标签:手动 大量 优雅 信号 主程 因此 防止 roc 网络超时
我们知道大量请求会阻塞在Tomcat服务器上,影响其它整个服务.在复杂的分布式架构的应用程序有很多的依赖,都会不可避免地在某些时候失败.高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险.
Spring Cloud Netflix Hystrix就是隔离措施的一种实现,可以设置在某种超时或者失败情形下断开依赖调用或者返回指定逻辑,从而提高分布式系统的稳定性.
生活中举个例子,如电力过载保护器,当电流过大的的时候,出问题,过载器会自动断开,从而保护电器不受烧坏。因此Hystrix请求熔断的机制跟电力过载保护器的原理很类似。
比如:订单系统请求库存系统,结果一个请求过去,因为各种原因,网络超时,在规定几秒内没反应,或者服务本身就挂了,这时候更多的请求来了,不断的请求库存服务,不断的创建线程,因为没有返回,也就资源没有释放,
这也导致了系统资源被耗尽,你的服务奔溃了,这订单系统好好的,你访问了一个可能有问题的库存系统,结果导致你的订单系统也奔溃了,你再继续调用更多的依赖服务,可会会导致更多的系统奔溃,这时候Hystrix可以实现快速失败,
如果它在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断地尝试执行可能会失败的操作进而导致资源耗尽。这时候Hystrix进行FallBack操作来服务降级,
Fallback相当于是降级操作. 对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值. fallback方法的返回值一般是设置的默认值或者来自缓存.通知后面的请求告知这服务暂时不可用了。
使得应用程序继续执行而不用等待修正错误,或者浪费CPU时间去等到长时间的超时产生。Hystrix熔断器也可以使应用程序能够诊断错误是否已经修正,如果已经修正,应用程序会再次尝试调用操作。
如下图所示:
![]() ?
?
1.防止单个服务的故障,耗尽整个系统服务的容器(比如tomcat)的线程资源,避免分布式环境里大量级联失败。通过第三方客户端访问(通常是通过网络)依赖服务出现失败、拒绝、超时或短路时执行回退逻辑
2.用快速失败代替排队(每个依赖服务维护一个小的线程池或信号量,当线程池满或信号量满,会立即拒绝服务而不会排队等待)和优雅的服务降级;当依赖服务失效后又恢复正常,快速恢复
3.提供接近实时的监控和警报,从而能够快速发现故障和修复。监控信息包括请求成功,失败(客户端抛出的异常),超时和线程拒绝。如果访问依赖服务的错误百分比超过阈值,断路器会跳闸,此时服务会在一段时间内停止对特定服务的所有请求
4.将所有请求外部系统(或请求依赖服务)封装到HystrixCommand或HystrixObservableCommand对象中,然后这些请求在一个独立的线程中执行。使用隔离技术来限制任何一个依赖的失败对系统的影响。每个依赖服务维护一个小的线程池(或信号量),当线程池满或信号量满,会立即拒绝服务而不会排队等待
1.请求熔断: 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN).
这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN). Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力.
2.服务降级:Fallback相当于是降级操作. 对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值. fallback方法的返回值一般是设置的默认值或者来自缓存.告知后面的请求服务不可用了,不要再来了。
3.依赖隔离(采用舱壁模式,Docker就是舱壁模式的一种):在Hystrix中, 主要通过线程池来实现资源隔离. 通常在使用的时候我们会根据调用的远程服务划分出多个线程池.比如说,一个服务调用两外两个服务,你如果调用两个服务都用一个线程池,那么如果一个服务卡在哪里,资源没被释放
后面的请求又来了,导致后面的请求都卡在哪里等待,导致你依赖的A服务把你卡在哪里,耗尽了资源,也导致了你另外一个B服务也不可用了。这时如果依赖隔离,某一个服务调用A B两个服务,如果这时我有100个线程可用,我给A服务分配50个,给B服务分配50个,这样就算A服务挂了,
我的B服务依然可以用。
4.请求缓存:比如一个请求过来请求我userId=1的数据,你后面的请求也过来请求同样的数据,这时我不会继续走原来的那条请求链路了,而是把第一次请求缓存过了,把第一次的请求结果返回给后面的请求。
5.请求合并:我依赖于某一个服务,我要调用N次,比如说查数据库的时候,我发了N条请求发了N条SQL然后拿到一堆结果,这时候我们可以把多个请求合并成一个请求,发送一个查询多条数据的SQL的请求,这样我们只需查询一次数据库,提升了效率。
Hystrixl流程图如下:
![]() ?
?
Hystrix流程说明:
1:每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中.
2:执行execute()/queue做同步或异步调用.
4:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤5.
5:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤6.
