标签:分析 div kmeans 变化 ret 核心 图片 input ash
一、 环境:
二、 问题:
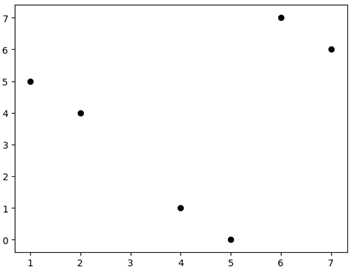
对六个样本点[1, 5], [2, 4], [4, 1], [5, 0], [7, 6], [6, 7]进行K-means聚类。
三、 理论推导
此处依照我个人理解所写,错误之处欢迎指出
K-means核心操作为:聚类中心选取—分类—调整聚类中心—再次分类并调整聚类中心直到调整幅度小于阈值或程序运行轮数大于阈值
四、 代码实现
代码主要用于理解算法,有些地方可能不够严谨,还请轻喷??????
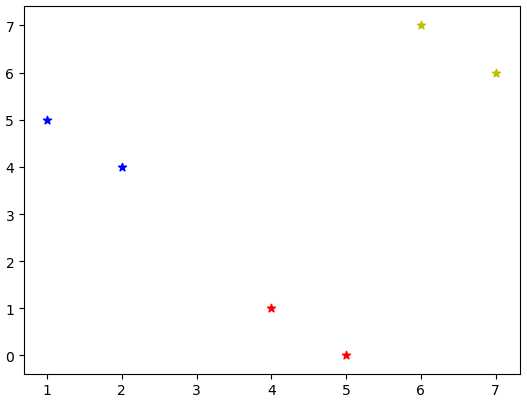
因为样本点较少,所以俩个算法运行结果相同,读者可自行增加样本检测
K-means:
1 # kmeans input_data为待分类数据,k为分类类别数 2 def myKmeans(input_data, k): 3 # region 选择类中心 4 index_cls = [] 5 while index_cls.__len__() < k: 6 n = np.random.randint(0, input_data.shape[0], 1) 7 if n not in index_cls: 8 index_cls.append(n[0]) 9 point_cls = input_data[np.array(index_cls)] # piont_cls为选好的三个聚类中心 10 # endregion 11 # region 更新样本点类型 12 # tag_sample = [-1 for i in range(input_data.shape[0])] # 六个样本点的标签 13 while True: 14 # 计算样本点到聚类中心的欧式距离平方(无需开根号) (x1-x2) ** 2 + (y1 - y2) ** 2 15 # axis = 0 为按行取值,axis = 1 为按列取值 16 dis_cls = np.array([np.sum((input_data - i) ** 2, axis=1) for i in point_cls]) # 计算六个点距离三个聚类中心的值,三行六列 17 # 0: 1 2 3 4 5 6 18 # 1: 6 5 4 2 3 4 19 # 2: 4 4 5 3 4 5 20 # 选取每一列最小值索引作为这个样本点的距离 21 min_tag = np.argmin(dis_cls, axis=0) # 选取每一列的最小值(即最小距离),为本次计算样本点的tag 22 # endregion 23 24 # region 计算新类中心 25 new_piont_cls = np.array(list([np.average(input_data[min_tag == i], axis=0) for i in range(k)])) 26 # endregion 27 28 # region 计算新类中心的样本类别,做判断,若类别有变化,则更新类别,若不变化,结束算法 29 # 比较俩个类的中心是否满足一定条件(一般算和小于一定的值) 30 gap = np.sum((new_piont_cls - point_cls) ** 2) # 若样本点改变值和小于1,则表示分类结束 31 if gap < 1: 32 break 33 else: 34 point_cls = new_piont_cls 35 # 可以比较样本的类别变化,若样本类别无变化,则停止 36 # endregion 37 return min_tag # 返回input_data分类(0,1,2) 三类
K-means++:
1 # kmeans++ input_data为待分类数据,k为分类类别数 2 def myKmeanspp(input_data, k): 3 # region 选择类中心 4 # 选取相距距离最远的点作为聚类中心 5 point_cls = [list([np.random.randint(0, input_data.shape[0]), 1])] 6 # 计算第二个点,即获取离选好的类中心点最远的点 7 while point_cls.__len__() < k: 8 dis = np.array([sum((input_data[j] - point_cls[i]) ** 2 for i in range(point_cls.__len__())) for j in 9 range(input_data.__len__())]) 10 sample_dis_cls_min = np.min(dis, axis=0) 11 index_max_dis_sample = np.argmax(sample_dis_cls_min) 12 point_cls.append(list(input_data[index_max_dis_sample])) 13 point_cls = np.array(point_cls) 14 # endregion 15 # region 更新样本点类型 16 # tag_sample = [-1 for i in range(input_data.shape[0])] # 六个样本点的标签 17 while True: 18 # 计算样本点到聚类中心的欧式距离平方(无需开根号) (x1-x2) ** 2 + (y1 - y2) ** 2 19 # axis = 0 为按行取值,axis = 1 为按列取值 20 dis_cls = np.array([np.sum((input_data - i) ** 2, axis=1) for i in point_cls]) # 计算六个点距离三个聚类中心的值,三行六列 21 # 0: 1 2 3 4 5 6 22 # 1: 6 5 4 2 3 4 23 # 2: 4 4 5 3 4 5 24 # 选取每一列最小值索引作为这个样本点的距离 25 min_tag = np.argmin(dis_cls, axis=0) # 选取每一列的最小值(即最小距离),为本次计算样本点的tag 26 # endregion 27 28 # region 计算新类中心 29 new_piont_cls = np.array(list([np.average(input_data[min_tag == i], axis=0) for i in range(3)])) 30 # endregion 31 32 # region 计算新类中心的样本类别,做判断,若类别有变化,则更新类别,若不变化,结束算法 33 # 比较俩个类的中心是否满足一定条件(一般算和小于一定的值) 34 gap = np.sum((new_piont_cls - point_cls) ** 2) # 若样本点改变值和小于1,则表示分类结束 35 if gap < 1: 36 break 37 else: 38 point_cls = new_piont_cls 39 # 可以比较样本的类别变化,若样本类别无变化,则停止 40 # endregion 41 return min_tag
python-Kmeans\Kmeans++算法理解及代码实现
标签:分析 div kmeans 变化 ret 核心 图片 input ash
原文地址:https://www.cnblogs.com/FSeng/p/12199333.html