标签:带来 拆分 有一个 reac final redis 集群 mongo 覆盖 安全性
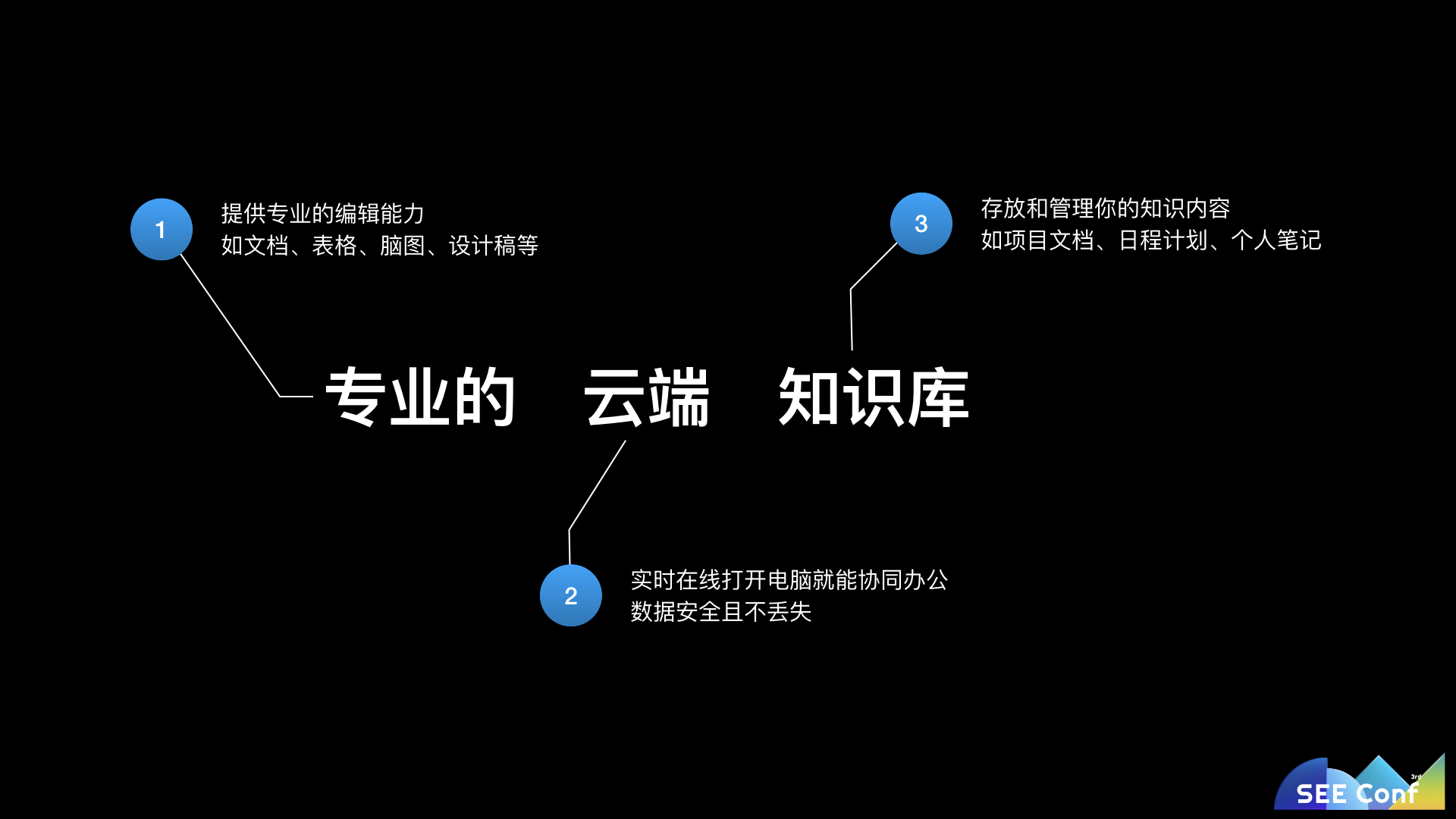
作者|? 不四(死马)蚂蚁金服 语雀产品技术负责人语雀是一个专业的云端知识库,面向个人和团队,提供与众不同的知识管理,打造轻松流畅的工作协同,它提供各种格式的在线文档(富文本、表格、设计稿等)编辑能力,支持实时在线多人协同编辑,数据云端保存不丢失。而语雀与其他文档工具最大的不同是,它通过知识库来对文档进行组织,让知识创作者更好的管理知识。
语雀诞生于 2016 年,当时蚂蚁金融云需要一个工具来承载它的文档。当时负责的技术同学利用业余时间,开始搭建这个文档工具。项目的初期,没有任何人员和资源支持,同时也为了快速验证原型,技术选型上选择了最低成本的方案。
底层服务完全基于体验技术部内部提供的 BaaS 服务和容器托管平台:
这些服务和平台都是基于 Node.js 实现,专门给内部创新型应用使用,也正是由于有这些降低创新成本的内部服务,才给工程师们提供了更好的创新环境。
应用层服务端自然而然的选用了体验技术部开源的 Node.js Web 框架 Egg(蚂蚁内部的封装 Chair),通过一个单体 Web 应用实现服务端。应用层客户端也选用了 React 技术栈,结合内部的 antd,并采用 CodeMirror 实现了一个功能强大、体验优雅的 markdown 在线编辑器。
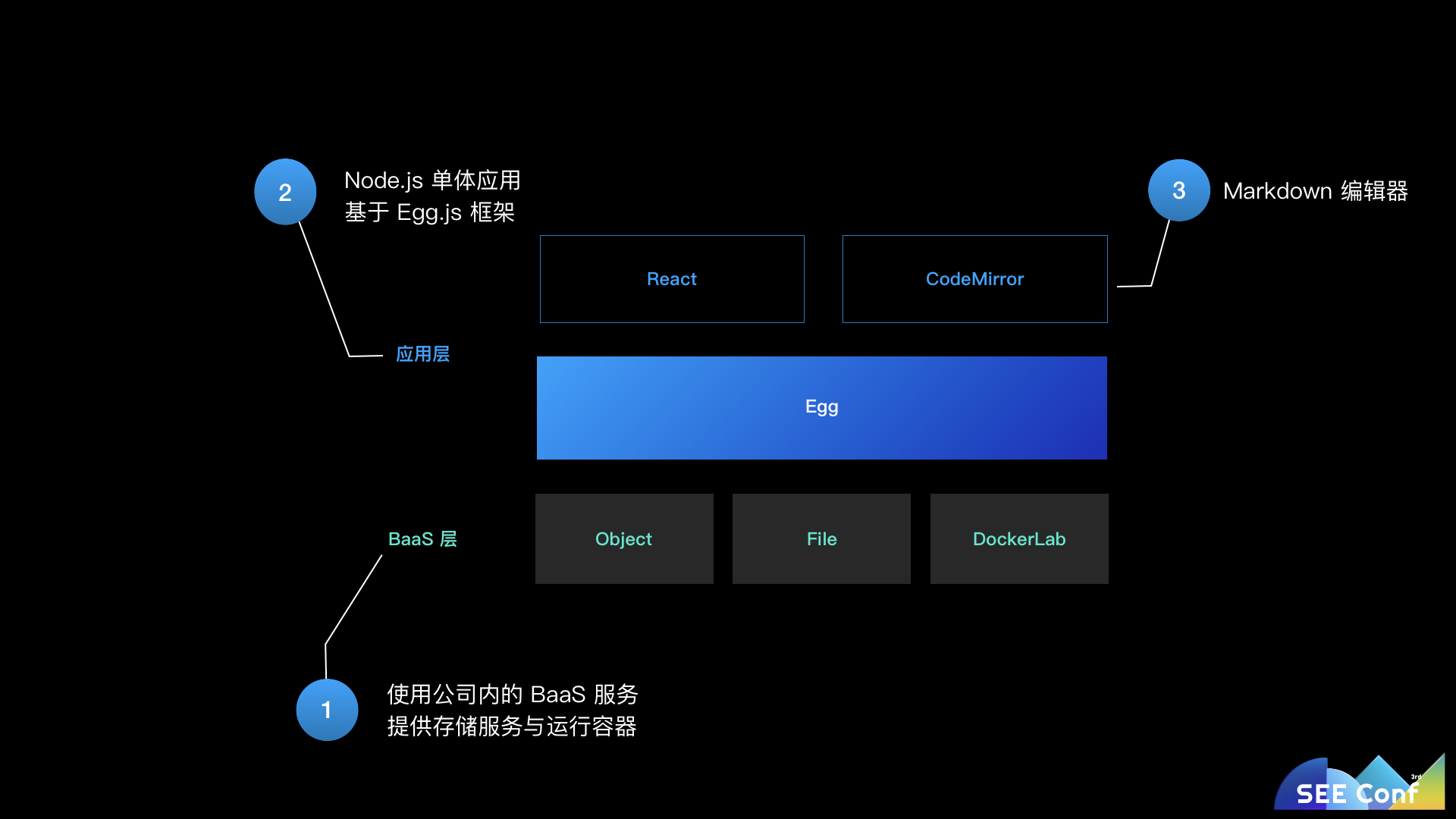
