标签:lib pyquery 最大 上海 去哪里 urllib docker基础 rdo mic

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
小白学 Python 爬虫(26):为啥买不起上海二手房你都买不起
小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
小白学 Python 爬虫(31):自己构建一个简单的代理池
小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
小白学 Python 爬虫(39): JavaScript 渲染服务 Scrapy-Splash 入门
小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
首先恭喜看到这篇文章的同学,本篇内容为 「小白学 Python 爬虫」 系列的最后一篇。

看了下上面的前文传送门,加上这篇内容,总共有 42 篇,小编还是成就感满满,小编翻看了下公众号,第一篇文章是在 2019 年的 11 月 17 日推送的,大致数了数,将近两个月的时间。
当然,其中一些文章的质量并不高,很多都是在比较有限的时间中赶工赶出来的,还是感谢各位读者对小编的不离不弃,写的这么烂还没取关的绝对是真爱了。
正好下周就要过年了,从推送的时间算的话还有 10 个自然日左右的时间,可能很多同学可能过年是要出去玩的,那么去哪里玩就成了一个问题。
那么,怎么挑选去哪里玩最快的,小编想了想,直接去抓某站的数据吧,抓下来自己根据自己的情况查询下就好了。
那么今天的目标站是:马蜂窝。
这里小编还想说一点,虽然我们在前面 7、 8 篇文章中都是在讲如何使用爬虫框架 Scrapy ,说实话,小编并不觉得 Scrapy 有多方便,在一些简单的应用场景下,使用 Requests 库可能是最方便的选择, Scrapy 小编个人感觉还是更适合使用在一些中大型的爬虫项目中,简单的爬虫脚本使用最简单的技术栈就 ok 了,所以小编在本文中使用的技术栈还是 Requests + PyQuery 。
不要问为啥,问就是喜欢。
首先我们访问链接,打开我们将要抓取的站点:https://www.mafengwo.cn/gonglve/ 。
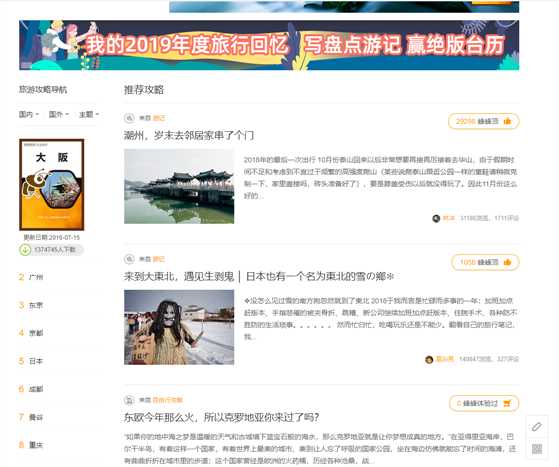
这里是攻略的列表页,我们的目标是抓取来自游记的数据,其余的数据放过,原因是在游记中我们才能获取到一些具体的我们需要的数据。

