标签:vol unknown ken 标签 erro val Fix identity ati
Taint需要与Toleration配合使用,让pod避开那些不合适的node。在node上设置一个或多个Taint后,除非pod明确声明能够容忍这些“污点”,否则无法在这些node上运行。Toleration是pod的属性,让pod能够(注意,只是能够,而非必须)运行在标注了Taint的node上。
默认情况下,所有的应用pod都不会运行在有污点的节点上
[root@docker-server1 deployment]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox-674bd96f74-8d7ml 0/1 Pending 0 38m <none> <none> <none> <none> goproxy 1/1 Running 1 3d12h 10.244.1.21 192.168.132.132 <none> <none> hello-deployment-5fdb46d67c-dqnnh 1/1 Running 0 25h 10.244.1.25 192.168.132.132 <none> <none> hello-deployment-5fdb46d67c-s68tf 1/1 Running 0 25h 10.244.2.15 192.168.132.133 <none> <none> hello-deployment-5fdb46d67c-x5nwl 1/1 Running 0 25h 10.244.1.24 192.168.132.132 <none> <none> init-demo 1/1 Running 1 3d11h 10.244.1.23 192.168.132.132 <none> <none> mysql-5d4695cd5-kzlms 1/1 Running 0 23h 10.244.1.28 192.168.132.132 <none> <none> nginx 2/2 Running 21 3d14h 10.244.2.14 192.168.132.133 <none> <none> nginx-volume 1/1 Running 1 3d11h 10.244.1.19 192.168.132.132 <none> <none> wordpress-6cbb67575d-b9md5 1/1 Running 0 23h 10.244.0.10 192.168.132.131 <none> <none>
给192.168.132.132打上污点
[root@docker-server1 deployment]# kubectl taint node 192.168.132.132 ingress=enable:NoExecute
node/192.168.132.132 tainted
[root@docker-server1 deployment]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox-674bd96f74-8d7ml 0/1 Pending 0 44m <none> <none> <none> <none> hello-deployment-5fdb46d67c-gw2t6 1/1 Running 0 37s 10.244.2.18 192.168.132.133 <none> <none> hello-deployment-5fdb46d67c-s68tf 1/1 Running 0 25h 10.244.2.15 192.168.132.133 <none> <none> hello-deployment-5fdb46d67c-vzb4f 1/1 Running 0 37s 10.244.2.16 192.168.132.133 <none> <none> mysql-5d4695cd5-v6btl 0/1 ContainerCreating 0 37s <none> 192.168.132.133 <none> <none> nginx 2/2 Running 22 3d14h 10.244.2.14 192.168.132.133 <none> <none> wordpress-6cbb67575d-b9md5 1/1 Running 0 23h 10.244.0.10 192.168.132.131 <none> <none>
132节点已经没有pod运行
当配置有taint和label,taint比lable具有更高的优先级,拒绝优先,比如
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-79669b846b-588cs 0/1 Pending 0 3m51s <none> <none> <none> <none>
标签时打向192.168.132.132,但是有污点,拒绝优先,但是其他节点没有匹配标签,就会一直pengding
[root@docker-server1 deployment]# vim /yamls/ingress/nginx-controller.yaml
nodeSelector: ingress: enable tolerations: - key: "ingress" operator: "Equal" value: "enable" effect: "NoExecute"
[root@docker-server1 deployment]# kubectl apply -f /yamls/ingress/nginx-controller.yaml