6:调用HystrixCommand的run方法.运行依赖逻辑
6a:依赖逻辑调用超时,进入步骤8.
7:判断逻辑是否调用成功
7a:返回成功调用结果
7b:调用出错,进入步骤8.
8:计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态.
9:getFallback()降级逻辑.以下四种情况将触发getFallback调用:
(1):run()方法抛出非HystrixBadRequestException异常。
(2):run()方法调用超时
(3):熔断器开启拦截调用
(4):线程池/队列/信号量是否跑满
9a:没有实现getFallback的Command将直接抛出异常
9b:fallback降级逻辑调用成功直接返回
9c:降级逻辑调用失败抛出异常
10:返回执行成功结果
这里接着前面的Ribbon进行Hystrix集成。说白了你想对一个请求进行熔断,必然不能让客户直接去调用那个请求,你必然要要对别人的请求进行包装一层和拦截,才能做点手脚,比如进行熔断,所以说要在Ribbon上动手脚。因为它是请求发起的地方。
我们刚开始请求一个服务,为了负载均衡进行了拦截一次,现在我们要进行熔断,所以必须跟Ribbon集成一次,再进行请求拦截来熔断。
以上的大段说明我是从别人那里抄来的,大体上就是说Hystrix能做两件事,一件是请求熔断,一件是服务降级;简单理解是如果请求服务错了,系统会给出熔断反馈;如果不想系统给出熔断反馈,能接受服务降级,那么我们可以采取服务降级(这个好理解,自行体会哈),下面开始代码实战:
![]() ?
?
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.xu</groupId>