数据的来源搞清楚了,接下来是翻页功能,只有清楚了如何翻页,我们才能源源不断的获取数据,否则就只能抓取第一页的数据了。
当把页面翻到最下面的时候就尴尬了,发现是自动加载更多,这个当然难不倒帅气逼人的小编我,掏出大杀器, Chrome 的开发者工具 F12 ,选到 network 标签页,再往下滚动一下,我们查看下这个页面发出的请求。
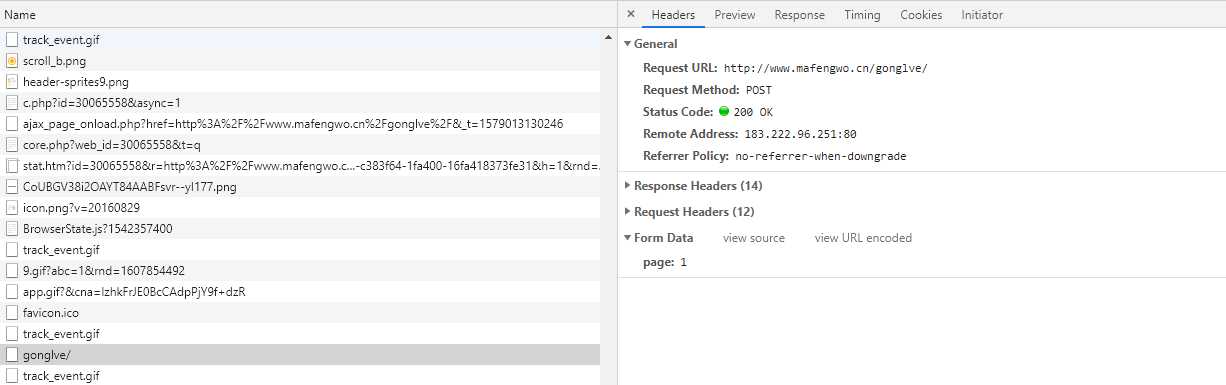
这个请求很有意思,请求的路径和我们访问的页面路径一样,但是请求类型变成 POST ,并且增加了请求参数,类型还是 Form 表单格式的。
截止这里,我们已经清楚了目标站点的数据路径以及翻页方式,虽然目前我们并不知道最大页数是多少,但是我们可以人为的设置一个最大页数,比如 100 或者 200 ,小编相信,这么大的站点上,几百页的游记应该是还有的。
代码小编就直接贴出来,之前有同学希望数据是保存在 Excel 中的,本次实战的数据就不存数据库了,直接写入 Excel 。
import requests
from pyquery import PyQuery
import xlsxwriter
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'cookie': '__jsluid_s=6fc5b4a3b5235afbfdafff4bbf7e6dbd; PHPSESSID=v9hm8hc3s56ogrn8si12fejdm3; mfw_uuid=5e1db855-ab4a-da12-309c-afb9cf90d3dd; _r=baidu; _rp=a%3A2%3A%7Bs%3A1%3A%22p%22%3Bs%3A18%3A%22www.baidu.com%2Flink%22%3Bs%3A1%3A%22t%22%3Bi%3A1579006045%3B%7D; oad_n=a%3A5%3A%7Bs%3A5%3A%22refer%22%3Bs%3A21%3A%22https%3A%2F%2Fwww.baidu.com%22%3Bs%3A2%3A%22hp%22%3Bs%3A13%3A%22www.baidu.com%22%3Bs%3A3%3A%22oid%22%3Bi%3A1026%3Bs%3A2%3A%22dm%22%3Bs%3A15%3A%22www.mafengwo.cn%22%3Bs%3A2%3A%22ft%22%3Bs%3A19%3A%222020-01-14+20%3A47%3A25%22%3B%7D; __mfwothchid=referrer%7Cwww.baidu.com; __omc_chl=; __mfwc=referrer%7Cwww.baidu.com; Hm_lvt_8288b2ed37e5bc9b4c9f7008798d2de0=1579006048; uva=s%3A264%3A%22a%3A4%3A%7Bs%3A13%3A%22host_pre_time%22%3Bs%3A10%3A%222020-01-14%22%3Bs%3A2%3A%22lt%22%3Bi%3A1579006046%3Bs%3A10%3A%22last_refer%22%3Bs%3A137%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DuR5Oj9n_xm4TSj7_1drQ1HRnFTYNM0M2TCljkjVrdIiUE-B2qPgh0MifEkceLE_U%26wd%3D%26eqid%3D93c920a80002dc72000000035e1db85c%22%3Bs%3A5%3A%22rhost%22%3Bs%3A13%3A%22www.baidu.com%22%3B%7D%22%3B; __mfwurd=a%3A3%3A%7Bs%3A6%3A%22f_time%22%3Bi%3A1579006046%3Bs%3A9%3A%22f_rdomain%22%3Bs%3A13%3A%22www.baidu.com%22%3Bs%3A6%3A%22f_host%22%3Bs%3A3%3A%22www%22%3B%7D; __mfwuuid=5e1db855-ab4a-da12-309c-afb9cf90d3dd; UM_distinctid=16fa418373e40f-070db24dfac29d-c383f64-1fa400-16fa418373fe31; __jsluid_h=b3f11fd3c79469af5c49be9ecb7f7b86; __omc_r=; __mfwa=1579006047379.58159.3.1579011903001.1579015057723; __mfwlv=1579015057; __mfwvn=2; CNZZDATA30065558=cnzz_eid%3D448020855-1579003717-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1579014923; bottom_ad_status=0; __mfwb=5e663dbc8869.7.direct; __mfwlt=1579019025; Hm_lpvt_8288b2ed37e5bc9b4c9f7008798d2de0=1579019026; __jsl_clearance=1579019146.235|0|fpZQ1rm7BHtgd6GdjVUIX8FJJ9o%3D'
}
s = requests.Session()
value = []
def getList(maxNum):
"""
获取列表页面数据
:param maxNum: 最大抓取页数
:return:
"""
url = 'http://www.mafengwo.cn/gonglve/'
s.get(url, headers = headers)
for page in range(1, maxNum + 1):
data = {'page': page}
response = s.post(url, data = data, headers = headers)
doc = PyQuery(response.text)
items = doc('.feed-item').items()
for item in items:
if item('.type strong').text() == '游记':
# 如果是游记,则进入内页数据抓取
inner_url = item('a').attr('href')
getInfo(inner_url)
def getInfo(url):
"""
获取内页数据
:param url: 内页链接
:return:
"""
response = s.get(url, headers = headers)
doc = PyQuery(response.text)
title = doc('title').text()
# 获取数据采集区
item = doc('.tarvel_dir_list')
if len(item) == 0:
return
time = item('.time').text()
day = item('.day').text()
people = item('.people').text()
cost = item('.cost').text()
# 数据格式化
if time == '':
pass
else:
time = time.split('/')[1] if len(time.split('/')) > 1 else ''
if day == '':
pass
else:
day = day.split('/')[1] if len(day.split('/')) > 1 else ''
if people == '':
pass
else:
people = people.split('/')[1] if len(people.split('/')) > 1 else ''
if cost == '':
pass
else:
cost = cost.split('/')[1] if len(cost.split('/')) > 1 else ''
value.append([title, time, day, people, cost, url])
def write_excel_xlsx(value):
"""
数据写入Excel
:param value:
:return:
"""
index = len(value)
workbook = xlsxwriter.Workbook('mfw.xlsx')
sheet = workbook.add_worksheet()
for i in range(1, index + 1):
row = 'A' + str(i)
sheet.write_row(row, value[i - 1])
workbook.close()
print("xlsx格式表格写入数据成功!")
def main():
getList(5)
write_excel_xlsx(value)
if __name__ == '__main__':
main()因为马蜂窝在游记的详情页面上有反爬的限制,小编这里为了简单,直接从浏览器中将 cookie copy 出来,加在了请求头上。
小编这里简单的爬取了 5 个列表页的信息,如下:

好像数据量并不是很多的样子,各位同学可以尝试爬取 50 页或者 100 页的数据,这样得到的结果会有比较不错的参考价值。
好了,本篇内容到这里就结束了,小编随后会将全部的文章索引整理出来推在公众号上,方便大家查阅。
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
小白学 Python 爬虫(42):春节去哪里玩(系列终篇)
标签:lib pyquery 最大 上海 去哪里 urllib docker基础 rdo mic
原文地址:https://www.cnblogs.com/babycomeon/p/12204167.html