namespace/ingress-nginx unchanged configmap/nginx-configuration unchanged configmap/tcp-services unchanged configmap/udp-services unchanged serviceaccount/nginx-ingress-serviceaccount unchanged clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole unchanged role.rbac.authorization.k8s.io/nginx-ingress-role unchanged rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding unchanged clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding unchanged deployment.apps/nginx-ingress-controller configured limitrange/ingress-nginx configured
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-79669b846b-588cs 0/1 Pending 0 12m <none> <none> <none> <none> nginx-ingress-controller-dd4864d55-2tlk2 0/1 Running 0 3s 192.168.132.132 192.168.132.132 <none> <none>
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-dd4864d55-2tlk2 1/1 Running 0 80s 192.168.132.132 192.168.132.132 <none> <none>
ingress的pod运行在132上,ingress专机专用,机器独占
kubectl taint node [node] key=value[effect] 其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ] NoSchedule :一定不能被调度。 PreferNoSchedule:尽量不要调度。 NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。
kubectl taint node 192.168.132.132 ingress=enable:NoExecute 最后的就是设置污点的级别
一个节点可以设置多个污点,但是pod在容忍无污点的时候,也必须时容忍所有的污点才能运行在这个节点上,有一个污点不能容忍,也不会运行在该节点上
上面的例子中effect的取值为NoSchedule,下面对effect的值作下简单说明:
NoSchedule: 如果一个pod没有声明容忍这个Taint,则系统不会把该Pod调度到有这个Taint的node上
PreferNoSchedule:NoSchedule的软限制版本,如果一个Pod没有声明容忍这个Taint,则系统会尽量避免把这个pod调度到这一节点上去,但不是强制的。
NoExecute:定义pod的驱逐行为,以应对节点故障。NoExecute这个Taint效果对节点上正在运行的pod有以下影响:
没有设置Toleration的Pod会被立刻驱逐
配置了对应Toleration的pod,如果没有为tolerationSeconds赋值,则会一直留在这一节点中
配置了对应Toleration的pod且指定了tolerationSeconds值,则会在指定时间后驱逐
从kubernetes 1.6版本开始引入了一个alpha版本的功能,即把节点故障标记为Taint(目前只针对node unreachable及node not ready,相应的NodeCondition "Ready"的值为Unknown和False)。激活TaintBasedEvictions功能后(在--feature-gates参数中加入TaintBasedEvictions=true),NodeController会自动为Node设置Taint,而状态为"Ready"的Node上之前设置过的普通驱逐逻辑将会被禁用。注意,在节点故障情况下,为了保持现存的pod驱逐的限速设置,系统将会以限速的模式逐步给node设置Taint,这就能防止在一些特定情况下(比如master暂时失联)造成的大量pod被驱逐的后果。这一功能兼容于tolerationSeconds,允许pod定义节点故障时持续多久才被逐出。
系统允许在同一个node上设置多个taint,也可以在pod上设置多个Toleration。Kubernetes调度器处理多个Taint和Toleration能够匹配的部分,剩下的没有忽略掉的Taint就是对Pod的效果了。下面是几种特殊情况:
如果剩余的Taint中存在effect=NoSchedule,则调度器不会把该pod调度到这一节点上。
如果剩余的Taint中没有NoSchedule的效果,但是有PreferNoSchedule效果,则调度器会尝试不会pod指派给这个节点
如果剩余Taint的效果有NoExecute的,并且这个pod已经在该节点运行,则会被驱逐;如果没有在该节点运行,也不会再被调度到该节点上。
为192.168.132.132再打一个污点
[root@docker-server1 deployment]# kubectl taint node 192.168.132.132 ingress=enable:NoSchedule
