标签:执行命令 源程序 科学技术 一起 二进制文件 天下 内存数据 路径 问题:
在上篇博客中简单的介绍了8086汇编语言。工欲善其事,必先利其器,在8086汇编语言正式开始学习之前,先介绍一下如何搭建8086汇编的开发环境。
汇编语言设计之初是用于在没有操作系统的裸机上直接操作硬件的,但对于大部分人来说,在8086裸机上直接进行编程将会面临各种困难。好在我们可以使用软件模拟器来模拟硬件进行8086的学习实践。在《汇编语言》中作者推荐通过windows环境下的masm和debug进行学习。
masm介绍:
masm是一款DOS下的汇编工具包,在8086汇编的学习中我们需要其中的几个文件,分别是masm.exe,link.exe。
masm.exe 汇编器,用于将文本格式的汇编语言源文件编译为.obj结尾的二进制文件,其生成的.obj结尾的二进制目标文件是被编译的源文件的对应的机器码。单独的源程序目标文件通常是无法直接运行的,还需要和互相依赖的其它同样编译完成的二进制文件链接在一起才能生成最终的可执行文件(比如所需要的静态库函数) 。因此,obj文件通常也被叫做中间文件。
link.exe 链接器,obj文件需要通过链接才能转换成可执行程序,而链接器就是负责完成这一任务的。链接器能将多个obj目标文件以及其所依赖的库程序进行统一处理(例如多个目标文件中指令、数据内存地址的偏移处理),并生成可执行文件。
debug介绍:
debug.exe 调试器,windows提供了一个在dos中调试8086汇编程序的工具debug.exe,提供了展示程序运行时CPU中各寄存器、内存中数据,指令级的单步调试等功能。debug程序的使用会在本篇博客的后半段进行详细介绍。
由于《汇编语言》一书出版较早,当时的windows系统还是32位的,32位windows系统都默认安装了masm与debug,能打开dos窗口直接使用。但目前普遍使用的、新的windows 64位操作系统中却并没有默认提供masm工具包和debug.exe,同时masm、debug也与64位的windows系统版本不兼容。
想在64位的windows系统下使用masm、debug有两个常用方法:
1. 通过虚拟机安装一个老版本的windows操作系统(推荐windows xp)
2. 通过DOSBox这一轻量级的ms-dos模拟器来运行,但上文所述的依赖程序需单独下载(百度网盘下载链接:https://pan.baidu.com/s/158NKJoea6_Y4UmCFsDP0oQ#list/path=%2F)
个人推荐第二种方法,下面介绍如何在windows64位操作系统下使用DOSBox来搭建8086汇编语言的开发环境。
DOSBox下载安装:
DOSBox可以在官网下载,这里也提供了百度网盘的下载链接(0.74版本):https://pan.baidu.com/s/11_GcPpTqJm78N8xEXZpPMw。
安装完毕后,找到安装目录下的DOSBox.exe并启动,能看到如下图界面。
作为dos的模拟器和普通的dos窗口没有明显区别,但是初始时并不能直接访问到本地磁盘,需要先将本地磁盘挂载到DOSBox中。
DOSBox挂载本地磁盘:
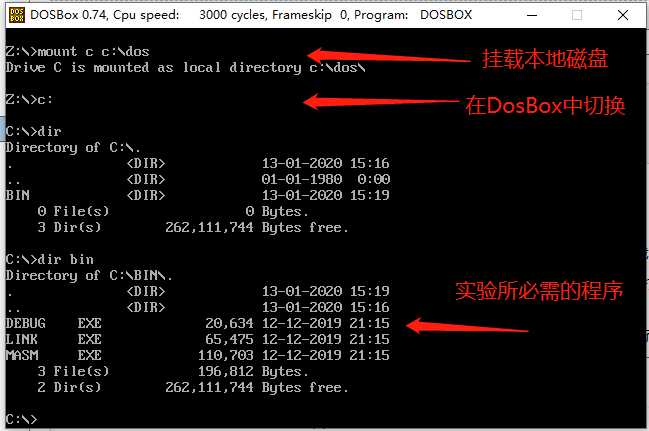
1. 在本地操作系统磁盘上选择一个文件夹目录,作为挂载的磁盘路径(例如C:\dos)
