标签:属性 lin lis 复杂 config host 反序 是你 要求
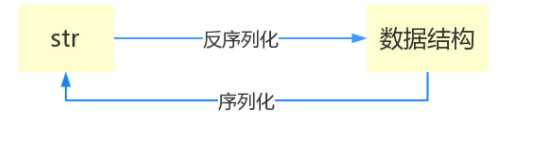
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?
现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。
但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。
你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢?
没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串,
但是你要怎么把一个字符串转换成字典呢?
聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。
eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。
BUT!强大的函数有代价。安全性是其最大的缺点。
想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。
而使用eval就要担这个风险。
所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
为什么要有序列化模块
序列化的目的
Json模块提供了四个功能:dumps、dump、loads、load
import json
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) #<class ‘str‘> {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json转换完的字符串类型的字典中的字符串是由""表示的
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2) #<class ‘dict‘> {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}
list_dic = [1,[‘a‘,‘b‘,‘c‘],3,{‘k1‘:‘v1‘,‘k2‘:‘v2‘}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class ‘str‘> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class ‘list‘> [1, [‘a‘, ‘b‘, ‘c‘], 3, {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘}]
loads和dumps
import json
f = open(‘json_file‘,‘w‘)
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
f = open(‘json_file‘)
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
load和dump
import json
f = open(‘file‘,‘w‘)
json.dump({‘国籍‘:‘中国‘},f)
ret = json.dumps({‘国籍‘:‘中国‘})
f.write(ret+‘\n‘)
json.dump({‘国籍‘:‘美国‘},f,ensure_ascii=False)
ret = json.dumps({‘国籍‘:‘美国‘},ensure_ascii=False)
f.write(ret+‘\n‘)
f.close()
ensure_ascii关键字参数
Serialize obj to a JSON formatted str.(字符串表示的json对象)
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:将数据根据keys的值进行排序。
To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
其他参数说明
import json
data = {‘username‘:[‘李华‘,‘二愣子‘],‘sex‘:‘male‘,‘age‘:16}
json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(‘,‘,‘:‘),ensure_ascii=False)
print(json_dic2)
用于序列化的两个模块
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
import pickle
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) #字典
import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open(‘pickle_file‘,‘wb‘)
pickle.dump(struct_time,f)
f.close()
f = open(‘pickle_file‘,‘rb‘)
struct_time2 = pickle.load(f)
print(struct_time2.tm_year)
pickle
这时候机智的你又要说了,既然pickle如此强大,为什么还要学json呢?
这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。
如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。
但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~
所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块
但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update(‘how to use md5 in python hashlib?‘)
print md5.hexdigest()
计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 = hashlib.md5() md5.update(‘how to use md5 in ‘) md5.update(‘python hashlib?‘) print md5.hexdigest()
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update(‘how to use sha1 in ‘) sha1.update(‘python hashlib?‘) print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password --------+---------- michael | 123456 bob | abc999 alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password ---------+--------------------------------- michael | e10adc3949ba59abbe56e057f20f883e bob | 878ef96e86145580c38c87f0410ad153 alice | 99b1c2188db85afee403b1536010c2c9
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
‘e10adc3949ba59abbe56e057f20f883e‘: ‘123456‘ ‘21218cca77804d2ba1922c33e0151105‘: ‘888888‘ ‘5f4dcc3b5aa765d61d8327deb882cf99‘: ‘password‘
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
hashlib.md5("salt".encode("utf8"))
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
configparser模块
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
来看一个好多软件的常见文档格式如下:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {‘ServerAliveInterval‘: ‘45‘,