node/192.168.132.132 tainted
只要有一个不一样,就会被认为时新的污点
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-dd4864d55-2tlk2 1/1 Running 0 47h 192.168.132.132 192.168.132.132 <none> <none>
因为这个污点时,NoSchedule,是尽量不要调度,所以运行的不会被驱逐,但是杀掉pod后,就不会再起来
[root@docker-server1 deployment]# kubectl delete pods nginx-ingress-controller-dd4864d55-2tlk2 -n ingress-nginx
pod "nginx-ingress-controller-dd4864d55-2tlk2" deleted
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-dd4864d55-tkk6n 0/1 Pending 0 22s <none> <none> <none> <none>
如果需要重新running,需要再为这个污点配置容忍
[root@docker-server1 deployment]# vim /yamls/ingress/nginx-controller.yaml
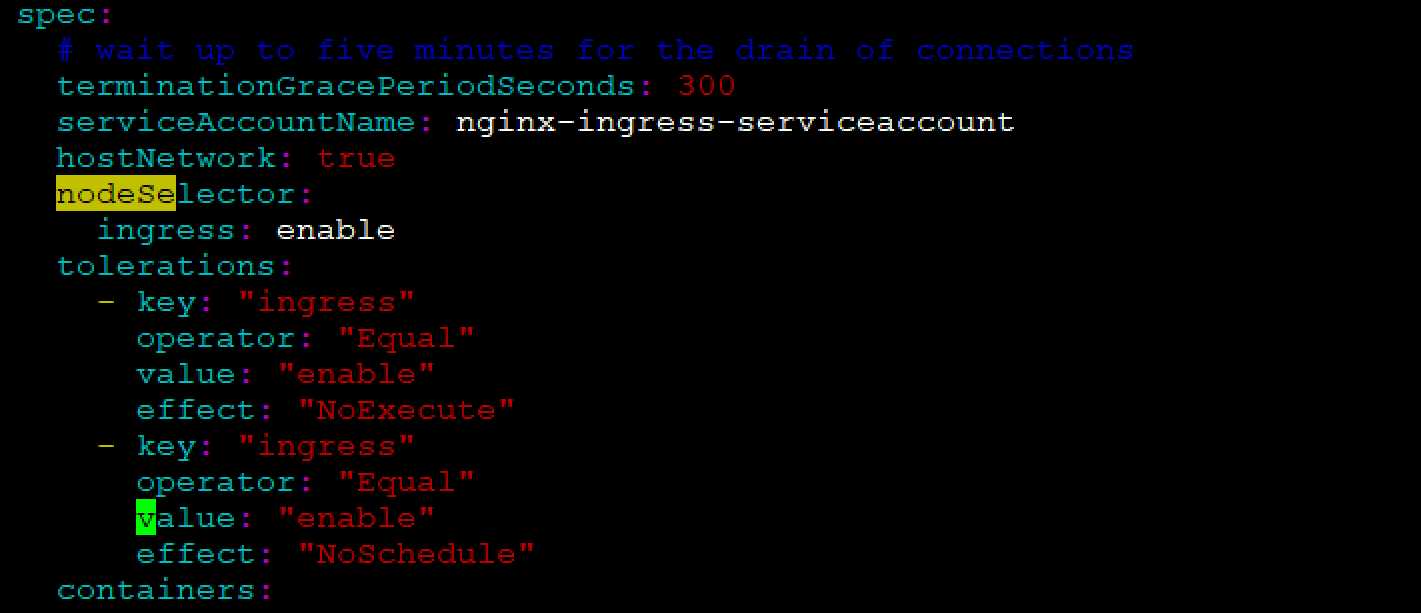
[root@docker-server1 deployment]# kubectl apply -f /yamls/ingress/nginx-controller.yaml
namespace/ingress-nginx unchanged configmap/nginx-configuration unchanged configmap/tcp-services unchanged configmap/udp-services unchanged serviceaccount/nginx-ingress-serviceaccount unchanged clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole unchanged role.rbac.authorization.k8s.io/nginx-ingress-role unchanged rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding unchanged clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding unchanged deployment.apps/nginx-ingress-controller configured limitrange/ingress-nginx configured
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-7487db85f9-tmsdq 0/1 Running 0 2s 192.168.132.132 192.168.132.132 <none> <none> nginx-ingress-controller-dd4864d55-tkk6n 0/1 Pending 0 30m <none> <none> <none> <none>
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-7487db85f9-tmsdq 1/1 Running 0 39s 192.168.132.132 192.168.132.132 <none> <none>
当容忍多污点时,使用Existed,就只需要指定key,不需要指定key的值
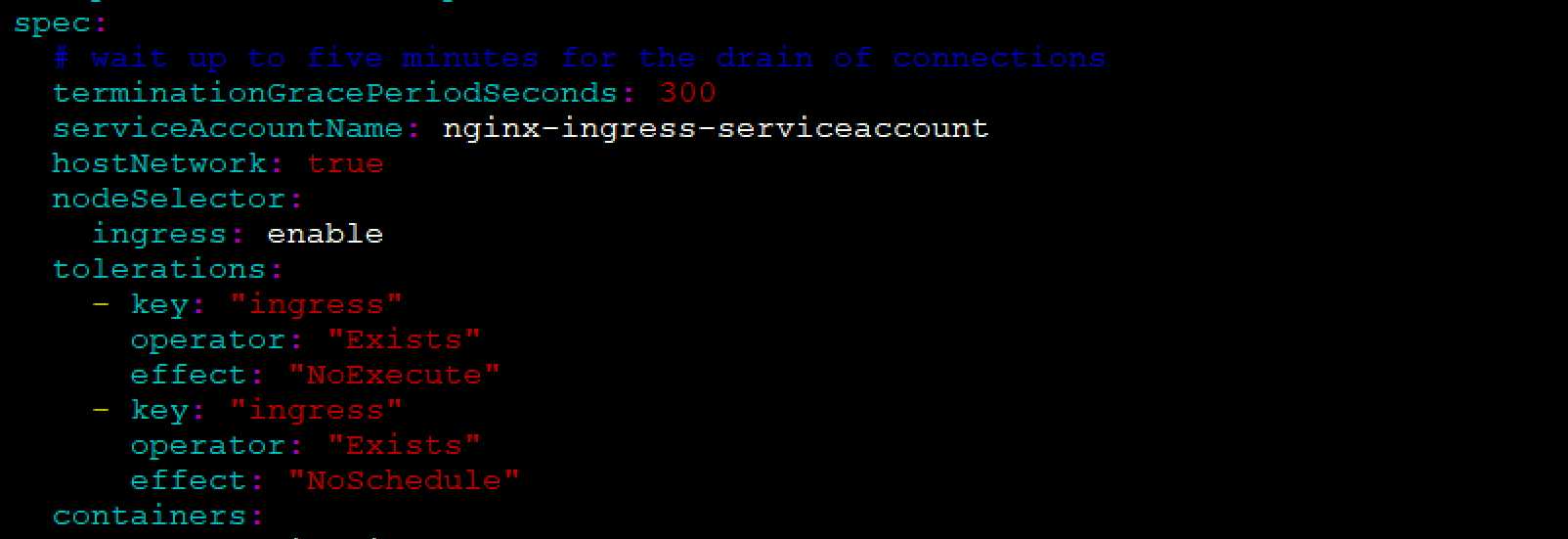
[root@docker-server1 deployment]# kubectl apply -f /yamls/ingress/nginx-controller.yaml
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-66fb449f6f-8pb29 0/1 Pending 0 3s <none> <none> <none> <none> nginx-ingress-controller-7487db85f9-tmsdq 1/1 Running 0 33h 192.168.132.132 192.168.132.132 <none> <none>
新启的机器是pending
[root@docker-server1 deployment]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS 192.168.132.131 Ready master 7d5h v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.132.131,kubernetes.io/os=linux,node-role.kubernetes.io/master= 192.168.132.132 Ready <none> 7d5h v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,ingress=enable,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.132.132,kubernetes.io/os=linux 192.168.132.133 Ready <none> 7d5h v1.17.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.132.133,kubernetes.io/os=linux