这时可以算作语雀的“原型阶段”,它仅仅是一个工程师的业余项目,采用内部专为创新应用提供的 BaaS 服务和一系列的开源技术解决方案,验证了在线文档工具这个产品原型。
PS:当时我还不在语雀团队,但是巧的是我却在给语雀提供 Object、File 等 BaaS 服务和 Egg.js Web 框架的支持。
随着在线文档工具得到了团队内部的认可,语雀的目标已经不仅仅是金融云的文档工具,而是志在替代 confluence 等竞品,成为阿里内部十万员工的知识管理平台。语雀要面向知识创作者,只提供 Markdown 编辑器肯定无法让非技术人员更高效的使用语雀。尽管有不少真爱粉因为语雀开始学习甚至爱上了 Markdown,但是我们仍然义无反顾的踏入了富文本编辑器领域的深坑。同时和 Word 等富文本编辑器不同,我们选择了更“Web”的路线,在富文本编辑器中加入了公式、文本绘图、思维导图等特色功能。而随着语雀在知识管理领域的不断探索,知识管理的三层结构(团队、知识库、文档)开始成型。在此之上的协作、分享、搜索与消息动态等功能越来越复杂单纯的依靠 BaaS 服务已经无法满足语雀的业务需求了。
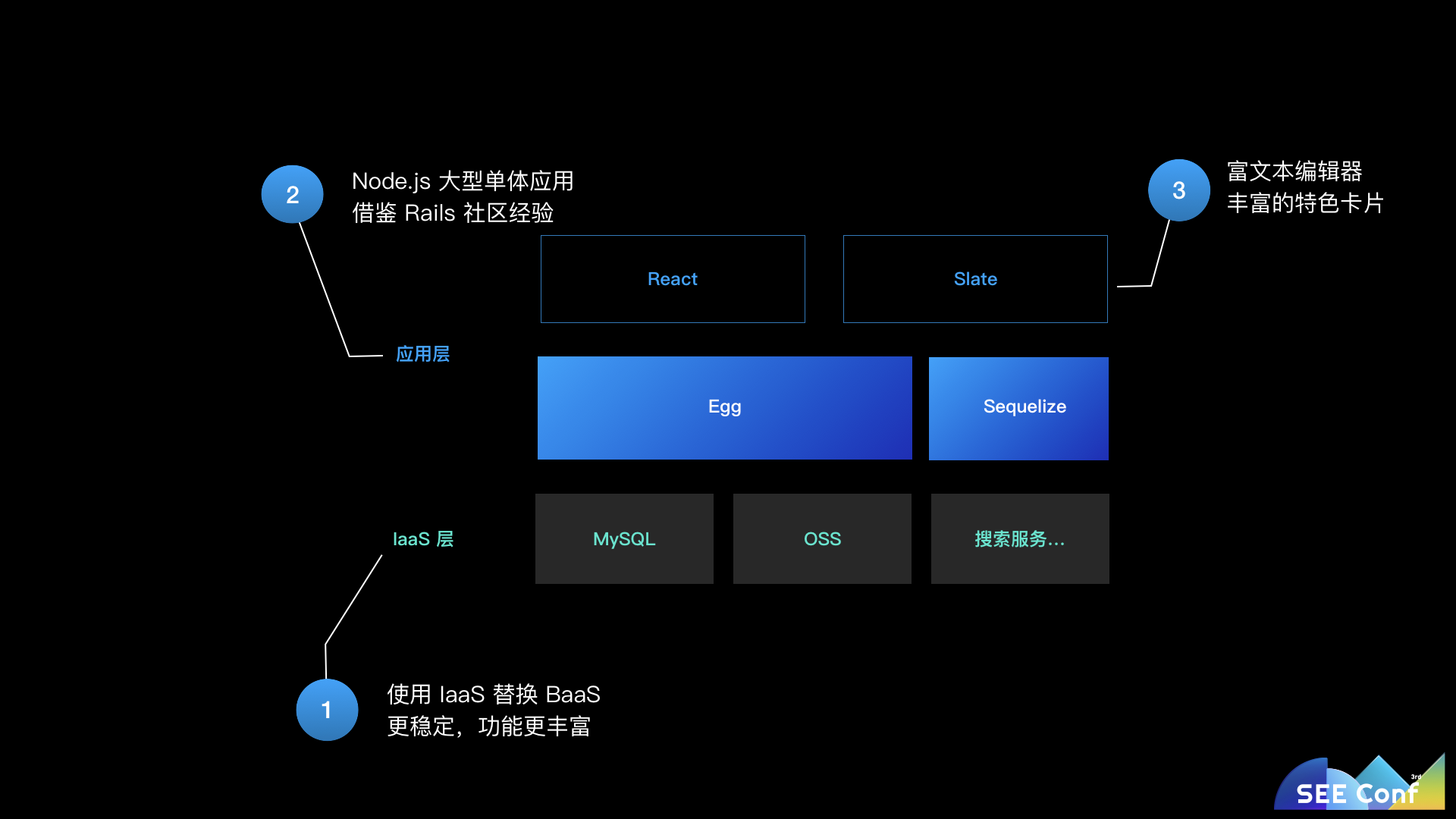
为了应对业务发展带来的挑战,我们主要从下面几个点进行改造:
在内部服务阶段,语雀已经成为了一个正式的产品,和蚂蚁的其他项目没有什么区别了,通过在阿里内部的磨炼,语雀的产品形态基本定型。