‘Compression‘: ‘yes‘,
‘CompressionLevel‘: ‘9‘,
‘ForwardX11‘:‘yes‘
}
config[‘bitbucket.org‘] = {‘User‘:‘hg‘}
config[‘topsecret.server.com‘] = {‘Host Port‘:‘50022‘,‘ForwardX11‘:‘no‘}
with open(‘example.ini‘, ‘w‘) as configfile:
config.write(configfile)
import configparser
config = configparser.ConfigParser()
#---------------------------查找文件内容,基于字典的形式
print(config.sections()) # []
config.read(‘example.ini‘)
print(config.sections()) # [‘bitbucket.org‘, ‘topsecret.server.com‘]
print(‘bytebong.com‘ in config) # False
print(‘bitbucket.org‘ in config) # True
print(config[‘bitbucket.org‘]["user"]) # hg
print(config[‘DEFAULT‘][‘Compression‘]) #yes
print(config[‘topsecret.server.com‘][‘ForwardX11‘]) #no
print(config[‘bitbucket.org‘]) #<Section: bitbucket.org>
for key in config[‘bitbucket.org‘]: # 注意,有default会默认default的键
print(key)
print(config.options(‘bitbucket.org‘)) # 同for循环,找到‘bitbucket.org‘下所有键
print(config.items(‘bitbucket.org‘)) #找到‘bitbucket.org‘下所有键值对
print(config.get(‘bitbucket.org‘,‘compression‘)) # yes get方法Section下的key对应的value
import configparser
config = configparser.ConfigParser()
config.read(‘example.ini‘)
config.add_section(‘yuan‘)
config.remove_section(‘bitbucket.org‘)
config.remove_option(‘topsecret.server.com‘,"forwardx11")
config.set(‘topsecret.server.com‘,‘k1‘,‘11111‘)
config.set(‘yuan‘,‘k2‘,‘22222‘)
config.write(open(‘new2.ini‘, "w"))
import logging logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging
file_handler = logging.FileHandler(filename=‘x1.log‘, mode=‘a‘, encoding=‘utf-8‘,)
logging.basicConfig(
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘,
datefmt=‘%Y-%m-%d %H:%M:%S %p‘,
handlers=[file_handler,],
level=logging.ERROR
)
logging.error(‘你好‘)
日志切割
import time
import logging
from logging import handlers
sh = logging.StreamHandler()
rh = handlers.RotatingFileHandler(‘myapp.log‘, maxBytes=1024,backupCount=5)
fh = handlers.TimedRotatingFileHandler(filename=‘x2.log‘, when=‘s‘, interval=5, encoding=‘utf-8‘)
logging.basicConfig(
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘,
datefmt=‘%Y-%m-%d %H:%M:%S %p‘,
handlers=[fh,sh,rh],
level=logging.ERROR
)
for i in range(1,100000):
time.sleep(1)
logging.error(‘KeyboardInterrupt error %s‘%str(i))
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(‘test.log‘,encoding=‘utf-8‘)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘)
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug(‘logger debug message‘)
logger.info(‘logger info message‘)
logger.warning(‘logger warning message‘)
logger.error(‘logger error message‘)
logger.critical(‘logger critical message‘)
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过
fh.setLevel(logging.Debug)单对文件流设置某个级别。
1.语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正)
#语法错误示范一
if
#语法错误示范二
def test:
pass
#语法错误示范三
print(haha
语法错误
语法错误
2.逻辑错误(逻辑错误)
#用户输入不完整(比如输入为空)或者输入非法(输入不是数字)
num=input(">>: ")
int(num)
#无法完成计算
res1=1/0
res2=1+‘str‘
逻辑错误
异常就是程序运行时发生错误的信号,在python中,错误触发的异常如下
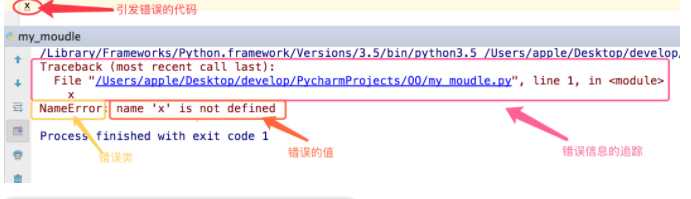
在python中不同的异常可以用不同的类型(python中统一了类与类型,类型即类)去标识,不同的类对象标识不同的异常,一个异常标识一种错误
# 触发IndexError
l=[‘egon‘,‘aa‘]
l[3]
# 触发KeyError
dic={‘name‘:‘egon‘}
dic[‘age‘]
#触发ValueError
s=‘hello‘
int(s)
错误举例
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x
IOError 输入/输出异常;基本上是无法打开文件
ImportError 无法引入模块或包;基本上是路径问题或名称错误
IndentationError 语法错误(的子类) ;代码没有正确对齐
IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
KeyError 试图访问字典里不存在的键
KeyboardInterrupt Ctrl+C被按下
NameError 使用一个还未被赋予对象的变量
SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了)
TypeError 传入对象类型与要求的不符合
UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,
导致你以为正在访问它
ValueError 传入一个调用者不期望的值,即使值的类型是正确的
常用异常
ArithmeticError
AssertionError
AttributeError
BaseException
BufferError
BytesWarning
DeprecationWarning
EnvironmentError
EOFError
Exception
FloatingPointError
FutureWarning
GeneratorExit
ImportError
ImportWarning
IndentationError
IndexError
