标签:als 分支 代码 package 方式 表达 外部 接口 局部变量
第一个简单的HelloGo程序hello.go
package main
import (
"fmt"
)
func main() {
fmt.Println("hello,Go!")
}注意:
main函数所在的包名必须是main
标识符用来定义变量、类型、常量等语法对象的符号名称,不能使用语言预留的标识符,会导致歧义
Go的标识符构规则:标识符由若干个字母、下划线_、和数字组成,且第一个字符必须是字母。字母区分大小写,Unicode可以作为标识符构成,但不建议这样使用。不能包含空格。
注意:
为变量、函数、常量命名时采用驼峰命名法,例如 stuName、getVal;
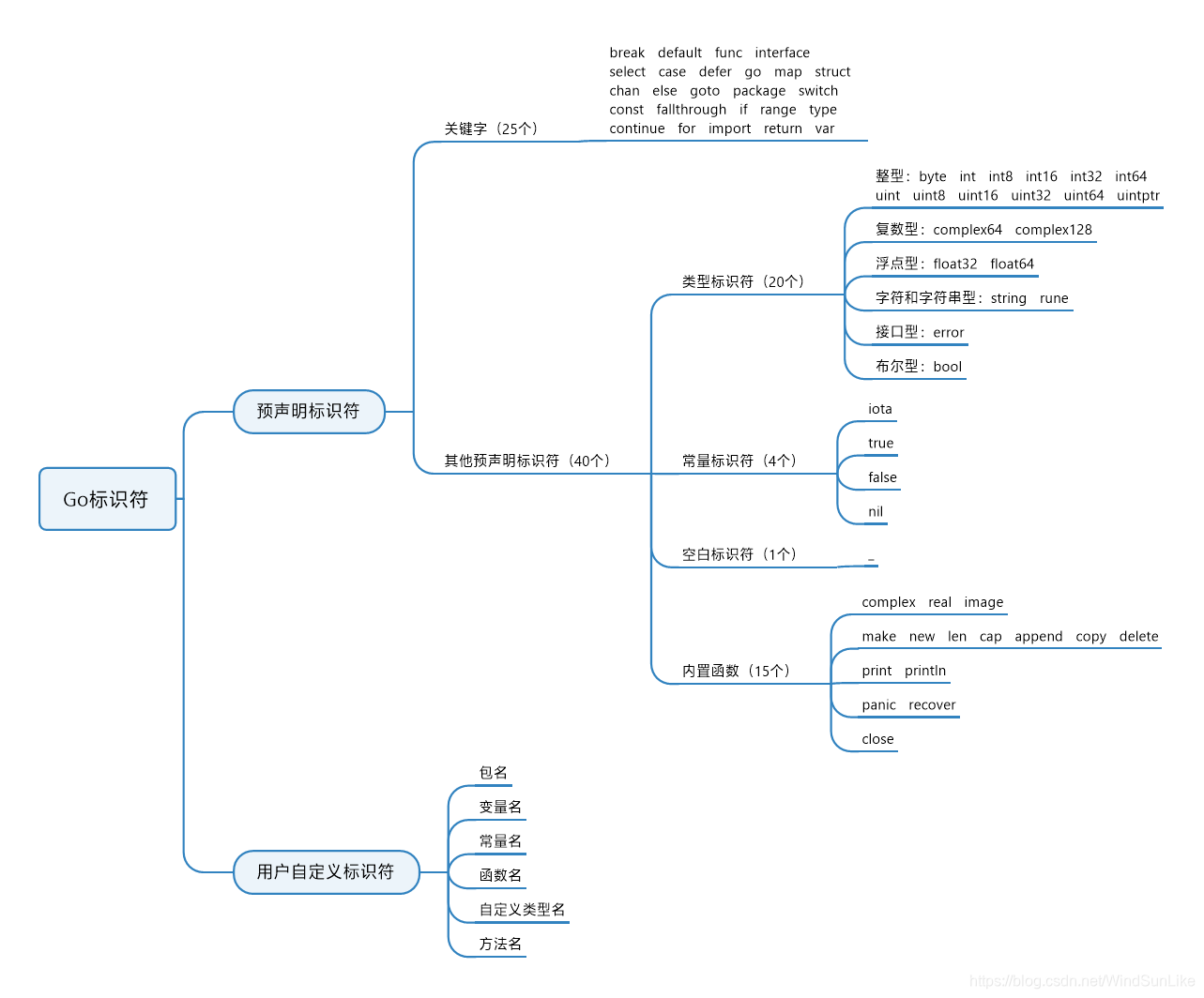
内置函数:是高级语言的一种语法糖,由于语言内置,不需要使用import来引入,内置函数具有全局可见性
通过一个标识符绑定一块内存地址,如果内训可以修改,则为变量,不能修改为常量
基本类型变量声明:
显示完整声明
var 变量名 类型 [ = 值]短类型声明
变量名 := 值Go 支持多个类型变量同时声明并赋值
如:
a , b := 1 , "hello"Go 语言提供自动内存管理,不需要关心变量的生存期和存放位置,编译器使用栈逃逸技术能够自动为变量分配空间:可能在栈上,也可能在堆上。
常量
常量分为布尔类型、字符串类型、数值型常量,存储在只读段里。
预声明标识符itoa用在常量声明中,初始值为0。一组多个常量同时声明其值逐行增加,itoa可以看作自增的枚举变量,专门用来初始化常量。
//类似枚举的iota
const (
c0 = iota // c0 == 0
c1 = iota // c1 == 1
c2 = iota // c2 == 2
)
//简写模式
const (
c0 = iota // c0 == 0
c1 // c1 == 1
c2 // c2 == 2
)
//分开的const语句
const x = iota // x == 0
const y = iota // y == 0布尔型
关键字bool,取值true和false
声明的bool变量如果不初始化,默认为false
var ok bool
ok = true或者
ok := falsebool类型与整数类型不能相互转换
bool类型用在:比较表达式和逻辑表达式的结果,if和for的条件部分一定是布尔类型的值或表达式
整型
不同类型的整形必须进行强制类型转换
var a int = 1
var b int32 = 2
b = a //error整形支持算术运算和位运算,算术表达式和位操作的结果还是整型
var a int = (1 + 2) * 3
var b int = 1000 >> 2浮点型
用于表示包含小数数据,有两种类型分别是float32和float64
浮点数自动类型推倒位float64
var b := 10.00 计算机很难对浮点型数精确存储,两个浮点数之间不要用==或!=进行比较,高精度科学计算使用math
复数型
在计算机中使用两个浮点数表示,一个表示实部,一个表示虚部,complex64是由两个float32构成的,complex128是由两个float64构成的。复数的字面量表示和数学表示法一样。
var v1 complex64 = 3.1 + 5i
v2 := 3.1 + 6i
//Go有三个函数处理复数
var v = complex(2.1, 3) //构造一个复数