随着语雀的内部影响力越来越大,一些离职出去创业的阿里校友们开始找到玉伯:“语雀挺好用的,有没有考虑商业化之后让外面的公司也能够用起来?” 经过小半年的酝酿和重构,18 年初,语雀开始正式对外提供服务,进行商业化。
当一个应用走出公司内到商业化环境中,面临的技术挑战一下子就变大了。最核心的知识创作管理部分的功能越来越复杂,表格、思维导图等新格式的加入,多人实时协同的需求对编辑器技术提出了更高的挑战。而为了更好的服务企业用户与个人用户, 语雀在企业服务、会员服务等方面也投入了很大精力。在业务快速发展的同时,服务商业化对质量、安全和稳定性也提出了更高的要求。
为了应对业务发展,语雀的架构也随之发生了演进:
我们将底层的依赖完全上云,全部迁移到了阿里云上,阿里云不仅仅提供了基础的存储、计算能力,同时也提供了更丰富的高级服务,同时在稳定性上也有保障。
而在应用层,语雀的服务端依然还是以一个基于 Egg 框架的大型的 Node.js web 应用为主。但是随着功能越来越多,也开始将一些相对比较独立的服务从主服务中拆出去,可以把这些服务分成几类:
随着编辑器越来越复杂,在 slate 的基础上进行开发遇到的问题越来越多。最终语雀还是走上了自研编辑器的道路,基于浏览器的 contenteditable 实现了富文本编辑器,通过 canvas 实现了表格编辑器,通过 SVG 实现了思维导图编辑器。
语雀富文本编辑器相关的介绍,可以看看 Lake Editor 之父隆昊的分享:富文本编辑器的技术演进。
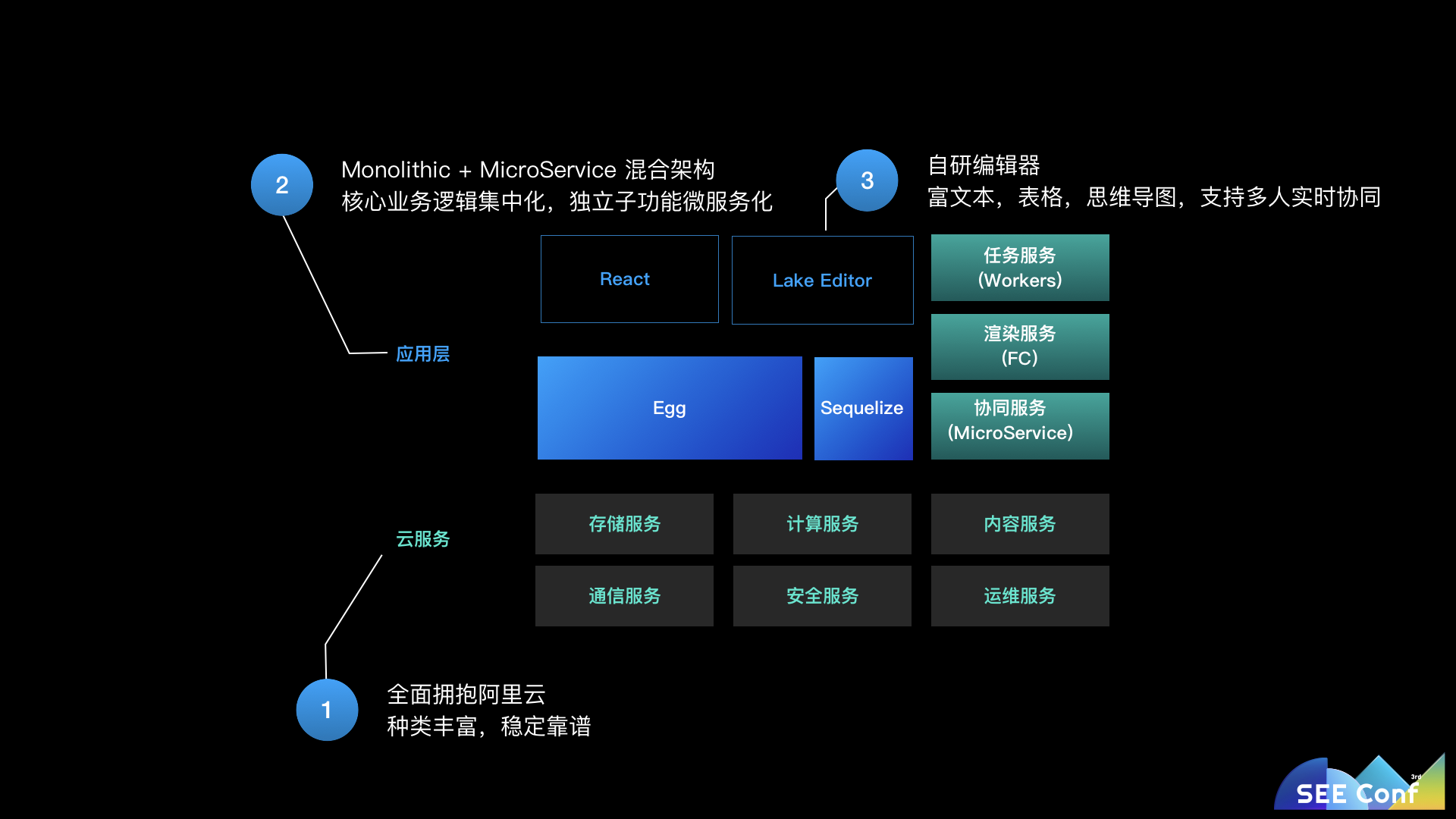