2. 在DOSBox启动的dos窗口中执行命令:mount C C:\dos(代表着将本地的C:\dos路径挂载到DOSBox的C盘路径下),能把dos窗口的工作目录切换到C盘,接下来就可以正常访问被挂载的磁盘路径下的内容了。
3. 将前面提到过的debug.exe等文件都放在这个挂载的本地磁盘路径下(例如C:\dos),通过DOSBox就可以兼容的运行masm工具包中的程序和debug.exe了
添加自动执行脚本以避免重复操作:
由于上述DOSBox的磁盘挂载是临时的,每次重新启动DOSBox后都需要重新输入命令进行挂载,太麻烦了。我们可以通过修改DOSBox配置的方式,免去这些重复的操作。
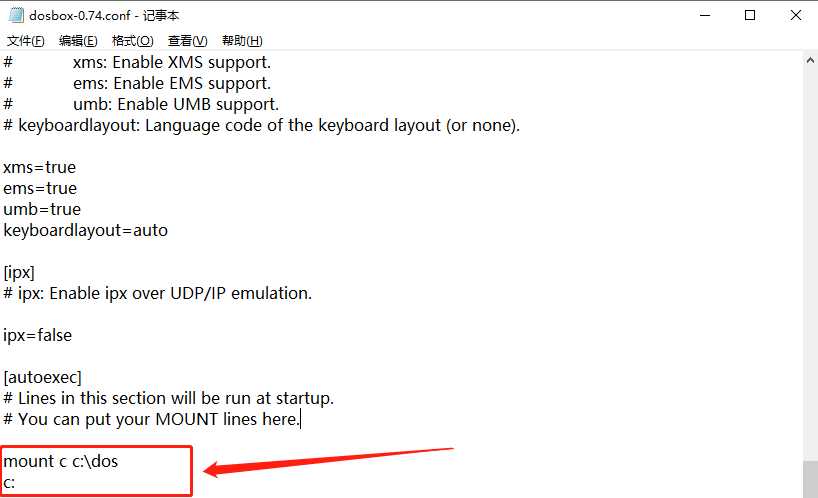
找到DOSBox安装目录下的DOSBox 0.74 Options.bat,使用系统自带的记事本直接打开,暂不研究其它配置段的作用,找到最后的【autoexec】段,配置在【autoexec】的内容会作为命令在DOSBox启动时按顺序被自动执行。
将挂载磁盘操作命令配置在【autoexec】段中能避免重复操作。修改并保存配置文件后,重新启动DOSBox,发现配置中添加的命令会被自动执行。
在搭建好了8086汇编的开发环境后,接下来介绍8086的debug模式。执行debug.exe以进入debug调试模式,在dos中通过输入命令的方式进行交互。
debug模式下有20多种不同命令,限于篇幅这里只会介绍几个以后实验时常用到的命令。(通过回车执行命令,DOS下的命令默认是不区分大小写的)
R命令的作用是查看和修改debug模式下CPU中寄存器的值。
(-r) 单独的输入r,可以查看当前CPU的内容
(-r 寄存器名) r加上寄存器名可以在接下来的":"提示后输入新的值,以达到修改对应寄存器内容的目的(示例中第二行 AX 0000表示修改前寄存器AX的值为0000) 
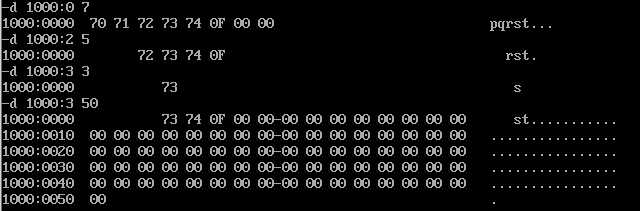
D命令的作用是查看内存中的内容。
D命令有许多不同的传参方式可供使用,先介绍最易理解的(段地址:偏移地址)查看方式。D命令默认会显示寻址地址开始的后128个内存单元的内容,以16进制的方式显示(每个内存单元8位,一行最多16个内存单元),而最右边会将内存单元中的二进制数据以ascll码的形式翻译展示。

有时,我们只想聚焦于某一部分内存地址的内容,而默认展示的内存视图不是很方便。
D命令提供了另外一种访问内存的方式(段地址:偏移起始地址 偏移终止地址),其能够展示(段地址:偏移起始地址 至 段地址:偏移终止地址)的内存信息,范围两端均为闭区间。
E命令的作用是改变内存中的内容。
和对CPU中寄存器的查看,修改不同,对内存进行查看和修改较为复杂,为此debug设计了两个不同的命令分别进行控制(E命令修改内存、D命令查看内存)。
通过(E 起始地址 数据1 数据2 数据3...)命令可以修改内存中以起始地址开始,顺序的N个内存单元的值(N为实际参数传递的数量)。
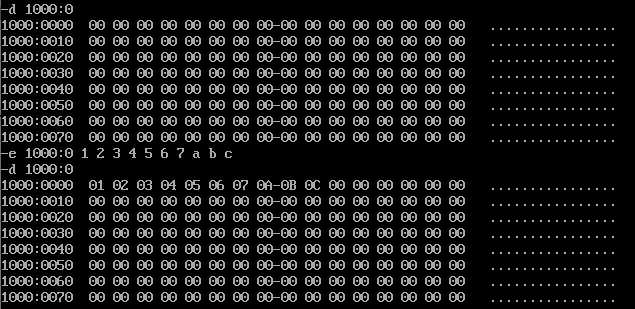
也可以和R命令修改CPU中寄存器值类似的,通过提示来修改特定内存单元的值。00.12 00代表内存单元在修改前的值,12是我们手动输入的、需要修改的新值。