IOError
KeyboardInterrupt
KeyError
LookupError
MemoryError
NameError
NotImplementedError
OSError
OverflowError
PendingDeprecationWarning
ReferenceError
RuntimeError
RuntimeWarning
StandardError
StopIteration
SyntaxError
SyntaxWarning
SystemError
SystemExit
TabError
TypeError
UnboundLocalError
UnicodeDecodeError
UnicodeEncodeError
UnicodeError
UnicodeTranslateError
UnicodeWarning
UserWarning
ValueError
Warning
ZeroDivisionError
更多异常
异常发生之后
异常之后的代码就不执行了
python解释器检测到错误,触发异常(也允许程序员自己触发异常)
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理
python解析器去执行程序,检测到了一个错误时,触发异常,异常触发后且没被处理的情况下,程序就在当前异常处终止,后面的代码不会运行,谁会去用一个运行着突然就崩溃的软件。
所以你必须提供一种异常处理机制来增强你程序的健壮性与容错性
首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前就修正
num1=input(‘>>: ‘) #输入一个字符串试试 int(num1)
num1=input(‘>>: ‘) #输入一个字符串试试
if num1.isdigit():
int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴
elif num1.isspace():
print(‘输入的是空格,就执行我这里的逻辑‘)
elif len(num1) == 0:
print(‘输入的是空,就执行我这里的逻辑‘)
else:
print(‘其他情情况,执行我这里的逻辑‘)
‘‘‘
问题一:
使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂
问题二:
这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。
‘‘‘
使用if判断进行异常处理
总结:
1.if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理。
2.在你的程序中频繁的写与程序本身无关,与异常处理有关的if,会使得你的代码可读性极其的差
3.if是可以解决异常的,只是存在1,2的问题,所以,千万不要妄下定论if不能用来异常处理。
def test():
print(‘test running‘)
choice_dic={
‘1‘:test
}
while True:
choice=input(‘>>: ‘).strip()
if not choice or choice not in choice_dic:continue #这便是一种异常处理机制啊
choice_dic[choice]()
你之前用的异常处理机制
python:为每一种异常定制了一个类型,然后提供了一种特定的语法结构用来进行异常处理
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?
现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。
但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。
你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢?
没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串,
但是你要怎么把一个字符串转换成字典呢?
聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。
eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。
BUT!强大的函数有代价。安全性是其最大的缺点。
想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。
而使用eval就要担这个风险。
所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
为什么要有序列化模块
序列化的目的
Json模块提供了四个功能:dumps、dump、loads、load
import json
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) #<class ‘str‘> {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json转换完的字符串类型的字典中的字符串是由""表示的
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2) #<class ‘dict‘> {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}
list_dic = [1,[‘a‘,‘b‘,‘c‘],3,{‘k1‘:‘v1‘,‘k2‘:‘v2‘}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class ‘str‘> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class ‘list‘> [1, [‘a‘, ‘b‘, ‘c‘], 3, {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘}]
loads和dumps
import json
f = open(‘json_file‘,‘w‘)
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
f = open(‘json_file‘)
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
load和dump
import json
f = open(‘file‘,‘w‘)
json.dump({‘国籍‘:‘中国‘},f)
ret = json.dumps({‘国籍‘:‘中国‘})
f.write(ret+‘\n‘)
json.dump({‘国籍‘:‘美国‘},f,ensure_ascii=False)
ret = json.dumps({‘国籍‘:‘美国‘},ensure_ascii=False)
f.write(ret+‘\n‘)
f.close()
ensure_ascii关键字参数
Serialize obj to a JSON formatted str.(字符串表示的json对象)
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:将数据根据keys的值进行排序。
To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
其他参数说明
import json
data = {‘username‘:[‘李华‘,‘二愣子‘],‘sex‘:‘male‘,‘age‘:16}
json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(‘,‘,‘:‘),ensure_ascii=False)
print(json_dic2)
用于序列化的两个模块
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
import pickle
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) #字典
import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open(‘pickle_file‘,‘wb‘)
pickle.dump(struct_time,f)
f.close()
f = open(‘pickle_file‘,‘rb‘)
struct_time2 = pickle.load(f)
print(struct_time2.tm_year)
pickle
这时候机智的你又要说了,既然pickle如此强大,为什么还要学json呢?