<artifactId>service-consumer-hystrix-8766</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>service-consumer-hystrix-8766</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.M3</spring-cloud.version>
</properties>
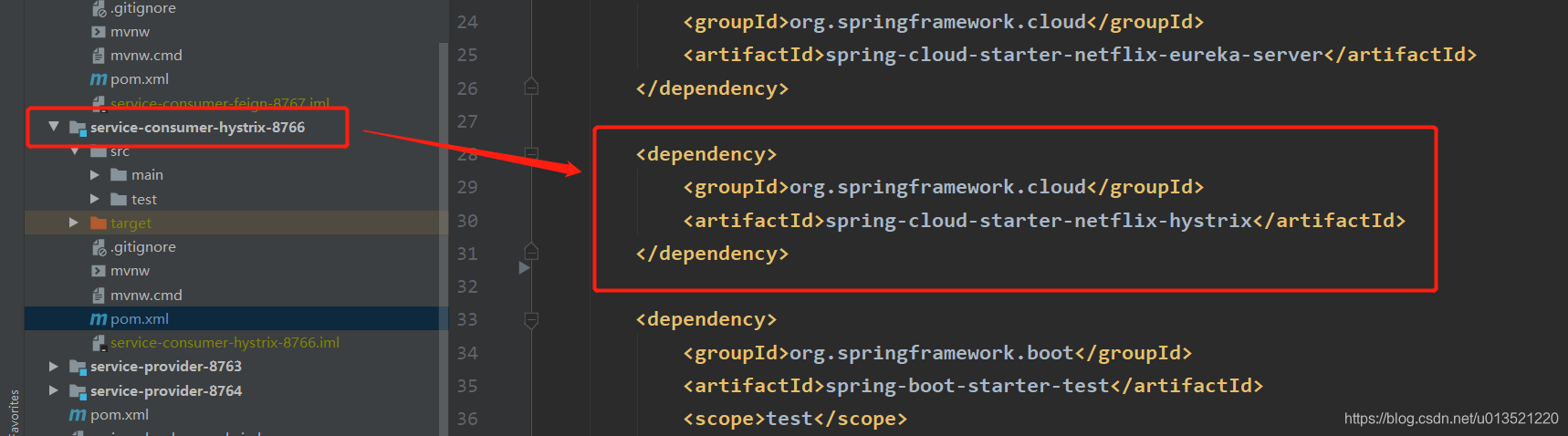
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.48</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories>
</project>
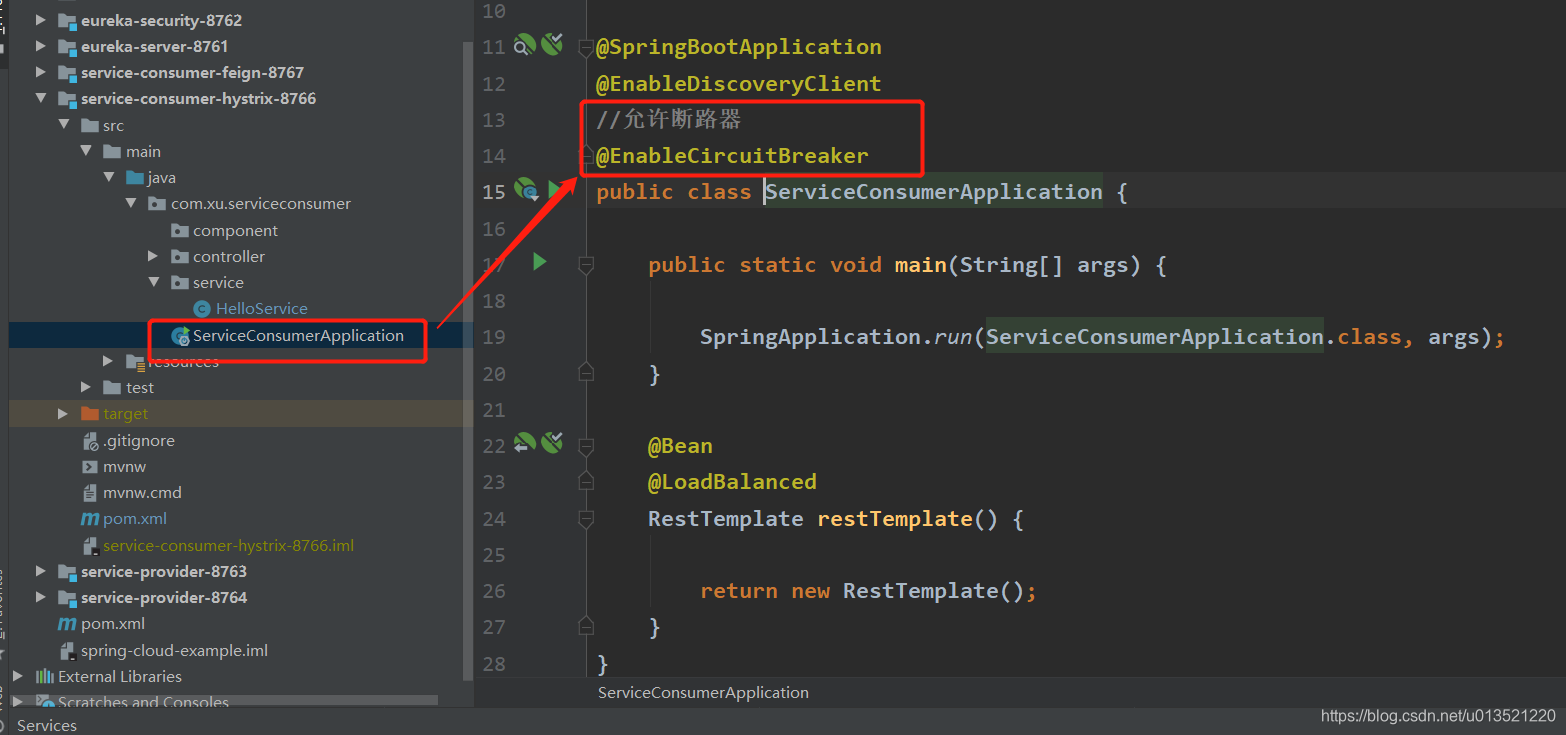
启动主程序添加注解@EnableCircuitBreaker,表示支持熔断 处理
![]() ?
?
package com.xu.serviceconsumer;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
@EnableDiscoveryClient
//允许断路器
@EnableCircuitBreaker
public class ServiceConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceConsumerApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
}
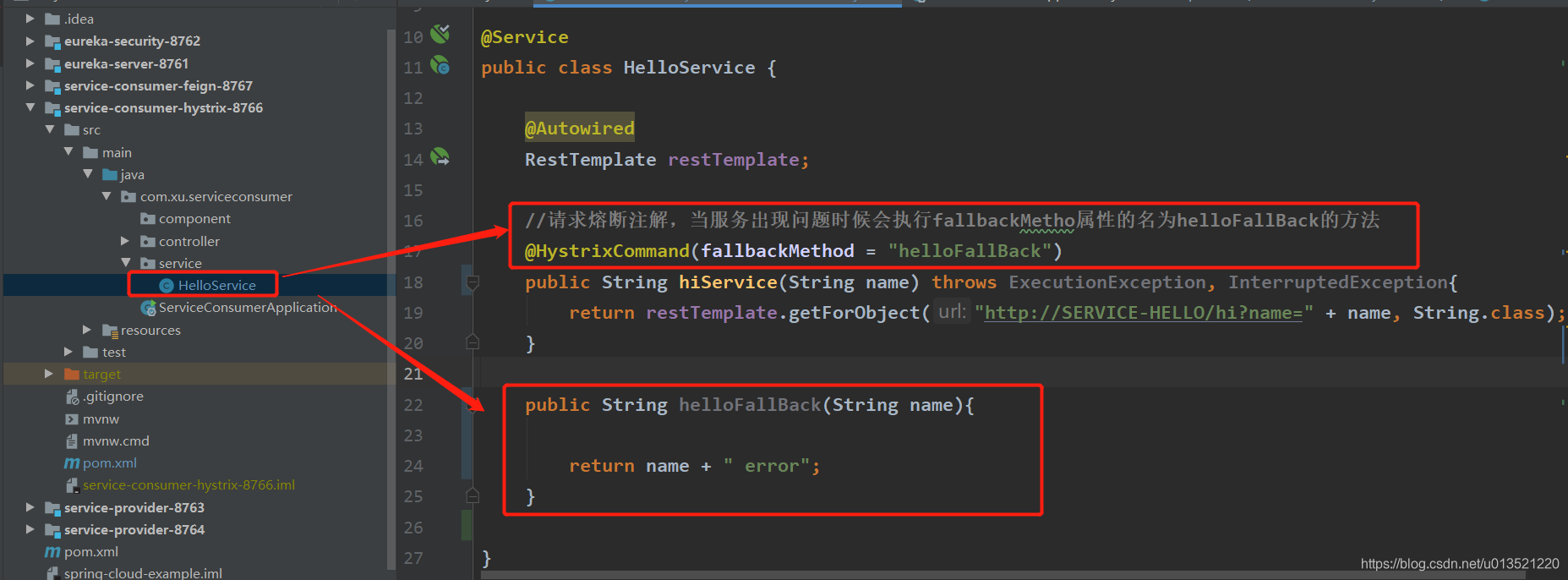
接下来看看Service部分怎么处理的:
![]() ?
?
package com.xu.serviceconsumer.service;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.concurrent.ExecutionException;
@Service
public class HelloService {
@Autowired
RestTemplate restTemplate;
//请求熔断注解,当服务出现问题时候会执行fallbackMetho属性的名为helloFallBack的方法
@HystrixCommand(fallbackMethod = "helloFallBack")
public String hiService(String name) throws ExecutionException, InterruptedException{
return restTemplate.getForObject("http://SERVICE-HELLO/hi?name=" + name, String.class);
}
public String helloFallBack(String name){
return name + " error";
}
}
这里要重点说明:helloFallBack方法里必须要跟上面一致带有一个参数helloFallBack(String name)的,否则系统会报错表示找不到容错处理方法,这一点务必注意!!!
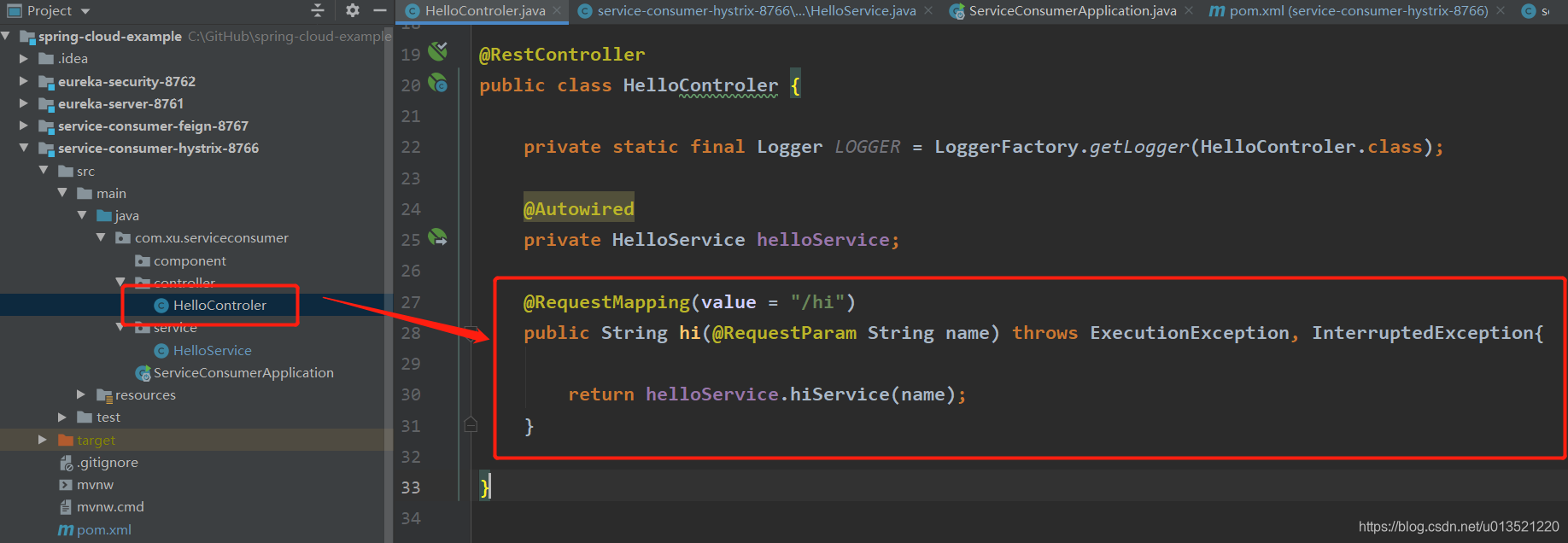
接下来我们写Controller,试着请求一下我们刚才写的Service,看看效果,这里要至少请求两次,一次是服务正常时候,一次是服务不正常(这里是手动关闭服务)
![]() ?
