标签:partition 存在 nap 高效 内存数据 很多 server 判断 重复
Hekaton是内存数据库,以往的数据库都是基于磁盘构建的,
但是当前硬件的发展,已经可以将很多应用的数据整个放到内存中,所以需要新的架构,基于超大内存和多核CPU的数据库架构
当前目标是把Sql Server的性能提升100倍
那么提升的办法,一般有3种,提升scalability,提升CPI,或降低指令数
比较可行的方法是降低指令数,如果性能提升100倍,那么就要把99%的指令给优化掉
这个在当前现有的方案上是无法实现的

为了达到上面的目的,在架构上有3个主要的改进
传统的面向磁盘的数据库,会有非常复杂的bufferpool机制,这样会消耗大量的指令,一个简单的key查询,就需要几千个指令
而如果是面向内存,就不需要bufferpool这个一整套机制,可以设计出针对内存优化的索引结构

原先数据库中的锁成本非常的高,
所以要解决的第二个问题就是无锁,
主要是通过,MVCC,乐观并发控制,latch-free的数据结构来实现无锁

传统的数据库的基于解释器的执行机制
这里会将SQL转化为高效的machine code,进行执行,这里主要是指会反复执行的SQL,比如存储过程,只有编译一次,执行多次,才会有性能提升


Hekaton这里做的一个设计,很有意思
当前一般为了提升并行度,都会把数据做patition,这个和是不是分布式没有关系,单机也有基于cpu core的线程并行度
Hekaton说我不做partition,因为partition是双刃剑,如果你按照分区键进行查询肯定会快,但是你如果不按分区键,就会很慢;说白了分区是对于数据查询有了个先验假设,如果假设不成立,那么就是不合理的
对于内存数据库,也不存在磁盘库的,要分区来提升每块盘的io效率,所以选择不分区也是可以接受的

先看下索引部分
Hekaton的索引是完全基于内存的,两个索引,都是latch-free的结构
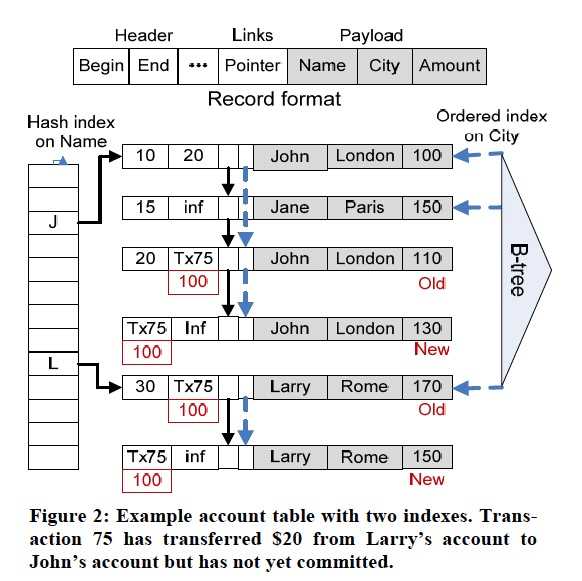
每个record分3部分,
Header,关键是,begin,end,分别表示这个record的生命周期,即创建和删除时间
Links,一系列的links,索引会用到,每个索引用一个link列
数据,payload,这里三个字段,name,city,amount
Hash索引是基于name建的,B树是基于city建的,当然这里你可以建立更多的索引
例子中很明显,一个索引对应的record不止一个,那么这个时候link列就有用了,从record的link列可以找到这个索引项对应的下一个record


Reads
很直觉,你需要给一个logical的read time,你只能读到包含read time的那个版本

对于写的过程,就是先把旧新的end,begin替换成Transaction id
然后在commit的时候,用commit time来替代Transaction id

上面这块是Hekaton的核心,
因为他讲了绝大部分上面提到的技术,latch-free的数据结构,MVCC,基于内存的索引实现,关于提升编译和执行效率那块,我直接跳过了
剩下关键的,就是如何保证MVCC是serializable
MVCC一般都提供SI的隔离性,SI不是serializable的
因为serializable要求,读写在逻辑上同时发生
而SI明显不是,读是在产生Snapshot的时候,写是在commit的时候
那如果要做到serializable,方法也很直觉,那就是虽然读写不同时,但是如果可以保证,我在commit的时候,之前读到的内容没有改变,那就等同于读写同时
所以只要做到,可重复读,无幻读

这个过程,就是乐观并发控制中的,validation的过程,这个详细可以看andy的数据库课程
关键是,你要记录下,read set和scan set,然后在commit的时候,去check这些读过的数据

后面两个问题,是内存数据库特有的
第一个是持久化,内存的数据,不能说丢就丢了
持久化的方法,首先,Transaction log,这个和wal有些不同,是在commit的时候去记录一条log,但是如果要提升效率,还是要batch commit

再者,就是checkpoints,缩短恢复周期

第二个是GC,回收内存,不能内存就爆了
GC比较有参考意义的是,它如何判断哪些version可以被过期了


这篇文章的参考意义,在于他把内存数据库的方向,和碰到的问题还是说的比较清晰的
Hekaton: SQL Server’s Memory-Optimized OLTP Engine
标签:partition 存在 nap 高效 内存数据 很多 server 判断 重复
原文地址:https://www.cnblogs.com/fxjwind/p/12198117.html