这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。
如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。
但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~
所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块
但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update(‘how to use md5 in python hashlib?‘)
print md5.hexdigest()
计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 = hashlib.md5() md5.update(‘how to use md5 in ‘) md5.update(‘python hashlib?‘) print md5.hexdigest()
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update(‘how to use sha1 in ‘) sha1.update(‘python hashlib?‘) print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password --------+---------- michael | 123456 bob | abc999 alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password ---------+--------------------------------- michael | e10adc3949ba59abbe56e057f20f883e bob | 878ef96e86145580c38c87f0410ad153 alice | 99b1c2188db85afee403b1536010c2c9
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
‘e10adc3949ba59abbe56e057f20f883e‘: ‘123456‘ ‘21218cca77804d2ba1922c33e0151105‘: ‘888888‘ ‘5f4dcc3b5aa765d61d8327deb882cf99‘: ‘password‘
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
hashlib.md5("salt".encode("utf8"))
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
configparser模块
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
来看一个好多软件的常见文档格式如下:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {‘ServerAliveInterval‘: ‘45‘,
‘Compression‘: ‘yes‘,
‘CompressionLevel‘: ‘9‘,
‘ForwardX11‘:‘yes‘
}
config[‘bitbucket.org‘] = {‘User‘:‘hg‘}
config[‘topsecret.server.com‘] = {‘Host Port‘:‘50022‘,‘ForwardX11‘:‘no‘}
with open(‘example.ini‘, ‘w‘) as configfile:
config.write(configfile)
import configparser
config = configparser.ConfigParser()
#---------------------------查找文件内容,基于字典的形式
print(config.sections()) # []
config.read(‘example.ini‘)
print(config.sections()) # [‘bitbucket.org‘, ‘topsecret.server.com‘]
print(‘bytebong.com‘ in config) # False
print(‘bitbucket.org‘ in config) # True
print(config[‘bitbucket.org‘]["user"]) # hg
print(config[‘DEFAULT‘][‘Compression‘]) #yes
print(config[‘topsecret.server.com‘][‘ForwardX11‘]) #no
print(config[‘bitbucket.org‘]) #<Section: bitbucket.org>
for key in config[‘bitbucket.org‘]: # 注意,有default会默认default的键
print(key)
print(config.options(‘bitbucket.org‘)) # 同for循环,找到‘bitbucket.org‘下所有键
print(config.items(‘bitbucket.org‘)) #找到‘bitbucket.org‘下所有键值对
print(config.get(‘bitbucket.org‘,‘compression‘)) # yes get方法Section下的key对应的value
import configparser
config = configparser.ConfigParser()
config.read(‘example.ini‘)
config.add_section(‘yuan‘)
config.remove_section(‘bitbucket.org‘)
config.remove_option(‘topsecret.server.com‘,"forwardx11")
config.set(‘topsecret.server.com‘,‘k1‘,‘11111‘)
config.set(‘yuan‘,‘k2‘,‘22222‘)
config.write(open(‘new2.ini‘, "w"))
import logging logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging
file_handler = logging.FileHandler(filename=‘x1.log‘, mode=‘a‘, encoding=‘utf-8‘,)
logging.basicConfig(
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘,
