概述
snowflake是Twitter开源的分布式ID生成算法,结果是一个Long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的序列号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
特点:
- 作为ID,肯定是唯一的;
- 自增,依赖时间戳生成,序列号有序递增;
- 支持非常大的业务ID生成,最大支持2^10=1024个业务节点,同一个节点一毫秒最多生成2^12=4096个ID,41位毫秒级时间可以使用(2^41 - 1)/(1000*60*60*24*365)=69.73,大约70年;
- 实现简单,不依赖于其他第三方组件,甚至都不需要任何import。
结果是一个Long型的ID,64位,结构图如下:
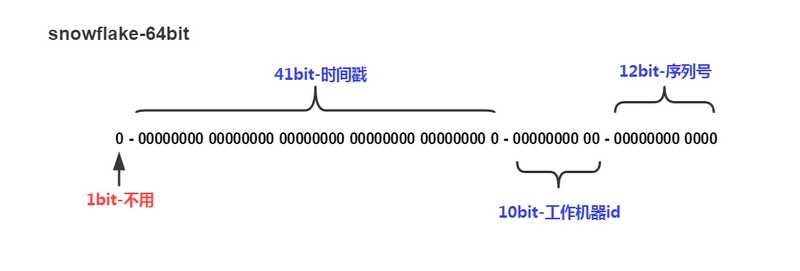
- 第1位固定是0,表示正数;
- 第2-42共41位表示时间戳,当前时间的时间戳减去开始时间的时间戳;
- 业务节点ID,每个节点固定的值;
- 毫秒内的序列号。
实现
清楚了结构后,就比较好实现了。
41bit-时间戳
当前时间的时间戳减去开始时间的时间戳,左移22位
(ts - beginTs) << timestampLeftOffset
10bit-工作机器ID
自定义的业务节点ID,固定的值,左移12位
workerId << workerIdLeftOffset
12bit-序列号
毫秒内序列号,以此递增,如果溢出就阻塞到下一秒从0开始计数

// 同一时间内,则计算序列号
if (ts == lastTimestamp) {
// 序列号溢出
if (++sequence > maxSequence) {
ts = tilNextMillis(lastTimestamp);
sequence = 0L;
}
} else {
// 时间戳改变,重置序列号
sequence = 0L;
}
lastTimestamp = ts;
/**
* 阻塞到下一个毫秒
*
* @param lastTimestamp
* @return
*/
private long tilNextMillis(long lastTimestamp) {
long ts = System.currentTimeMillis();
while (ts <= lastTimestamp) {
ts = System.currentTimeMillis();
}
return ts;
}
生成最终的ID
return (ts - beginTs) << timestampLeftOffset | workerId << workerIdLeftOffset | sequence;
完整代码
最后贴出完整代码。
public class SnowflakeIdWorker {
/**
* 开始时间:2020-01-01 00:00:00
*/
private final long beginTs = 1577808000000L;
private final long workerIdBits = 10;
/**
* 2^10 - 1 = 1023
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
private final long sequenceBits = 12;
/**
* 2^12 - 1 = 4095
*/
private final long maxSequence = -1L ^ (-1L << sequenceBits);
/**
* 时间戳左移22位
*/
private final long timestampLeftOffset = workerIdBits + sequenceBits;
/**
* 业务ID左移12位
*/
private final long workerIdLeftOffset = sequenceBits;
/**
* 合并了机器ID和数据标示ID,统称业务ID,10位
*/
private long workerId;
/**
* 毫秒内序列,12位,2^12 = 4096个数字
*/
private long sequence = 0L;
/**
* 上一次生成的ID的时间戳,同一个worker中
*/
private long lastTimestamp = -1L;
public SnowflakeIdWorker(long workerId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("WorkerId必须大于或等于0且小于或等于%d", maxWorkerId));
}
this.workerId = workerId;
}
public synchronized long nextId() {
long ts = System.currentTimeMillis();
if (ts < lastTimestamp) {
throw new RuntimeException(String.format("系统时钟回退了%d毫秒", (lastTimestamp - ts)));
}
// 同一时间内,则计算序列号
if (ts == lastTimestamp) {
// 序列号溢出
if (++sequence > maxSequence) {
ts = tilNextMillis(lastTimestamp);
sequence = 0L;
}
} else {
// 时间戳改变,重置序列号
sequence = 0L;
}
lastTimestamp = ts;
// 0 - 00000000 00000000 00000000 00000000 00000000 0 - 00000000 00 - 00000000 0000
// 左移后,低位补0,进行按位或运算相当于二进制拼接
// 本来高位还有个0<<63,0与任何数字按位或都是本身,所以写不写效果一样
return (ts - beginTs) << timestampLeftOffset | workerId << workerIdLeftOffset | sequence;
}
/**
* 阻塞到下一个毫秒
*
* @param lastTimestamp
* @return
*/
private long tilNextMillis(long lastTimestamp) {
long ts = System.currentTimeMillis();
while (ts <= lastTimestamp) {
ts = System.currentTimeMillis();
}
return ts;
}
}
补充
这里面有大量的二进制位运算,目的只有一个:快。
规则:1为真,0为否,其实就是同位之间的布尔运算。
按位与:&
都为真就是真,其他都是否
1&1=1 1&0=0 0&1=0 0&0=0
按位或:|
只要有一个真就是真
1|1=1 1|0=1 0|1=1 0|0=0
异或:^
相同就是否,不同就是真
1^1=0 1^0=1 0^1=1 0^0=0
左移:<<
所有位向左移动多少位,低位补0,高位多出的直接删掉
右移:>>
所有位向右移动多少位,低位多出的删掉,高位是0补0,是1就补1
Java中的原码、补码和反码
原码
原码就是十进制数字的原始二进制表示,对于整数而言,最高位为符号位,1表示负数,0表示正数。以32位int型的整数2及-2举例:
2的原码:00000000 00000000 00000000 00000010
-2的原码:10000000 00000000 00000000 00000010
反码
正数的反码就是其原码,负数的反码除了最高位的符号位外,其他位取反(0改1,1改0)
2的反码:00000000 00000000 00000000 00000010
-2的反码:11111111 11111111 11111111 11111101
补码
正数的补码就是其原码,负数的补码是其反码加1
2的补码:00000000 00000000 00000000 00000010
-2的反码:11111111 11111111 11111111 11111101
-2的补码:11111111 11111111 11111111 11111110