可以通过E命令向内存输入对应的机器指令,因为机器指令也是数据的一种。
有以下指令(左侧为机器码,右侧为对应的汇编指令):
B80100 mov ax,0001
BB0200 mov bx,0002
01D8 add ax,bx
我们可以向内存1000:0处写入这些机器指令,以供接下来通过debug执行这段机器指令 (执行命令:E 1000:0 B8 01 00 BB 02 00 01 D8)。
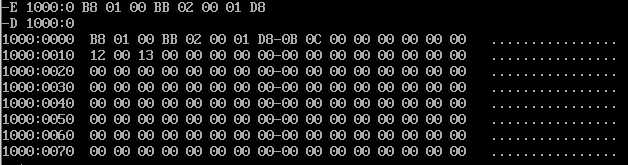
U命令的作用是将内存中的二进制数据转换为汇编指令展示(反汇编)。
D命令能够将内存中的数据以16进制或ascll码的形式展现出来,但有时我们需要观察的是内存中的机器指令时,D命令的视图过于抽象,不利于理解。debug提供了U命令来解决这个问题。
对于前面我们在1000:0处输入的机器指令,使用 U 1000:0 命令(u 内存地址)可以将内存中的数据以汇编语言指令的方式进行展示。
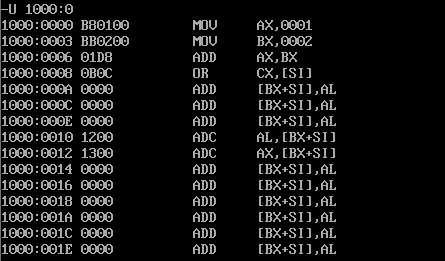
可以观察到,左边展示的是内存地址,中间则是16进制的内存视图,右边展示的是内存中数据所对应的汇编指令(例如: 1000:0000;B80100;MOV AX,0001)。
由于我们只输入了三条汇编指令,而后面内存中的数据并不是我们想要执行的,但U命令却依然将其以汇编指令的形式转换并显示出来了。
这也是前一篇博客所提到的,内存中的数据完全是二进制的,既可以将其看做普通的二进制数据、十六进制数据、ascll码文本数据,也可以视作程序指令,这些二进制的"数据"的处理完全取决于如何对其进行解释。
T命令的作用是进行单步机器指令的调试
以上文通过E命令写入内存1000:0的三条指令举例,介绍如何使用T命令来让CPU执行1000:0处的机器指令。T命令用于单步调试,一次只会执行一条机器指令。
8086CPU在运行时会将CS:IP寄存器所指向的内存单元中的内容解释为指令执行,要将内存1000:0处的内容作为指令执行必须先修改CS、IP两个寄存器的值,使之指向1000:0。
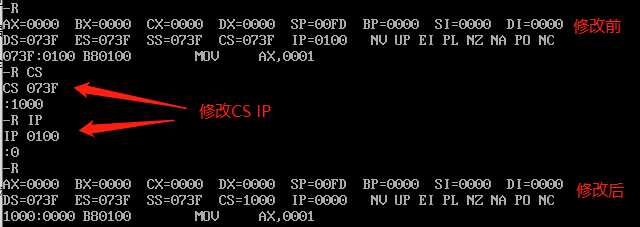
先执行一次T命令,1000:0处的指令(mov ax,0001)便会被执行,可以观察到寄存器ax的值已经变成了0001;同时寄存器IP的值增加了3(mov ax,0001的指令长度为3),此时CS:IP指向的便是位于1000:3处的下一条指令(mov bx,0002),在视图的最后一行中也有所体现。

再执行一次T命令,会执行1000:3处的指令(mov bx,0002),可以观察到寄存器bx的值变成了0002;寄存器IP的值又增加了3(mov bx,0002的指令长度也是3),此时CS:IP指向的便是位于1000:6处的下一条指令(add ax,bx)。

最后执行一次T命令,add ax,bx会被执行(类似 ax=ax+bx)。寄存器ax的值已经变成了之前寄存器ax和bx中的数据之和0003;寄存器IP的值增加了2(add ax,bx的指令长度是2),CS:IP指向1000:8。

A命令能够以汇编指令的形式向内存中写入内容
