标签:head 过程 system 需要 一个 有序 ram static 匹配
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。【来自百度百科】
老样子,前面有介绍
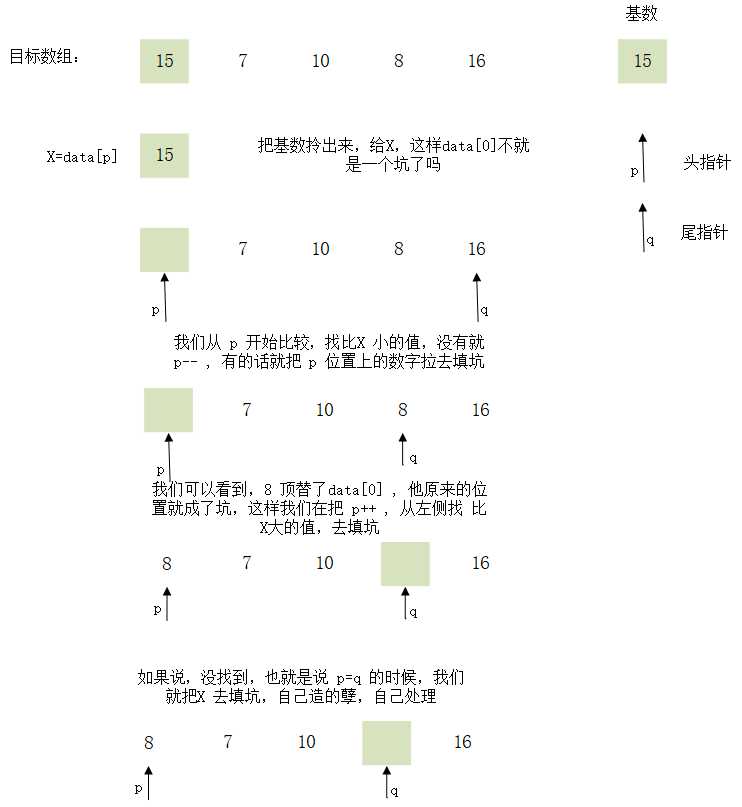
快速排序,在学习的时候,老师就说,快排,是分而治之。就像中国 960 万疆土,分成省市县镇乡村去管辖。这就是分而治之。在各自的辖区内,各自管辖,互不干涉,最后再把结果汇总,就形成了我中华960万的疆土。那这个辖区怎么划分?这就需要一个标准,这个标准就是我们所说的基数。基数怎么确定?随便。是的,你没听错,随便。我可以选择第一个数,可以选择最后一个数,也可以选择中间的那个数。同样,这个基数我也可以是随机的。那么,现在的问题来了,就是我现在确定了一个基数,怎么去做到分而治之呢?这个时候,有个大神美其名曰:填坑法。很形象,很生动,很通俗易懂。那这个填坑法怎么去做?我们看图说话。
public static void main(String[] args) {
int[] data = {15, 7, 10, 8, 16};
System.out.println("排序前:\n" + Arrays.toString(data));
quickSort(data, 0, data.length - 1);
System.out.println("排序后:\n" + Arrays.toString(data));
}
/**
* 快速排序,在学习的时候,老师就说,快排,是分而治之。就像中国 960 万疆土,分成省市县镇乡村去管辖。这就是分而治之。在各自的辖区内,
* 各自管辖,互不干涉,最后再把结果汇总,就形成了我中华960万的疆土。
* 那这个辖区怎么划分?这就需要一个标准,这个标准就是我们所说的基数。基数怎么确定?随便。是的,你没听错,随便。我可以选择第一个数,
* 可以选择最后一个数,也可以选择中间的那个数。同样,这个基数我也可以是随机的。
* 那么,现在的问题来了,就是我现在确定了一个基数,怎么去做到分而治之呢?这个时候,有个大神美其名曰:填坑法。很形象,很生动,很通俗
* 易懂。那这个填坑法怎么去做?我们看图说话。
*
* @param data
*/
private static void quickSort(int[] data, int left, int right) {
if (left < right) {
// 首先定下基数
int X = data[left];
int p = left, q = right;
while (p < q) {
// 从 左 -> 右 找 比 X 小的
while (p < q && data[q] >= X) {
q--;
}
if (p < q) {
data[p] = data[q];
p++;
}
while (p < q && data[p] < X) {
p++;
}
if (p < q) {
data[q] = data[p];
q--;
}
}
data[p] = X;
quickSort(data, left, p - 1);
quickSort(data, p + 1, right);
}
}// 这里要是用到 scala 就很简单了。可以利用 scala 里面的模式匹配
def main(args: Array[String]): Unit = {
var list: List[Int] = List (
1
, 2
, 5
, 8
, 10
, 25
, 9
, 6
)
println(quickSort(list))
}
def quickSort(list: List[Int]): List[Int] = list match {
case Nil => Nil
case List() => List()
case head :: tail =>
val (left, right) = tail.partition(_ < head)
quickSort(left) ::: head :: quickSort(right)
}

标签:head 过程 system 需要 一个 有序 ram static 匹配
原文地址:https://www.cnblogs.com/sun-iot/p/12188699.html