语雀的这个阶段(也是现在所处的阶段)是商业化阶段,但是我们仍然保持了一个很小的团队,通过 JavaScript 全栈进行研发。底层的服务全面上云,借力云服务打造语雀的特色功能。同时为企业级用户和个人知识工作者者提供知识创作和管理工具。
在社交网络上,大家好像对 JavaScript 全栈的看法都比较负面,“样样通,样样松”可能是大家听到全栈工程师这个名词后的第一印象。那为什么语雀选择了 JavaScript 全栈的方向呢?
在语雀,我们并不将用 JavaScript 全栈进行开发的工程师定义为全栈工程师,而是“一专多能”型的产品工程师:

在语雀,产品工程师们的产品研发流程是这样的:

语雀是如何进行全栈 JavaScript 测试的呢?感兴趣的同学可以看看语雀团队大前端自动化测试大牛达峰老师的分享:大前端测试的思考和在语雀的实践
通过 JavaScript 全栈,语雀团队可以更高效、高质量的的完成产品研发:
说到 JavaScript 全栈,有一个绕不过去的技术就是 Node.js。作为一个与前端结合紧密的服务端运行时,基本上就成为了全栈的代言人。那 Node.js 是不是真的是一个适合大型商业化项目的语言呢?大家对它都有颇多质疑:

其实随着 JS 语言的发展,许多问题已经得到了解决,例如 Async Function 的出现,可以让开发者以同步的方式编写异步代码,理解起来更简单,异常处理也变简单了。同时随着社区的进一步完善,大量高质量的工具模块、框架涌现出来。语雀的服务端部分基于 Egg 框架,已经集成了大量 Web 开发需要的模块和服务,同时基于 Async Function 编程模型也更加简单。