查看机器打的污点
[root@docker-server1 deployment]# kubectl describe node 192.168.132.132
Name: 192.168.132.132 Roles: <none> Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux ingress=enable kubernetes.io/arch=amd64 kubernetes.io/hostname=192.168.132.132 kubernetes.io/os=linux Annotations: flannel.alpha.coreos.com/backend-data: {"VtepMAC":"22:69:dd:55:70:87"} flannel.alpha.coreos.com/backend-type: vxlan flannel.alpha.coreos.com/kube-subnet-manager: true flannel.alpha.coreos.com/public-ip: 192.168.132.132 kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock node.alpha.kubernetes.io/ttl: 0 volumes.kubernetes.io/controller-managed-attach-detach: true CreationTimestamp: Thu, 09 Jan 2020 13:31:58 -0500 Taints: ingress=enable:NoExecute #两个污点 ingress=enable:NoSchedule Unschedulable: false Lease: HolderIdentity: 192.168.132.132 AcquireTime: <unset> RenewTime: Thu, 16 Jan 2020 19:11:13 -0500 Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- MemoryPressure False Thu, 16 Jan 2020 19:06:55 -0500 Sun, 12 Jan 2020 06:45:19 -0500 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Thu, 16 Jan 2020 19:06:55 -0500 Sun, 12 Jan 2020 06:45:19 -0500 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Thu, 16 Jan 2020 19:06:55 -0500 Sun, 12 Jan 2020 06:45:19 -0500 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Thu, 16 Jan 2020 19:06:55 -0500 Sun, 12 Jan 2020 06:45:19 -0500 KubeletReady kubelet is posting ready status Addresses: InternalIP: 192.168.132.132 Hostname: 192.168.132.132 Capacity: cpu: 4 ephemeral-storage: 49250820Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7990132Ki pods: 110 Allocatable: cpu: 4 ephemeral-storage: 45389555637 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7887732Ki pods: 110 System Info: Machine ID: 817ad910bace4109bda4f5dc5c709092 System UUID: 88884D56-86A7-4238-F2D9-5802E163FD11 Boot ID: 9dd1778e-168b-4296-baa2-d28d2839fab1 Kernel Version: 3.10.0-1062.4.1.el7.x86_64 OS Image: CentOS Linux 7 (Core) Operating System: linux Architecture: amd64 Container Runtime Version: docker://19.3.5 Kubelet Version: v1.17.0 Kube-Proxy Version: v1.17.0 PodCIDR: 10.244.1.0/24 PodCIDRs: 10.244.1.0/24 Non-terminated Pods: (2 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE --------- ---- ------------ ---------- --------------- ------------- --- ingress-nginx nginx-ingress-controller-7487db85f9-tmsdq 100m (2%) 0 (0%) 90Mi (1%) 0 (0%) 33h kube-system kube-proxy-7xgt9 0 (0%) 0 (0%) 0 (0%) 0 (0%) 7d5h Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 100m (2%) 0 (0%) memory 90Mi (1%) 0 (0%) ephemeral-storage 0 (0%) 0 (0%) Events: <none>
