回收机制会检测这个数据有没有在其它地方被引用 ,或者说是在其它的地方有没有在使用,如果没有使用的话就被回收,并释放它占用的内存,如果在其它地方依然有使用,那就不会被回收
3、垃圾回收机制是自动的,会定期去检查数据的使用情况
4、回收策略
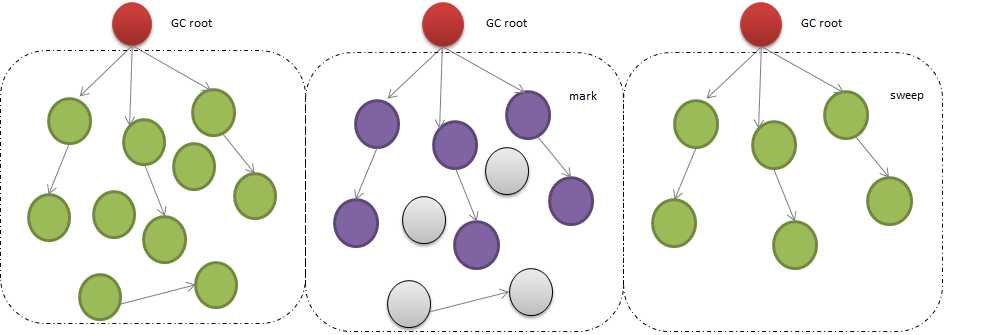
a. 标记清除(常用)
标记清楚是将“不在使用的对象”定义为“无法到达的对象”。即从根部(在js中就是全局对象)出发定时扫描内存中的对象,凡是能从根部到达的对象进行保留,从根部出发无法触及到的对象被标记为不在使用,后面进行回收。
步骤:
垃圾回收器创建一个名为“roots”列表,roots通常是代码中的全局变量的引用(js中window对象是一个全局变量被当成root,window对象总是存在的,所以垃圾回收器可以检查它和它的子对象是否存在)。
所有roots被检查和标记,所有的子对象也被标查,从root开始的所有对象如果可以到达它不会被当成垃圾
所有标记清除的内存会被当成垃圾,进行回收。
<script>
function fn() {
var a = 10; //进行标记
a++;
a = null; //标记清除
}
</script>
b. 引用计数(不常用)
记录每个数据被使用的次数,当声明一个变量并将引用类型赋值给该变量的时候这个值的引用次数就加1,如果这个变量的值变成了另外一个,则这个值的引用次数减1.当引用次数没有变为0的时候就会造成内存泄漏,这个策略没有办法想到引用的次数。
<script>
//引用计数
var person = {
age: 18, //标记1次
name: ‘davina‘
};
person.age = null; //虽然age设置了null,但是person对象还有指向name的引用,所以name不会被回收
var p = person;
person = 2; //原来的person对象被赋值为2,但因为有新引用p指向person对象,所以它不会被回收
p = null //person对象已经没有引用了,所以会被回收
</script>
引用计数有一个问题那就是循环引用,如果两个对象想到引用尽管不在使用,但不是被回收,可能导致内存泄露。
<script>
function fn() {
var a = {};
var b = {};
a.age = b;
b.age = a;
return ‘abc‘;
}
fn();
</script>
5、内存泄漏
程序的运行是需要用到内存的,对于持续运行的服务进程来说,必须及时的释放内存保证系统的正常运行。本质上来说,内存泄漏是由于疏忽或者是错误造成程序未能释放那些已经不在使用的内存,造成内存的浪费。
如果避免:不用的东西及时归还,减少不避要的全局变量。使用数据后及时解除引用(闭包,定时器等)避免死循环等等。
标签:需要 之间 导致 并且 也会 root 大于 创建 EAP
原文地址:https://www.cnblogs.com/davina123/p/12175304.html