TypeScript 的出现也打消了许多人对 JavaScript 进行大型项目开发的疑虑。除此之外,语雀还有一些其他的方式来保障代码质量和可维护性(语雀甚至是一个纯 JavaScript 项目,没有一行 TypeScript 代码)。
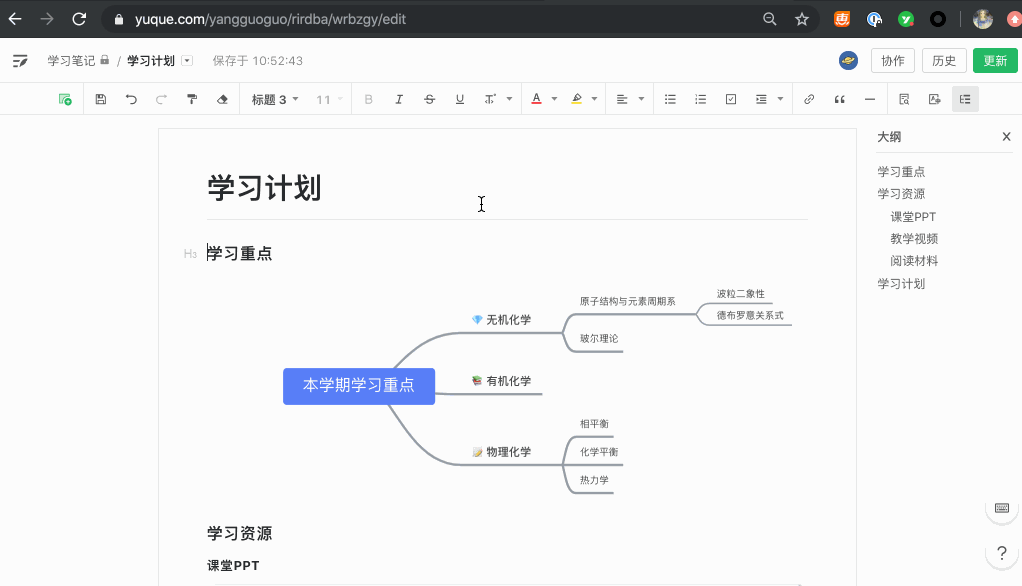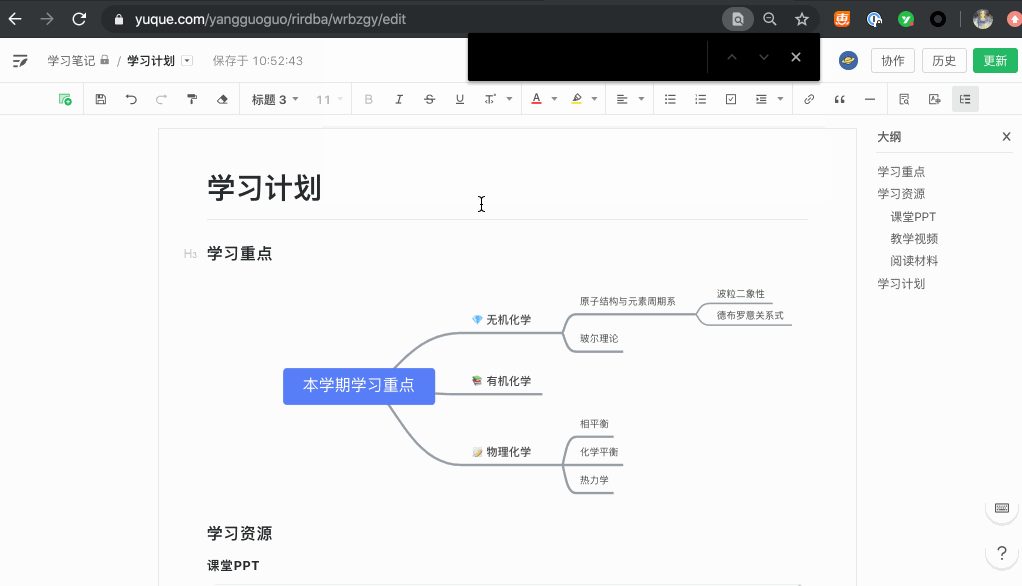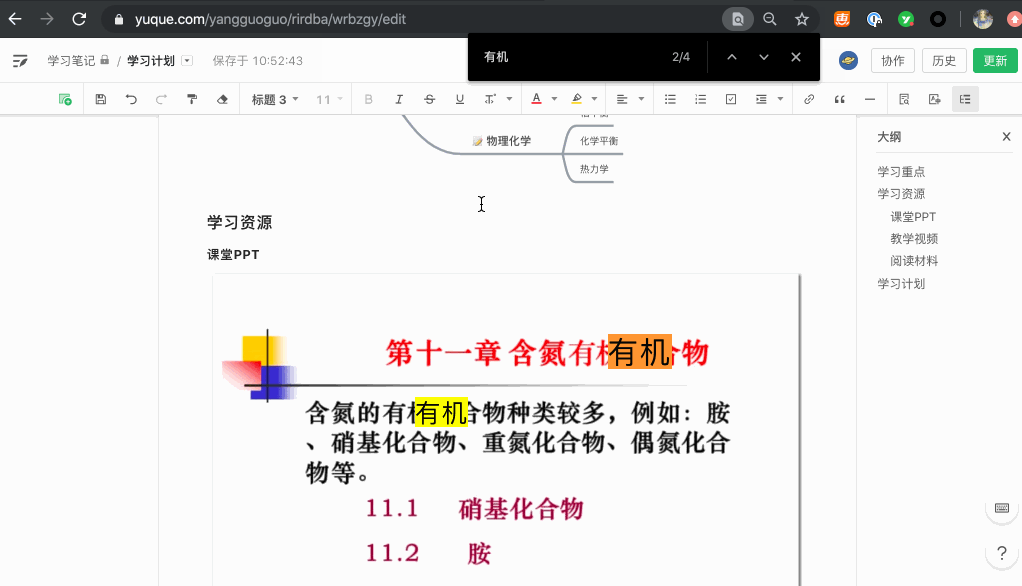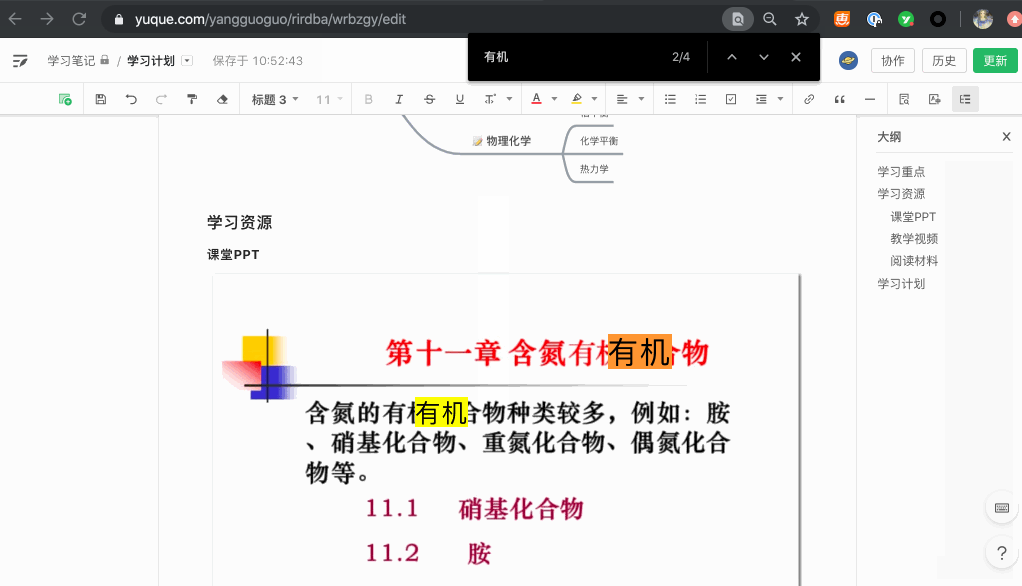
语雀做的第一件事情就是确定核心系统和外部系统的边界。通过六边形架构(也叫做端口适配器架构),我们把语雀核心系统和外界系统和用户之间的交互固定下来。通过“端口”的形式,来确定输入和输出。外部系统通过“适配器”来将系统对接到语雀暴露的端口之上,只需要按照“端口”定义来实现,外部系统可以自由替换。
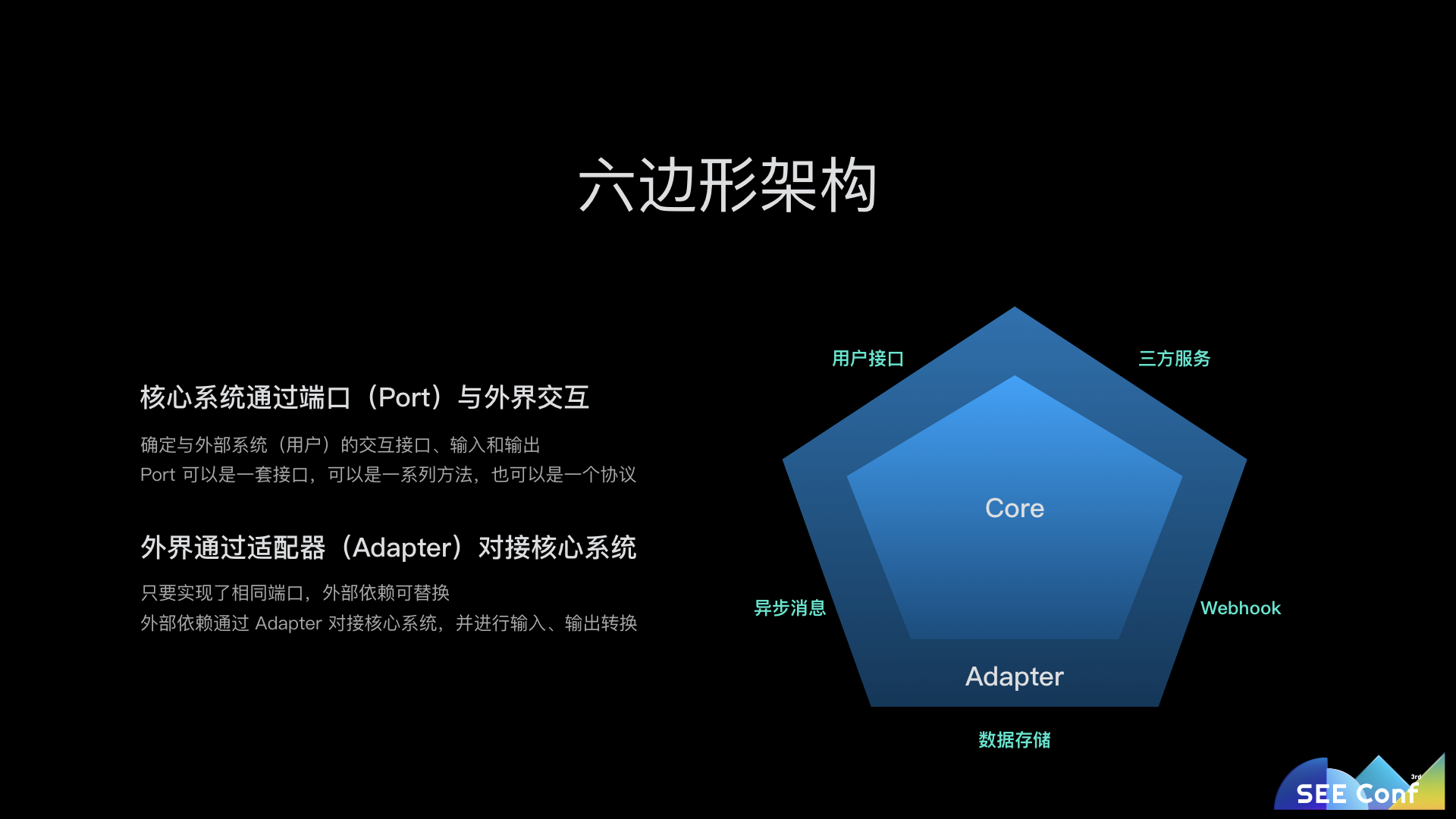
在这个模型下,Controller 就是语雀暴露给用户接口的 HTTP?适配器。在 Controller 中,我们对用户请求参数进行格式校验和转换,检查用户权限,并格式化输出。
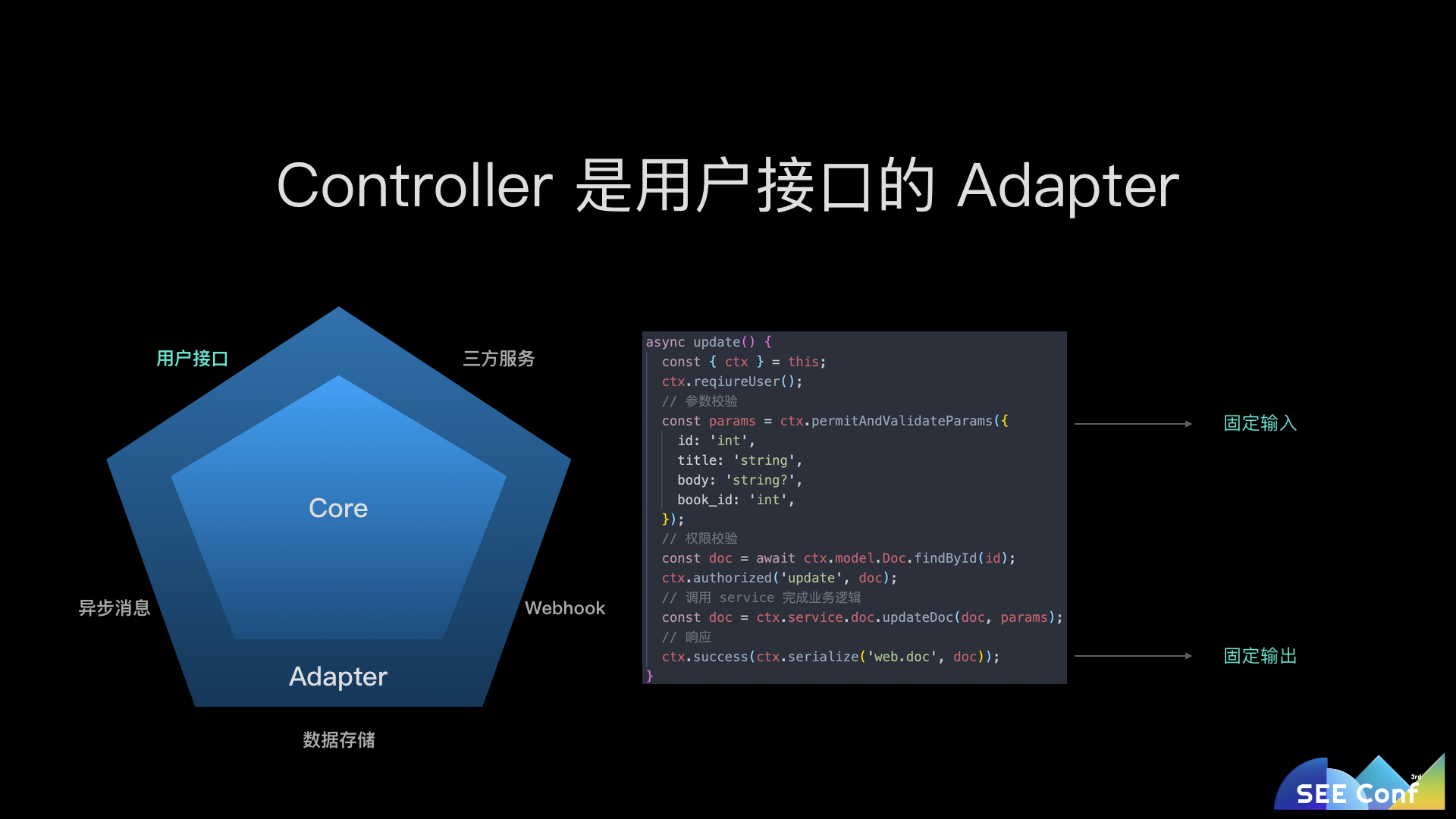
我们定义好语雀与第三方平台和服务之间的交互方式(一般是一系列方法),通过适配器,将不同环境的不同服务封装成统一的方法,并在调用时记录好调用日志。