查看pengding的容器信息
[root@docker-server1 deployment]# kubectl describe pods nginx-ingress-controller-66fb449f6f-8pb29 -n ingress-nginx
Name: nginx-ingress-controller-66fb449f6f-8pb29 Namespace: ingress-nginx Priority: 0 Node: <none> Labels: app.kubernetes.io/name=ingress-nginx app.kubernetes.io/part-of=ingress-nginx pod-template-hash=66fb449f6f Annotations: kubernetes.io/limit-ranger: LimitRanger plugin set: cpu, memory request for container nginx-ingress-controller prometheus.io/port: 10254 prometheus.io/scrape: true Status: Pending IP: IPs: <none> Controlled By: ReplicaSet/nginx-ingress-controller-66fb449f6f Containers: nginx-ingress-controller: Image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:master Ports: 80/TCP, 443/TCP Host Ports: 80/TCP, 443/TCP Args: /nginx-ingress-controller --configmap=$(POD_NAMESPACE)/nginx-configuration --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services --udp-services-configmap=$(POD_NAMESPACE)/udp-services --publish-service=$(POD_NAMESPACE)/ingress-nginx --annotations-prefix=nginx.ingress.kubernetes.io Requests: cpu: 100m memory: 90Mi Liveness: http-get http://:10254/healthz delay=10s timeout=10s period=10s #success=1 #failure=3 Readiness: http-get http://:10254/healthz delay=0s timeout=10s period=10s #success=1 #failure=3 Environment: POD_NAME: nginx-ingress-controller-66fb449f6f-8pb29 (v1:metadata.name) POD_NAMESPACE: ingress-nginx (v1:metadata.namespace) Mounts: /var/run/secrets/kubernetes.io/serviceaccount from nginx-ingress-serviceaccount-token-l89pw (ro) Conditions: Type Status PodScheduled False Volumes: nginx-ingress-serviceaccount-token-l89pw: Type: Secret (a volume populated by a Secret) SecretName: nginx-ingress-serviceaccount-token-l89pw Optional: false QoS Class: Burstable Node-Selectors: ingress=enable Tolerations: ingress:NoExecute ingress:NoSchedule node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 1 node(s) didn‘t have free ports for the requested pod ports, 2 node(s) didn‘t match node selector. Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 1 node(s) didn‘t have free ports for the requested pod ports, 2 node(s) didn‘t match node selector.