?
package com.xu.serviceconsumer.controller;
import com.alibaba.fastjson.JSONObject;
import com.fasterxml.jackson.databind.util.JSONPObject;
import com.xu.serviceconsumer.service.HelloService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ExecutionException;
@RestController
public class HelloControler {
private static final Logger LOGGER = LoggerFactory.getLogger(HelloControler.class);
@Autowired
private HelloService helloService;
@RequestMapping(value = "/hi")
public String hi(@RequestParam String name) throws ExecutionException, InterruptedException{
return helloService.hiService(name);
}
}
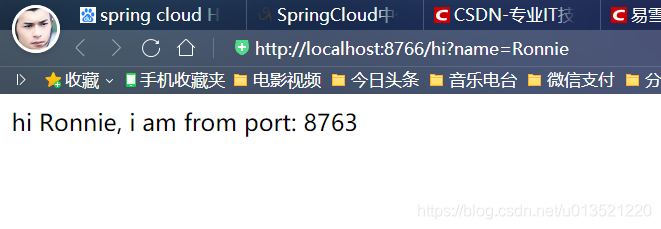
我们启动注册中心、启动服务提供者、启动我们的服务消费者,在浏览器里输入http://localhost:8766/hi?name=Ronnie
![]() ?
?
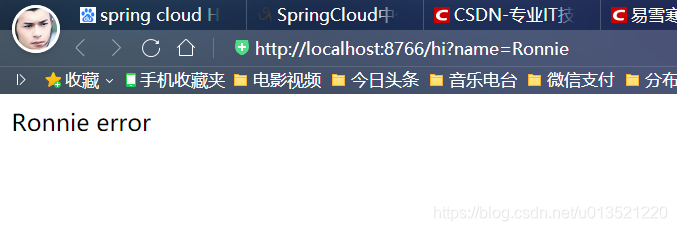
这里可以看到,我们成功请求了服务,现在手动关闭服务提供者(如果有多个服务提供者,都需要一一关闭,一个都不能留),再次请求,效果如下:
![]() ?
?
结合我们的代码可以知道,当我们的服务提供者出现异常或者不可用时候,熔断器把熔断处理里面的方法调用了,这就是请求熔断,接下来我们遇到有这么一个要求,我希望在服务提供者出现问题时候,自己设置一个服务让这个虚假的服务临时顶替一下,可不可以呢??当然是可以的,那就是服务降级吧,给你一个山寨版的服务,你先凑合的用一下,代码如下:
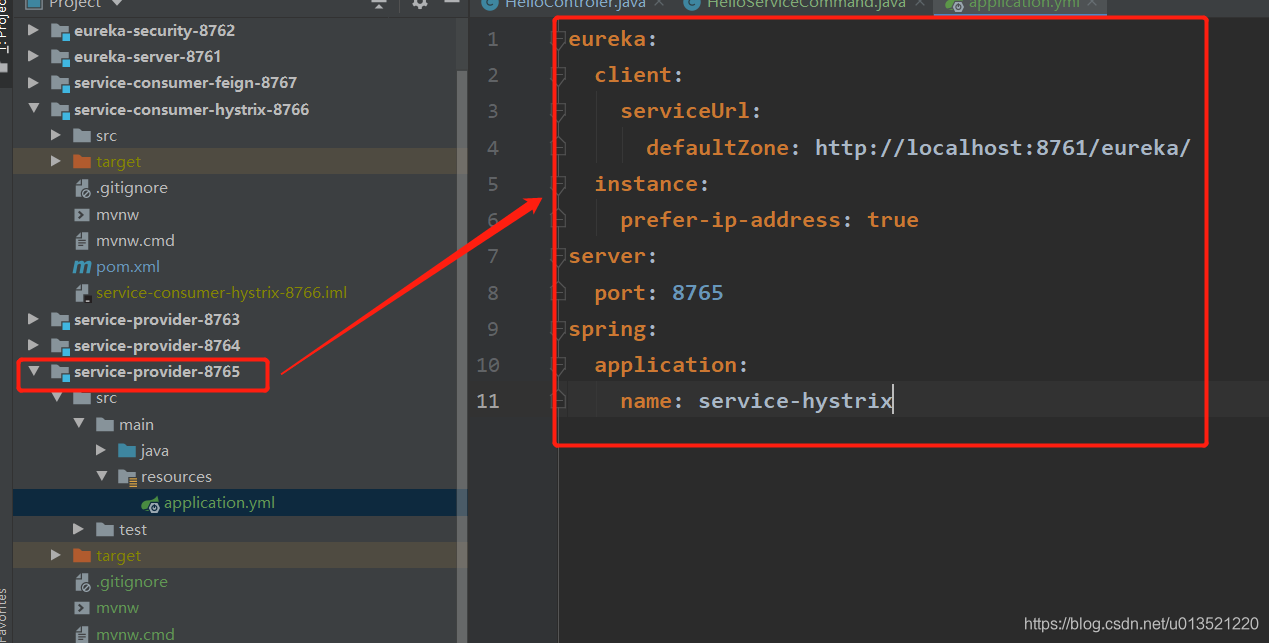
这里我们为了测试,复制一份provider修改他的名称和端口如下,作为我们的降级服务:
![]() ?
?
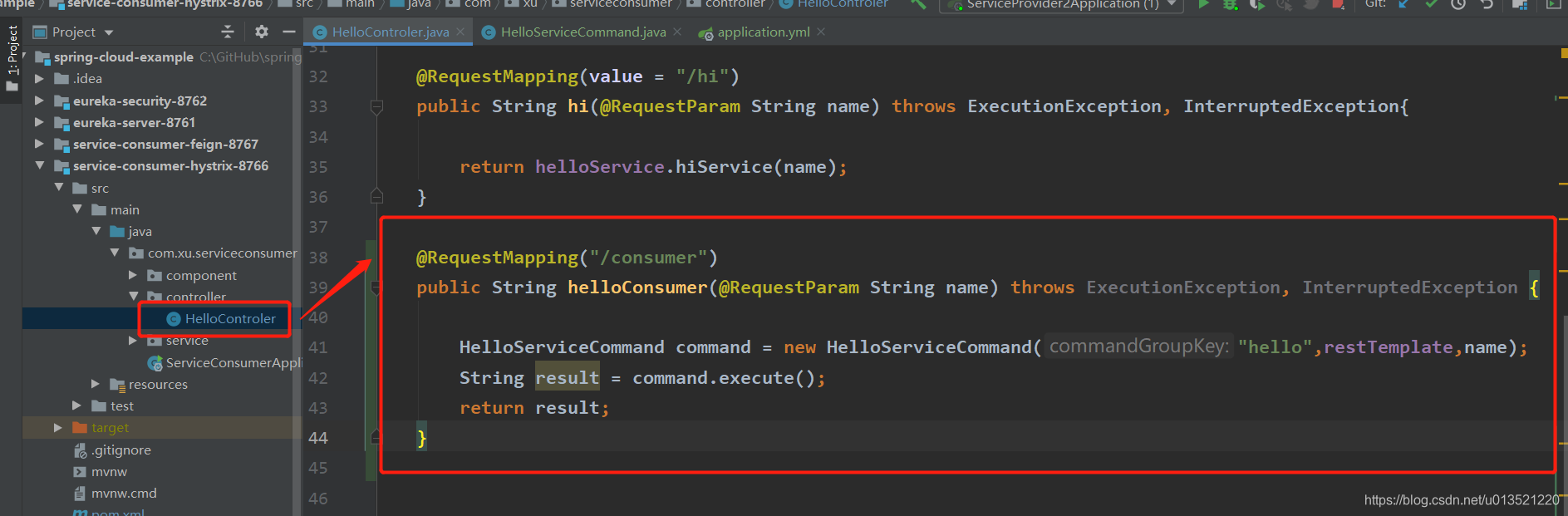
我们这次先看我们的Controller中是怎么调用的:
![]() ?