数据模型层即是数据层的 Model,以 Doc 模型举例,它的 meta 信息数据被存储在了 MySQL 中,而文档正文数据被加密后存储在 OSS 中。对于语雀核心的业务逻辑来说,完全不感知底层的存储在哪里。更进一步来说,只要语雀是使用 SQL 和数据库进行交互,底层数据可以无缝迁移到 OceanBase 等其他支持完整 SQL 语法的数据库中,即使有少量修改也可以在 Model 层封装掉。

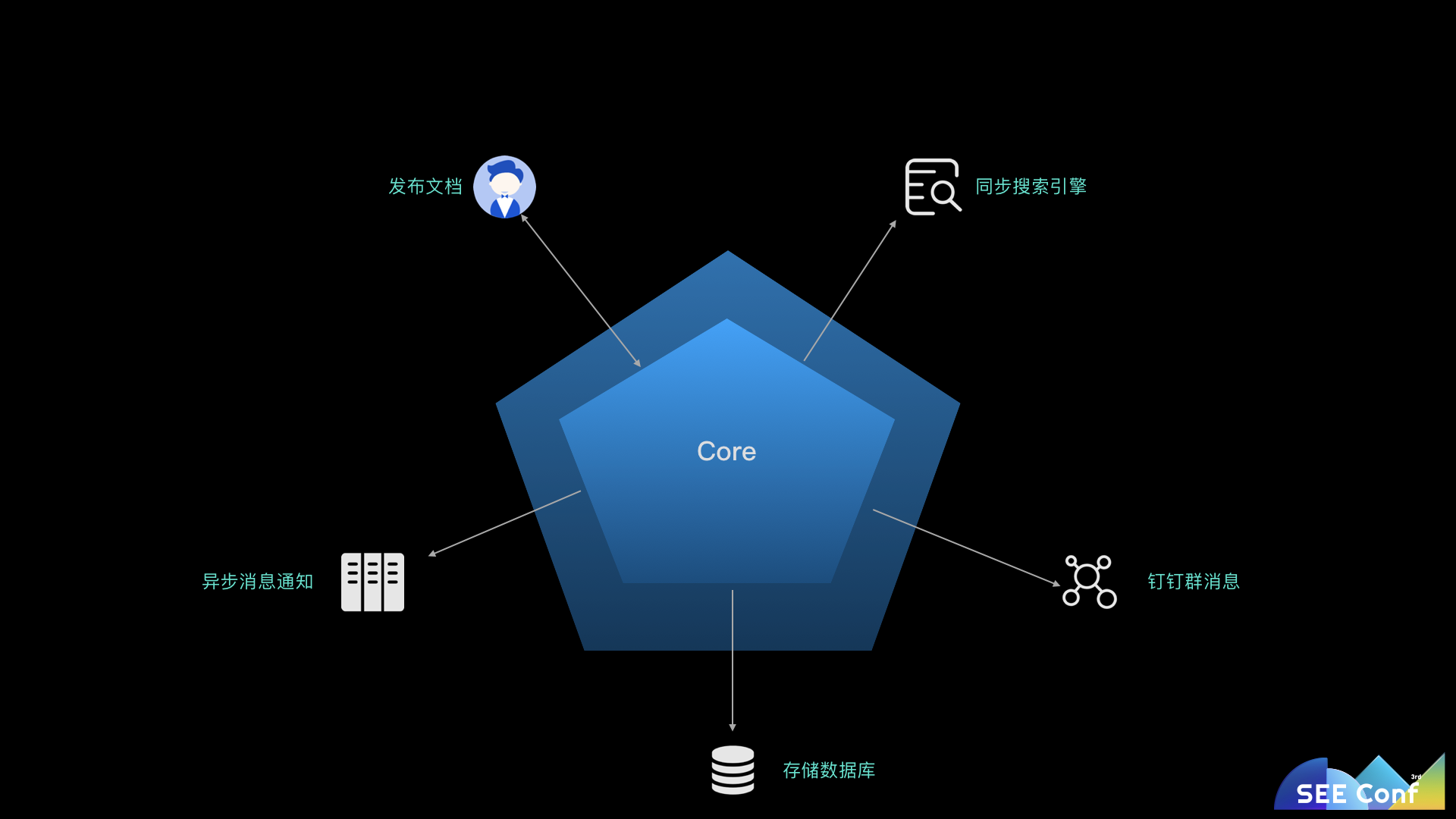
最终以一次文档发布举例,用户通过调用 HTTP 接口与语雀进行交互,数据会通过 Model 层写入到存储中,包括 MySQL 和 OSS,更新文档缓存。同时出发异步消息给其他系统,触发钉钉的 WebHook,并将数据同步到搜索引擎中。这些和外界系统的交互通过适配器封装之后各司其职,参数转换、权限校验、日志记录,不仅确保核心逻辑的精简,也让系统调用链路跟踪更加简单。
当系统发展到一定程度后,到底是应该继续在大单体应用上加功能,还是拆分成微服务呢?这两种架构既然存在,肯定有各自的优劣,具体选择那种架构形式,应该是与当前的业务规模和团队分布决定的。所以语雀的技术架构随着语雀的业务形态也变成了一个混合式的技术架构。
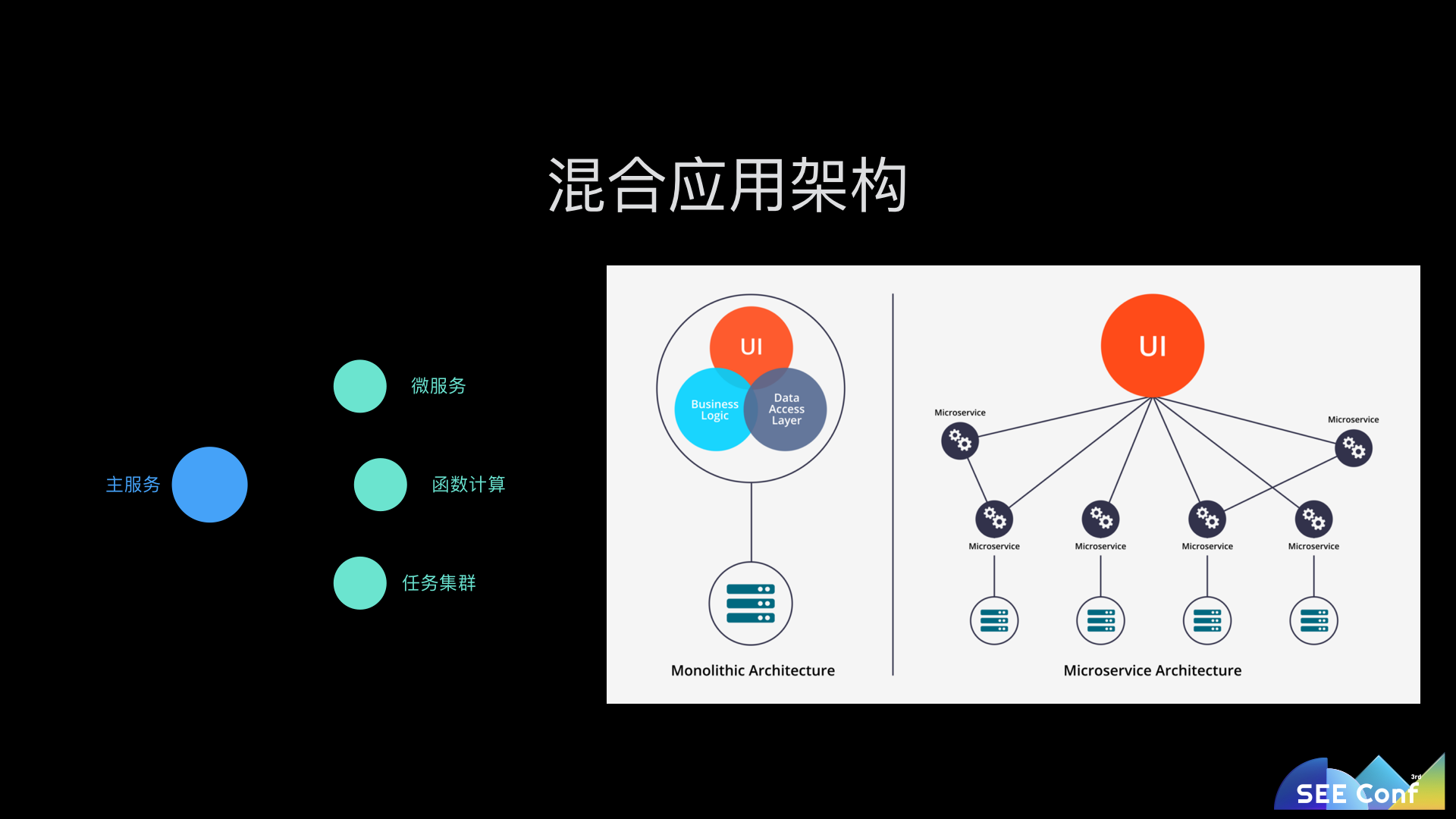
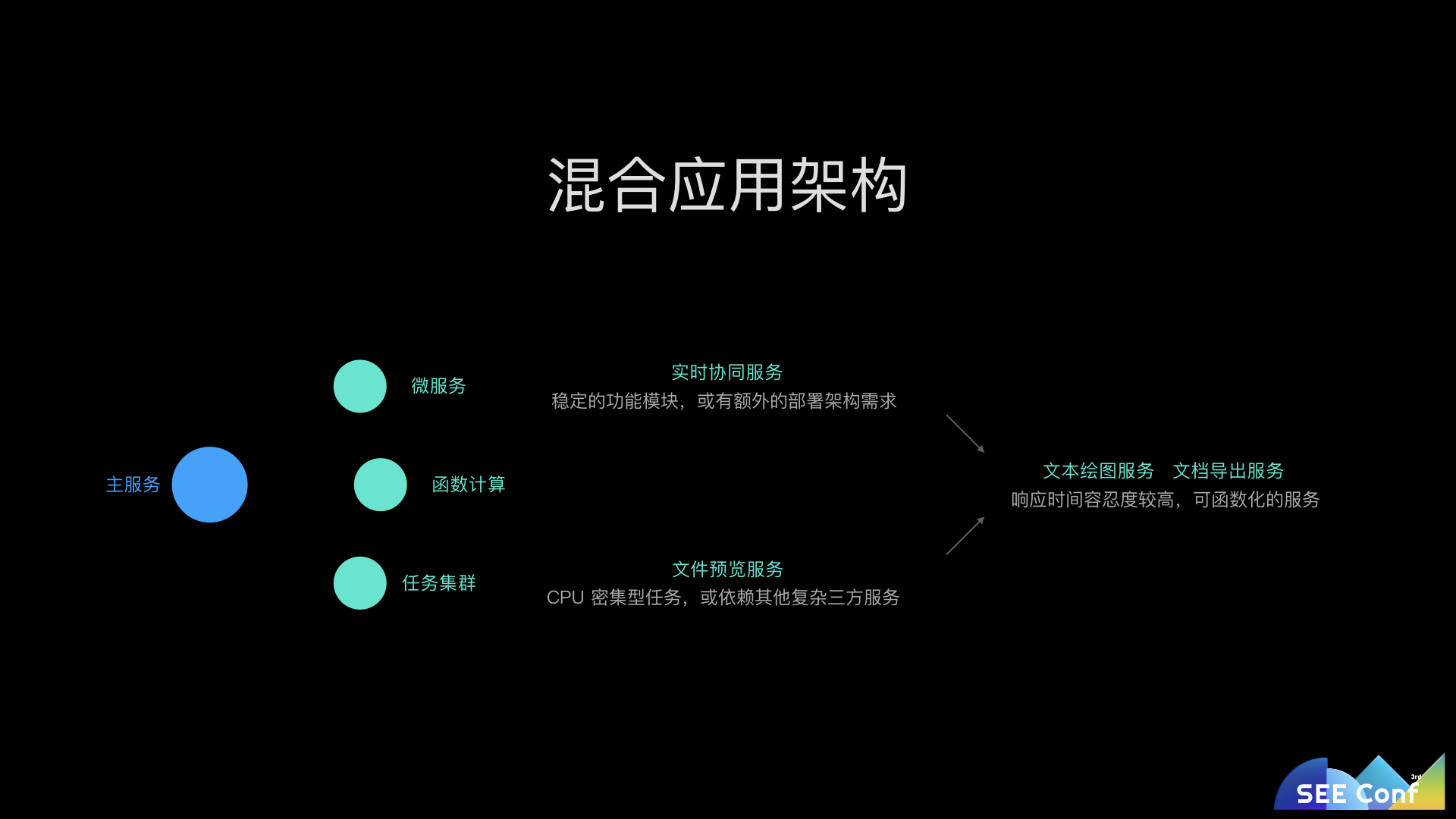
语雀的主服务是一个大型的 Node.js 服务,集中了所有的应用业务逻辑。而在主服务之外,还有一些不同形态的其他服务。