a := real(v1) //返回复数的实部
b := image(v2) //返回复数的虚部字符串类型
var a = "hello world"var a = "hello,world"
b := a[0]
a[1] = 'a' //errora := "hello,world"
b := []byte(a)type stringStruct struct {
str unsafe.Pointer //指向底层字节数组的指针
len int //字节数组的长度
}a := "hello,world"
b := a[0:4]
c := a[1:]
d := a[:4]a := "hello,world"
b := []byte(a)
c := []rune(a)a := "hello"
b := "world"
c := a + b //字符串拼接
len(a) //len函数获取字符串的长度
d := "hello,世界"
//遍历字节数组
for i := 0; i<len(d); i++ {
fmt.Println(d[i])
}
//遍历rune数组
for i, v :=range d {
fmt.Println(i,v)
}rune类型
Go内置两种字符类:1.byte的字节类型;2.表示Unicode编码的字符rune。
rune在Go内部是int32类型的别名,占用4个字节。
Go语言默认字符编码就是UTF-8类型的,如果需要特殊的编码转换,使用Unicode/UTF-8标准包。
复合类型是由其他类型组合而成的类型。
Go的基本符合数据类型有:指针、数组、切片、字典、通道、结构、接口。
指针
指针的声明类型为*T, Go同样支持多级指针**T。通过在变量名前面加&来获取变量的地址。
var a =ll
p := &a.”点操作符,Go语言没有“>”操作符。 type User struct {
name string
age int
}
andes := User{
name: "andes",
age: 18,
}
p := &andes
fmt.Println(p.name) //p.name通过“.”操作符访问成员变量 a := 1234
p := &a
p++ //不允许,报non-numeric type*int错误func sum(a, b int) *int {
sum := a + b
return &sum //允许,sum会分配在heap上
}数组
数组的类型名是[n]类型,其中n是数组长度。比如一个包含2个int类型元素的数组类型可表示为[2]int。数组一般在创建时通过字面量初始化,单独声明一个数组类型变量而不进行初始化是没有意义的。
var arr [2]int //声明一个有两个整型的数组,但元素默认值都是0,一般很少这样使用
array := [...]float64{7.0, 8.5, 9.1} //[...1后面跟字面量初始化列表a := [3]int{1, 2, 3} //指定长度和初始化字面量
a := [...]int{1, 2, 3} //不指定长度,但是由后面的初始化列表数量来确定其长度
a := [3]int{1: 1, 2: 3} //指定总长度,并通过索引值进行初始化,没有初始化元素时使用类型默认值
a := [...]int{1: 1, 2: 3} //不指定总长度,通过索引值进行初始化,数组长度由最后一个索引值确定,没有指定索引的元素被初始化为类型的零值a := [...]int{1, 2, 3}
b := a[0]
for i,v := range a {
//...