?
package com.xu.serviceconsumer.controller;
import com.alibaba.fastjson.JSONObject;
import com.fasterxml.jackson.databind.util.JSONPObject;
import com.xu.serviceconsumer.component.HelloServiceCommand;
import com.xu.serviceconsumer.service.HelloService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ExecutionException;
@RestController
public class HelloControler {
private static final Logger LOGGER = LoggerFactory.getLogger(HelloControler.class);
@Autowired
private RestTemplate restTemplate;
@Autowired
private HelloService helloService;
@RequestMapping(value = "/hi")
public String hi(@RequestParam String name) throws ExecutionException, InterruptedException{
return helloService.hiService(name);
}
@RequestMapping("/consumer")
public String helloConsumer(@RequestParam String name) throws ExecutionException, InterruptedException {
HelloServiceCommand command = new HelloServiceCommand("hello",restTemplate,name);
String result = command.execute();
return result;
}
}
从这里我们看到,我们不再是用Service或者RestTemplate对服务进行简单的调用了,而是构建了一个HelloServiceCommand,看来这里一切的奥秘都在这个HelloServiceCommand里了,我们马上看看这个东东到底写了啥:
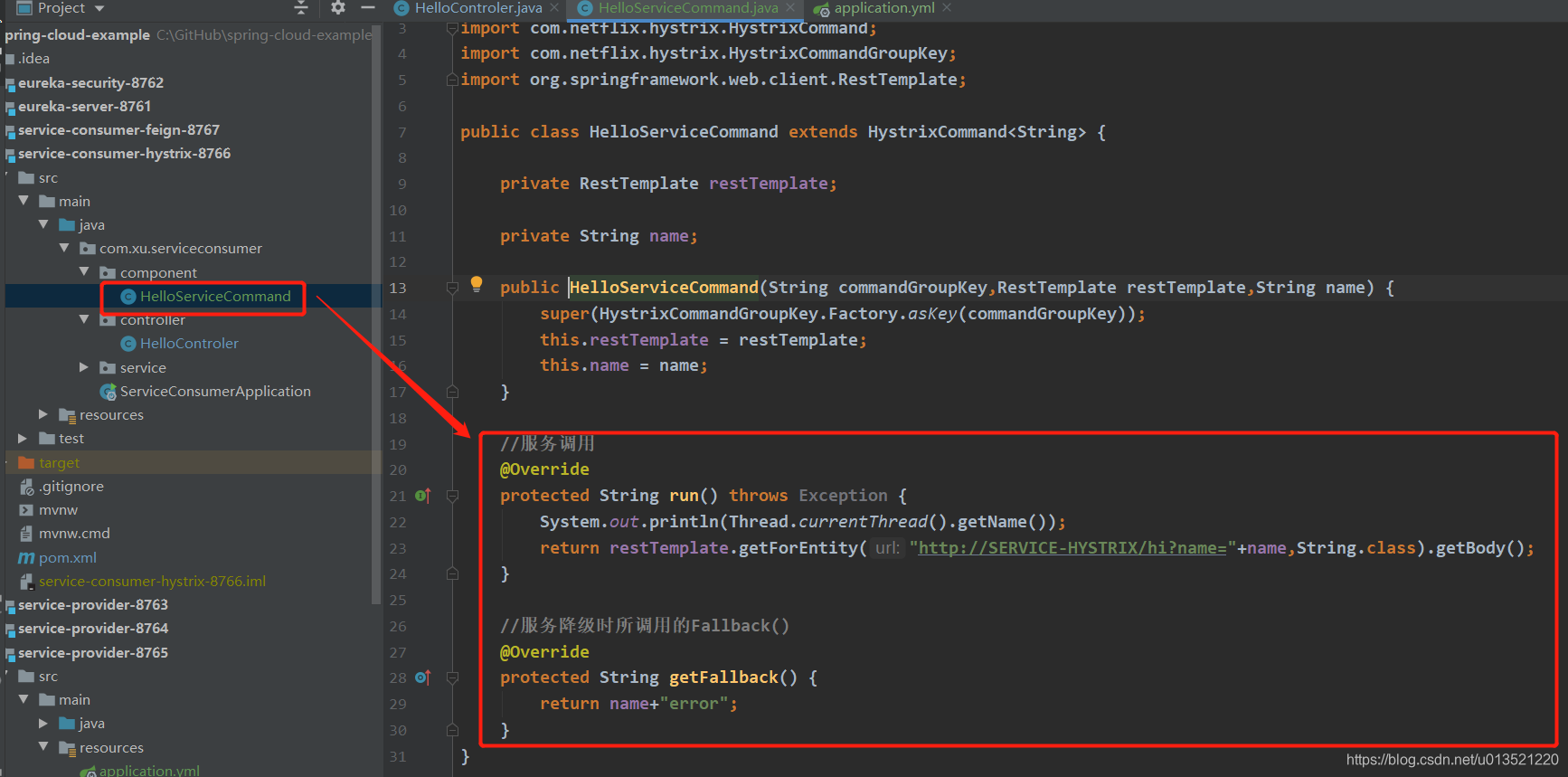
![]() ?