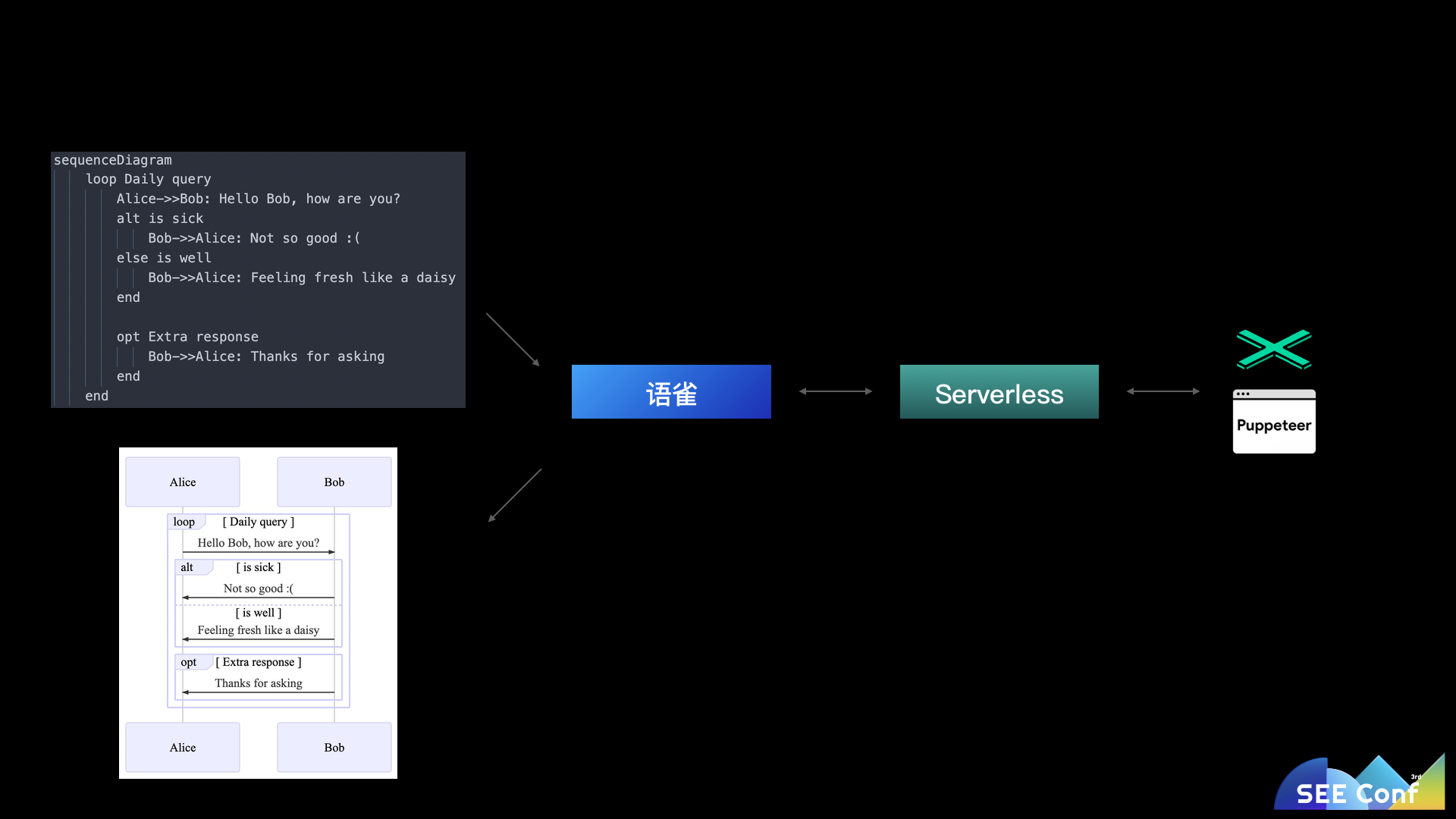
以 mermaid 的渲染举例。用户输入一段 mermaid 代码调用语雀,语雀调用一个部署在阿里云函数计算的函数,在函数中运行 puppeteer 渲染成 svg 返回。
为什么要特别把 Serverless 单独拿出来说呢?还记得之前说 Node.js 是单线程,不适合 CPU 密集型任务么?由于 Serverless 的出现,我们可以将这些存在安全风险的,消耗大量 CPU 计算的任务都迁移到函数计算上。它运行在沙箱环境中,不用担心用户的恶意代码造成安全风险,同时将这些 CPU 密集型的任务从主服务中剥离,避免出现并发时阻塞主服务。按需付费的方式也可以大大节约成本,不需要为低频功能场景部署一个常驻服务。所以我们会尽量的把这类服务都迁移到 Serverless 上(如阿里云函数计算)。
除了语言之外,任何的商业化系统还有更多需要考虑的方面,其中最重要的两点可能就是安全性和稳定性了。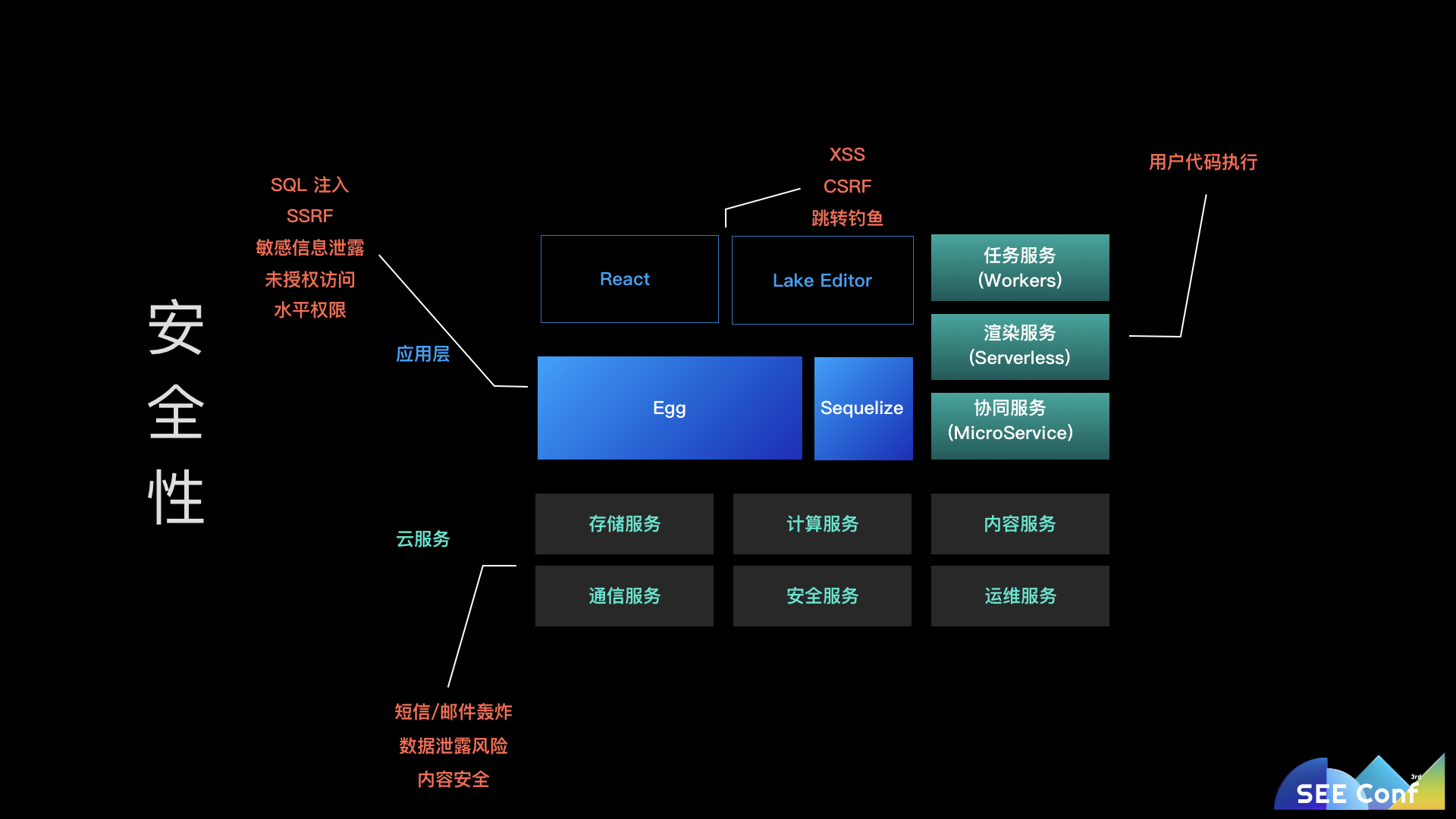
一个系统从前端、服务端到底层的依赖都存在着各种各样的安全风险:
这些安全问题想要解决基本都没有银弹,只能一个个单独处理,但是有一些基本的原则:
语雀从商业化一开始就和安全团队通力协作,从内部的安全意识培训、内部安全团队测试,到内部的红蓝***、外部的白帽子***测试,安全是一场持久战。
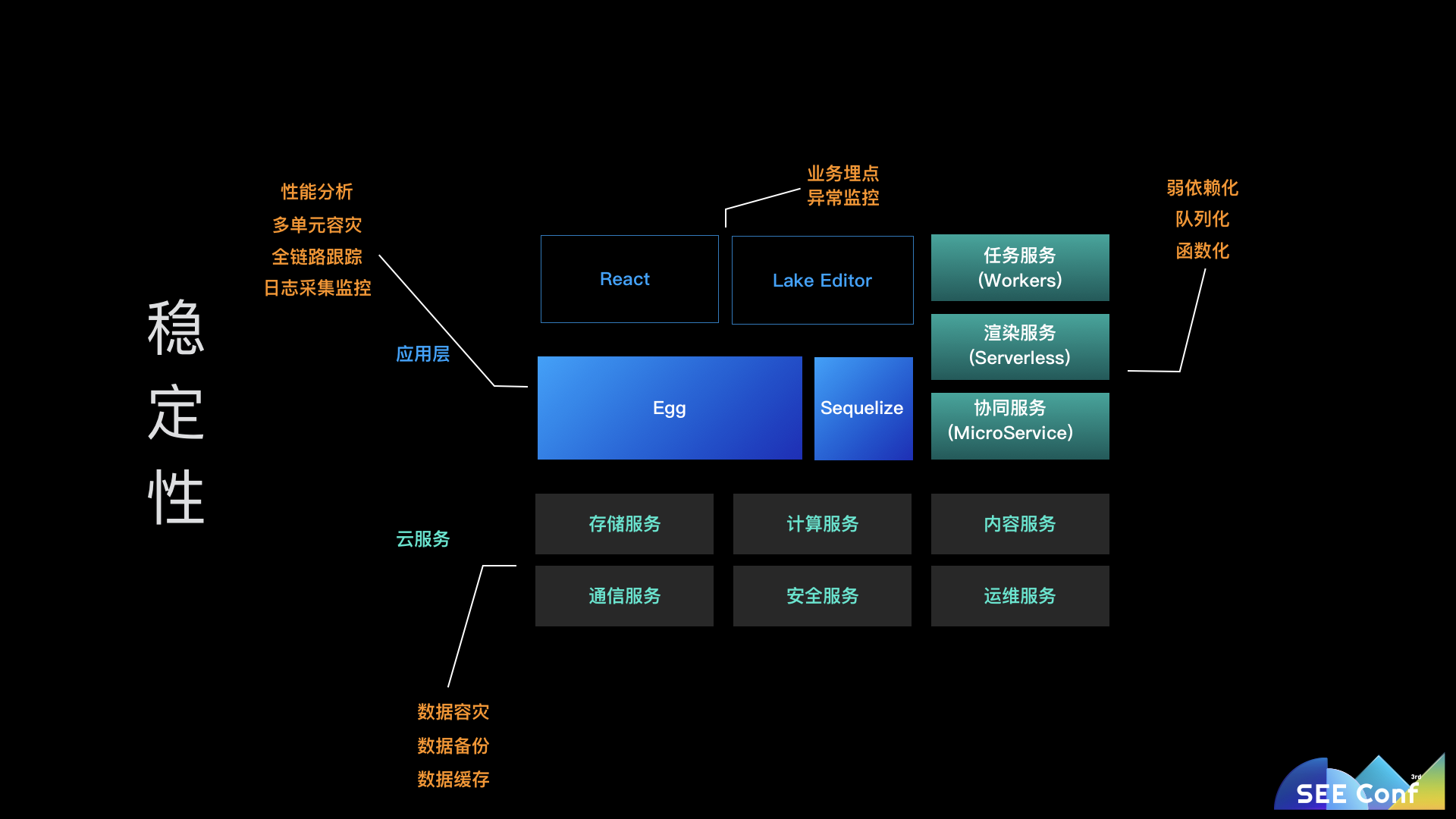