}a :=[...]int{1,2,3}
alength := len(a)
for i:=0; i<alength; i++ {
//...
}切片(slice)
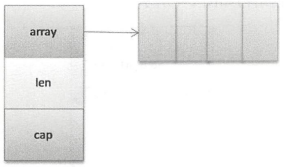
数组的定长性和值拷贝限制了其使用场景,Go提供了另一种数据类型slice(切片),这是一种变长数组,其数据结构中有指向数组的指针,所以是一种引用类型。
在Go中,几乎所有场景,可以使用切片代替数组
ll type slice struct {
array unsafe.Pointer
len int
cap int
}Go为切片维护三个元素:指向底层数组的指针、切片的元素数量、底层数组的容量。
array [begin:end].end-begin个元素的切片(切片容量),第一个元素是aray[b],最后一个元素是array[e-1]。var array = [...]int{0, 1, 2, 3, 4, 5, 6}
s1 := array[0:4] //[0 1 2 3]
s2 := array[:4] //[0 1 2 3]
s3 := array[2:] //[2 3 4 5 6]a := make([]int, 10) //len = 10, cap = 10, 结果为[0 0 0 0 0 0 0 0 0 0]
b := make([]int, 10, 15) //len = 10, cap = 15, 结果为[0 0 0 0 0 0 0 0 0 0]var a []int //结果为[]直接声明切片类型变量是没有意义的,此时切片的底层的数据结构

a := [...]int{0, 1, 2, 3, 4, 5, 6}
b := make([]int, 2, 4)
c := a[0:3]
fmt.Println(len(b)) //2
fmt.Println(cap(b)) //4
b = append(b, 1)
fmt.Println(b) //[0 0 1]
fmt.Println(len(b)) //3
fmt.Println(cap(b)) //4
b = append(b, c...)
fmt.Println(b) //[0 0 1 0 1 2]
fmt.Println(len(b)) //6
fmt.Println(cap(b)) //cap(b)=8,底层数组发生扩展
d := make([]int, 2, 2)
copy(d, c) //copy只会复制d和c中长度最小的
fmt.Println(d) //[0 1]
fmt.Println(len(d)) //2
fmt.Println(cap(d)) //2注意:
向切片增加元素时,切片的容量会自动增长。1024 以下时,一两倍方式增长。
str := "hello world"
a := []byte(str) ///将字符串转换为[]byte类型切片
b := []tune(str) //将字符串转换为[]rune类型切片字典(map)
Go语言内置的字典类型叫map。map的类型格式是:map[K]T,其中K可以是任意可以进行比较的类型,T是值类型。map也是一种引用类型。
ma := map[string]int {"a":1,"b":2}
fmt.Println(ma["a"])
fmt.Println(ma["b"])make(map[k]T) //map的容量使用默认位
make(map[K)T , len) //map 的容量使用给定 len 值
mpl := make(map[int]string)
mp2 := make(map[int]string , 10)
mpl[1] = "tom"
mp2[1] = "pony"delete(mapName,key)。delete是内置函数,用来删除map中的某个键值对。 mp := make(map[int]string)
mp[1] = "tom"
mp[2] = "pony"
mp[3] = "jaky"
delete(mp, 3)
fmt.Println(len(mp)) //2
for k, v := range mp {
fmt.Println("key=", k, "value=", v)
}
//key= 1 value= tom
//key= 2 value= pony注意:
Go内置的map不是并发安全的,并发安全的map可以使用标准包sync中的map。
不要直接修改map value内某个元素的值,如果想修改map的某个键值,则必须整体赋值。
type User struct {
name string
age int
}
ma := make(map[int]User)
andes := User{
name: "andes",
age: 18,
}
ma[1] = andes
//ma[1].age = 19 //ERROR ,不能通过 map 引用直接修改
andes.age = 19
ma[1] = andes //必须整体替换 value
fmt.Printf(" %v\n", ma) //map[1:{andes 19}]结构体(struct)
Go中的struct类型和C类似,由多个不同类型元素组合而成。这里面有两层含义:
第一,struct结构中的类型可以是任意类型;
第二,struct的存储空间是连续的,其字段按照声明时的顺序存放(注意字段之间有对齐要求)。
struct有两种形式:
一种是struct 类型字面量;
另一种是使用type声明的自定义struct类型。
struct {
FeildName FeildType
FeildName FeildType
FeildName FeildType
}type TypeName struct {
FeildName Fe ldType
FeildName FeildType
FeildName FeildType
}实际使用struct字面量的场景不多,更多的时候是通过type自定义一个新的类型来实现的。