?
package com.xu.serviceconsumer.component;
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey;
import org.springframework.web.client.RestTemplate;
public class HelloServiceCommand extends HystrixCommand<String> {
private RestTemplate restTemplate;
private String name;
public HelloServiceCommand(String commandGroupKey,RestTemplate restTemplate,String name) {
super(HystrixCommandGroupKey.Factory.asKey(commandGroupKey));
this.restTemplate = restTemplate;
this.name = name;
}
//服务调用
@Override
protected String run() throws Exception {
System.out.println(Thread.currentThread().getName());
return restTemplate.getForEntity("http://SERVICE-HYSTRIX/hi?name="+name,String.class).getBody();
}
//服务降级时所调用的Fallback()
@Override
protected String getFallback() {
return name+"error";
}
}这里主要是有两个方法run()方法和getFallback()方法,这两个是父类定义的抽象方法,子类对他进行了重写,你看看子类是怎么重写的,先看run()方法,他调用了一个服务(这个服务是我们准备的一个降级备用服务),另一个方法是当降级服务出错时候调用的容错处理的方法,当我们的备用降级服务也出错了不可用的时候,就返回这个了,我们现在就来试试看,先正常访问我们的Controller中的http://localhost:8766/hi?name=Ronnie
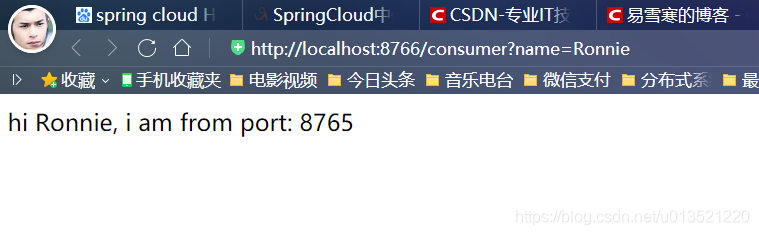
![]() ?
?
根据端口我们知道这是我们的备用降级服务被调用了,那么我现在关闭这个降级服务再次调用会出现什么呢??
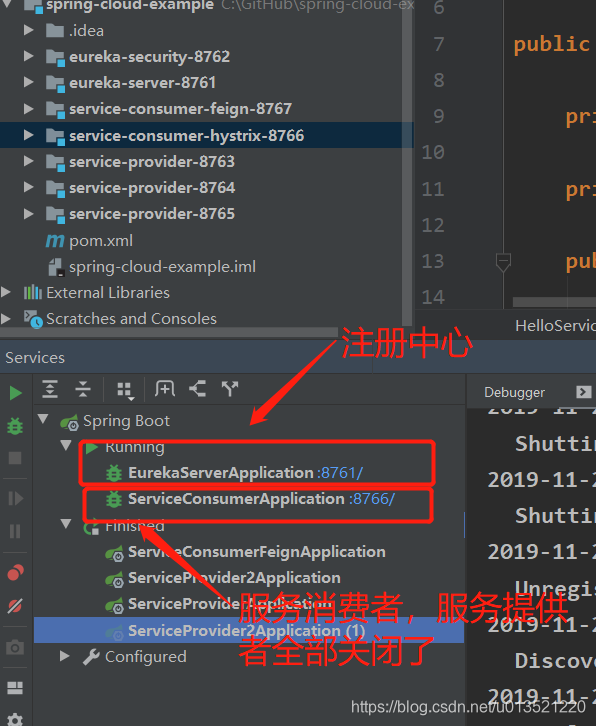
![]() ?
?
刷新http://localhost:8766/hi?name=Ronnie
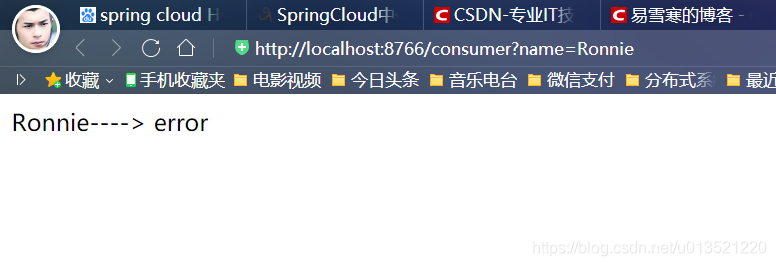
![]() ?
?
一切都在我们意料之中,大功告成,剩下的就是留给你们自己慢慢的回味和感受了,see you next time!
SpringCloud学习之Hystrix请求熔断与服务降级(六)
标签:手动 大量 优雅 信号 主程 因此 防止 roc 网络超时
原文地址:https://www.cnblogs.com/xulijun137/p/12209739.html