datefmt=‘%Y-%m-%d %H:%M:%S %p‘,
handlers=[file_handler,],
level=logging.ERROR
)
logging.error(‘你好‘)
日志切割
import time
import logging
from logging import handlers
sh = logging.StreamHandler()
rh = handlers.RotatingFileHandler(‘myapp.log‘, maxBytes=1024,backupCount=5)
fh = handlers.TimedRotatingFileHandler(filename=‘x2.log‘, when=‘s‘, interval=5, encoding=‘utf-8‘)
logging.basicConfig(
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘,
datefmt=‘%Y-%m-%d %H:%M:%S %p‘,
handlers=[fh,sh,rh],
level=logging.ERROR
)
for i in range(1,100000):
time.sleep(1)
logging.error(‘KeyboardInterrupt error %s‘%str(i))
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(‘test.log‘,encoding=‘utf-8‘)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘)
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug(‘logger debug message‘)
logger.info(‘logger info message‘)
logger.warning(‘logger warning message‘)
logger.error(‘logger error message‘)
logger.critical(‘logger critical message‘)
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过
fh.setLevel(logging.Debug)单对文件流设置某个级别。
1.语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正)
#语法错误示范一
if
#语法错误示范二
def test:
pass
#语法错误示范三
print(haha
语法错误
语法错误
2.逻辑错误(逻辑错误)
#用户输入不完整(比如输入为空)或者输入非法(输入不是数字)
num=input(">>: ")
int(num)
#无法完成计算
res1=1/0
res2=1+‘str‘
逻辑错误
异常就是程序运行时发生错误的信号,在python中,错误触发的异常如下
在python中不同的异常可以用不同的类型(python中统一了类与类型,类型即类)去标识,不同的类对象标识不同的异常,一个异常标识一种错误
# 触发IndexError
l=[‘egon‘,‘aa‘]
l[3]
# 触发KeyError
dic={‘name‘:‘egon‘}
dic[‘age‘]
#触发ValueError
s=‘hello‘
int(s)
错误举例
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x
IOError 输入/输出异常;基本上是无法打开文件
ImportError 无法引入模块或包;基本上是路径问题或名称错误
IndentationError 语法错误(的子类) ;代码没有正确对齐
IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
KeyError 试图访问字典里不存在的键
KeyboardInterrupt Ctrl+C被按下
NameError 使用一个还未被赋予对象的变量
SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了)
TypeError 传入对象类型与要求的不符合
UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,
导致你以为正在访问它
ValueError 传入一个调用者不期望的值,即使值的类型是正确的
常用异常
ArithmeticError
AssertionError
AttributeError
BaseException
BufferError
BytesWarning
DeprecationWarning
EnvironmentError
EOFError
Exception
FloatingPointError
FutureWarning
GeneratorExit
ImportError
ImportWarning
IndentationError
IndexError
IOError
KeyboardInterrupt
KeyError
LookupError
MemoryError
NameError
NotImplementedError
OSError
OverflowError
PendingDeprecationWarning
ReferenceError
RuntimeError
RuntimeWarning
StandardError
StopIteration
SyntaxError
SyntaxWarning
SystemError
SystemExit
TabError
TypeError
UnboundLocalError
UnicodeDecodeError
UnicodeEncodeError
UnicodeError
UnicodeTranslateError
UnicodeWarning
UserWarning
ValueError
Warning
ZeroDivisionError
更多异常
异常发生之后
异常之后的代码就不执行了
python解释器检测到错误,触发异常(也允许程序员自己触发异常)
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理
python解析器去执行程序,检测到了一个错误时,触发异常,异常触发后且没被处理的情况下,程序就在当前异常处终止,后面的代码不会运行,谁会去用一个运行着突然就崩溃的软件。
所以你必须提供一种异常处理机制来增强你程序的健壮性与容错性
首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前就修正
num1=input(‘>>: ‘) #输入一个字符串试试 int(num1)
num1=input(‘>>: ‘) #输入一个字符串试试