type是自定义类型的关键字,不但支持struct类型的创建,还支持任意其他子定义类型的创建。
type Person struct {
Name string
Age int
}
type Student struct {
*Person
Number int
}
//不推荐这种初始化方式,一旦truct加字段,则整个初始化语句会报
a := Person{"Tom", 21}
//推荐这种使用 Feild 名字的初始化方式,没有指定的字段则默认初始化为类型的零值
p := &Person{
Name: "tata",
Age: 12,
}
s := Student{
Person: p,
Number: 110,
}现代计算机存储结构无论“普林斯顿结构”,还是“哈佛结构”,程序指令都是线性地存放在存储器上。程序执行从本质上来说就是两种模式:顺序和跳转。
顺序就是按照程序指令在存储器上的存放顺序逐条执行。
跳转就是遇到跳转指令就跳转到某处继续线性执行。
顺序在Go里面体现在从main函数开始逐条向下执行,就像我们的程序源代码顺序一样;跳转在Go里面体现为多个语法糖,包括goto语句和函数调用、分支(if、switch、select)、循环(for)等。
跳转分为两种:一种是无条件跳转,比如函数调用和goto语句;一种是有条件的跳转,比如分支和循环。
if 语句
if后面的条件判断子句不需要用小括号括起来。
{必须放在行尾,和if或if else放在一行。
if后面可以带一个简单的初始化语句,并以分号分割,该简单语句声明的变量的作用域是整个if语句块,包括后面的else if和else分支。
Go语言没有条件运算符(a>b?a:b),这也符合Go的设计哲学,只提供一种方法做事情。
if分支语句遇到return后直接返回,遇到break则跳过break下方的if语句块。
if x <= y {
return y
} else {
return x
}完整的if else 实例
if x := f(); x < y {
return x
} else if x > z {
return z
} else {
return y
}switch 语句
switch 语句会根据传入的参数检测井执行符合条件的分支。
switch和if 语句一样,switch后面可以带一个可选的简单的初始化语句。
switch后面的表达式也是可选的,如果没有表达式,则case子句是一个布尔表达式,而不是一个值,此时就相当于多重if else语句。
switch条件表达式的值不像C语言那样必须限制为整数,可以是任意支持相等比较运算的类型变量。
通过fallthough 语句来强制执行下一个case子句(不再判断下一个case子句的条件是否满足)。
switch 支持default 语句,当所有的case分支都不符合时,执行default 语句,并且default语句可以放到任意位置,并不影响 switch的判断逻辑。
switch和.(type)结合可以进行类型的查询,这个放到4.2节介绍。
switch i := "y"{//switch 后面可以带上一个初始化语
case "y","Y": //多个 case 值使用逗号分隔
fmt.Println ("yes") //yes
fallthrough //fallthrough 会跳过接下来的 case 条件表达式,直接执行下一 case 语句
case "n","N":
fmt Println("no") //no
}附加:
select 是一种类似于switch语法结构的分支语句。
for 语句
Go语言仅支持一种循环语句,即for语句。
Go对应C循环的三种场景如下。
for init;condition;post{ }for condition{ }for{ }//访问map
for key, value := range map {}
for key := range map {}
//访问数组
for index, value := range array {}
for index := range array {}
for _, value := range array {}
//访问切片
for index, value := range slice {}
for index := range slice {}
for _, value := range slice {}
//访问通道
for value := range channel {}Go 语言使用标签(Lable)来标识一个语句的位置,用于goto、break、continue 语句的跳转,标签的语法是Lable:Statement。
goto Lable goto Lable的语义是跳转到标签名后的语句处执行,goto语句有以下几个特点:
goto L //BAD,跳过v:=3这条语句是不允许的
V:=3
L:goto 语句只能跳到同级作用域或者上层作用域内,不能跳到内部作用域内。例如:
if n%2==1{
goto L1
}
for n > 0 {
f()
n--
}
L1:
fn()
n--L1:
for i := 0; ; i++ {
for j := 0; ; j++ {
if i >= 5 {
break L1 //跳出L1标签所在的for循环break L1
}
if j > 10 {
break //默认仅跳出离break最近的内层循环break
}
}
}L1:
for i := 0; ; i++ {
for j := 0; ; j++ {
if i >= 5 {
continue L1 //跳出L1标签所在的for循环i++处执行
}
if j > 10 {
continue //默认仅跳出离continue最近的内层循环j++处执行
}
}
}标签:als 分支 代码 package 方式 表达 外部 接口 局部变量
原文地址:https://www.cnblogs.com/WindSun/p/12208321.html