对于内存操作,D命令可以查看内存中的内容,但如果想查看的是程序指令,显然U命令更加方便;E命令可以向内存中写入数据,但对于程序指令的写入,直接操作二进制机器码的方式过于硬核。为此,debug提供了A命令,我们可以通过A命令以汇编指令的形式向内存中写入内容。
通过A命令将(mov ax,0001,mov bx,0002,add ax,bx)三条指令写入内存1000:0处:
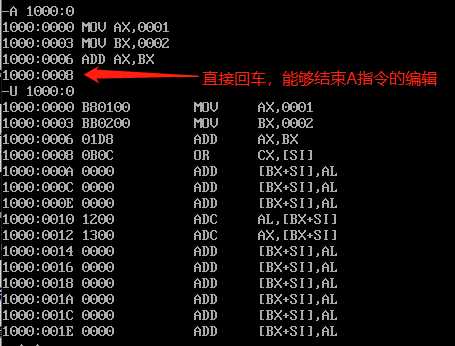
通过A命令进行指令的写入,和E命令达到的效果一样,但使用起来却更加便捷。A命令能够自动识别所输入汇编指令的长度,正确的在内存中写入程序指令。
debug提供了D、E两种命令用于对内存进行通用的操作(纯二进制、十六进制数据的读、写)。
对于程序指令,debug提供了U、A两种命令以更人性化的方式来读写内存中的指令内容。
在debug模式下可以模拟8086汇编非常自由的控制CPU和内存,这也是汇编语言的强大之处和魅力所在。
贴近硬件底层的编程能够让我们编写出来的程序非常高效,但也存在一些问题:
1.内存中的内容被当做指令还是数据来处理完全取决于如何解释,编程时稍有不慎就会导致CPU执行一些不应该执行的指令,甚至造成巨大的破坏。
2.在未来还会介绍如何使用汇编语言来实现高级语言中出现的结构体、数组等概念。这些数据结构完全是程序逻辑上的,内存本身可没有这些功能。因此在使用汇编访问内存中结构化的数据时,一不小心就会出现内存访问越界,错位等问题。
3.汇编语言的抽象程度过低,许多在高级语言中很简单的功能在汇编中也需要很多的代码来实现(汇编实现的控制台打印hello world可能是常用语言中最繁琐的了)。
编程语言的贴近底层与机器高效性如果站在更高的角度上看其实是一把双刃剑:直接操控底层的机器方便,机器执行效率高的同时,也是危险、开发效率底下的。汇编语言程序员不得不付出巨大的精力来仔细思考、斟酌这些底层机器层面的细节,以避免出现相关bug,大大降低了开发效率。这也是高级语言诞生,并不断发展的主要原因。
高级语言大家族中按抽象程度来看,从偏底层的C,C++到java、python等,再到目前抽象程度最高的lisp。随着抽象程度的提高,离机器底层越远,执行效率通常也随之降低。但程序员所需要考虑的机器细节也就越少,能更专注于业务逻辑,进而提高了开发效率。比如在使用C编程时还需要仔细考虑指针错误,堆上无用内存回收等问题,到了更高级的java、python中,这些问题都交由编译器、虚拟机解决了,对开发人员也几乎透明了。
天下没有免费的午餐,在选择适合的编程语言开发程序时,需要在机器执行效率和开发效率间做出取舍。但随着科学技术的发展,计算机硬件会越来越强大,对机器效率的担忧会越来越少,对程序开发效率的考虑将占据主导地位,越来越多的程序将会倾向于使用抽象程度更高的编程语言进行开发。
虽然需要使用汇编语言的场合越来越少,但对汇编语言和底层机器硬件有一定的了解的话,依然能够帮助程序员更深刻的理解上层的知识内容、写出更高效的程序。
毕竟,人类是无法抽象、封装到完美无缺的,有时还是你需要跳进下水道,深入底层一探究竟的。
8086汇编语言学习(二) 8086汇编开发环境搭建和Debug模式介绍
标签:执行命令 源程序 科学技术 一起 二进制文件 天下 内存数据 路径 问题:
原文地址:https://www.cnblogs.com/xiaoxiongcanguan/p/12176857.html