为了保障语雀的稳定性,我们从前端到服务端和云服务上都做了许多工作,和安全一样,稳定性也是一个从前到后的长期工程。语雀的稳定性保障主要在两个维度:
什么叫做避免引入不必要的强依赖呢?以语雀的场景举例,MySQL 就是一个无法去除的强依赖,而缓存不应该是一个强依赖,但是最早语雀的 session 是存储在缓存(Redis)中的,一旦 Redis 集群出问题,用户资料无法获取就导致用户无法登录。这就把缓存变成了一个强依赖。所以我们将 session 存储放到了 MySQL 中,Redis 就变成了一个弱依赖,它挂了系统还能正常运行。另一个例子,语雀前段时间上线了多人实时协同编辑的功能,而在这个功能上线之前,是通过文档加锁的方式避免多个人同时编辑同一篇文档的。然而多人实时协同引入了另一个服务,一旦实时协同服务挂了,用户就无法编辑文档了,它又变成了语雀系统的一个强依赖,为了解决他,我们在用户连接协同服务失败的时候,自动切换到老的锁模式。这样协同服务也变成了语雀的一个弱依赖。

语雀这几年一步步发展过来,背后的技术一直在演进,但是始终遵循了几条原则:
“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”
“云”端的语雀:用 JavaScript 全栈打造商业级应用
标签:带来 拆分 有一个 reac final redis 集群 mongo 覆盖 安全性
原文地址:https://blog.51cto.com/13778063/2466763