是因为没有多余的ports使用,使用hosts模式,第一台机器占据端口没有释放
杀掉第一个pods
[root@docker-server1 deployment]# kubectl delete pods nginx-ingress-controller-7487db85f9-tmsdq -n ingress-nginx
[root@docker-server1 deployment]# kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-66fb449f6f-8pb29 1/1 Running 0 13m 192.168.132.132 192.168.132.132 <none> <none>
pods以及你个正常属于running状态,问题解决
如果想要拿出一部分节点,专门给特定的应用使用,则可以为节点添加这样的Taint:
kubectl taint nodes nodename dedicated=groupName:NoSchedule
然后给这些应用的pod加入相应的toleration,则带有合适toleration的pod就会被允许同使用其他节点一样使用有taint的节点。然后再将这些node打上指定的标签,再通过nodeSelector或者亲和性调度的方式,要求这些pod必须运行在指定标签的节点上。
在集群里,可能有一小部分节点安装了特殊的硬件设备,比如GPU芯片。用户自然会希望把不需要占用这类硬件的pod排除在外。以确保对这类硬件有需求的pod能够顺利调度到这些节点上。可以使用下面的命令为节点设置taint:
kubectl taint nodes nodename special=true:NoSchedule kubectl taint nodes nodename special=true:PreferNoSchedule
然后在pod中利用对应的toleration来保障特定的pod能够使用特定的硬件。然后同样的,我们也可以使用标签或者其他的一些特征来判断这些pod,将其调度到这些特定硬件的服务器上。
之前说到,在节点故障时,可以通过TaintBasedEvictions功能自动将节点设置Taint,然后将pod驱逐。但是在一些场景下,比如说网络故障造成的master与node失联,而这个node上运行了很多本地状态的应用即使网络故障,也仍然希望能够持续在该节点上运行,期望网络能够快速恢复,从而避免从这个node上被驱逐。Pod的Toleration可以这样定义:
tolerations: - key: "node.alpha.kubernetes.io/unreachable" operator: "Exists" effect: "NoExecute" tolerationSeconds: 6000
对于Node未就绪状态,可以把key设置为node.alpha.kubernetes.io/notReady。
如果没有为pod指定node.alpha.kubernetes.io/noReady的Toleration,那么Kubernetes会自动为pod加入tolerationSeconds=300的node.alpha.kubernetes.io/notReady类型的toleration。
同样,如果没有为pod指定node.alpha.kubernetes.io/unreachable的Toleration,那么Kubernetes会自动为pod加入tolerationSeconds=300的node.alpha.kubernetes.io/unreachable类型的toleration。
这些系统自动设置的toleration用于在node发现问题时,能够为pod确保驱逐前再运行5min。这两个默认的toleration由Admission Controller "DefaultTolerationSeconds"自动加入。
博主声明:本文的内容来源主要来自誉天教育晏威老师,由本人实验完成操作验证,需要的博友请联系誉天教育(http://www.yutianedu.com/),获得官方同意或者晏老师(https://www.cnblogs.com/breezey/)本人同意即可转载,谢谢!
标签:vol unknown ken 标签 erro val Fix identity ati
原文地址:https://www.cnblogs.com/zyxnhr/p/12189836.html