if num1.isdigit():
int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴
elif num1.isspace():
print(‘输入的是空格,就执行我这里的逻辑‘)
elif len(num1) == 0:
print(‘输入的是空,就执行我这里的逻辑‘)
else:
print(‘其他情情况,执行我这里的逻辑‘)
‘‘‘
问题一:
使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂
问题二:
这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。
‘‘‘
使用if判断进行异常处理
总结:
1.if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理。
2.在你的程序中频繁的写与程序本身无关,与异常处理有关的if,会使得你的代码可读性极其的差
3.if是可以解决异常的,只是存在1,2的问题,所以,千万不要妄下定论if不能用来异常处理。
def test():
print(‘test running‘)
choice_dic={
‘1‘:test
}
while True:
choice=input(‘>>: ‘).strip()
if not choice or choice not in choice_dic:continue #这便是一种异常处理机制啊
choice_dic[choice]()
你之前用的异常处理机制
python:为每一种异常定制了一个类型,然后提供了一种特定的语法结构用来进行异常处理
try:
被检测的代码块
except 异常类型:
try中一旦检测到异常,就执行这个位置的逻辑
f = open(‘a.txt‘)
g = (line.strip() for line in f)
for line in g:
print(line)
else:
f.close()
读文件例1
try:
f = open(‘a.txt‘)
g = (line.strip() for line in f)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
except StopIteration:
f.close()
‘‘‘
next(g)会触发迭代f,依次next(g)就可以读取文件的一行行内容,无论文件a.txt有多大,同一时刻内存中只有一行内容。
提示:g是基于文件句柄f而存在的,因而只能在next(g)抛出异常StopIteration后才可以执行f.close()
‘‘‘
读文件例2
# 未捕获到异常,程序直接报错
s1 = ‘hello‘
try:
int(s1)
except IndexError as e:
print e
s1 = ‘hello‘
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
他可以捕获任意异常,即:
s1 = ‘hello‘
try:
int(s1)
except Exception as e:
print(e)
你可能会说既然有万能异常,那么我直接用上面的这种形式就好了,其他异常可以忽略
你说的没错,但是应该分两种情况去看
1.如果你想要的效果是,无论出现什么异常,我们统一丢弃,或者使用同一段代码逻辑去处理他们,那么骚年,大胆的去做吧,只有一个Exception就足够了。
s1 = ‘hello‘
try:
int(s1)
except Exception,e:
‘丢弃或者执行其他逻辑‘
print(e)
#如果你统一用Exception,没错,是可以捕捉所有异常,但意味着你在处理所有异常时都使用同一个逻辑去处理(这里说的逻辑即当前expect下面跟的代码块)
Exception
2.如果你想要的效果是,对于不同的异常我们需要定制不同的处理逻辑,那就需要用到多分支了。
s1 = ‘hello‘
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
多分支
s1 = ‘hello‘
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
except Exception as e:
print(e)
多分支+Exception
s1 = ‘hello‘
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
#except Exception as e:
# print(e)
else:
print(‘try内代码块没有异常则执行我‘)
finally:
print(‘无论异常与否,都会执行该模块,通常是进行清理工作‘)
try:
raise TypeError(‘类型错误‘)
except Exception as e:
print(e)
class EvaException(BaseException):
def __init__(self,msg):
self.msg=msg
def __str__(self):
return self.msg
try:
raise EvaException(‘类型错误‘)
except EvaException as e:
print(e)
# assert 条件 assert 1 == 1 assert 1 == 2
try..except这种异常处理机制就是取代if那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性
异常处理中为每一个异常定制了异常类型(python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到,可以同时处理多段代码的异常(无需‘写多个if判断式’)减少了代码,增强了可读性
使用try..except的方式
1:把错误处理和真正的工作分开来
2:代码更易组织,更清晰,复杂的工作任务更容易实现;
3:毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了;
有的同学会这么想,学完了异常处理后,好强大,我要为我的每一段程序都加上try...except,去思考它会不会有逻辑错误啊,这样就很好啊,多省脑细胞,这样想法就错误了,try...except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的
这种东西加的多了,会导致你的代码可读性变差,只有在有些异常无法预知的情况下,才应该加上try...except,其他的逻辑错误应该尽量修正.
25.Python序列化模块,hashlib模块, configparser模块,logging模块,异常处理
标签:属性 lin lis 复杂 config host 反序 是你 要求
原文地址:https://www.cnblogs.com/xuweng/p/12203619.html