标签:style blog http io color ar os sp strong
原文:(原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 顺序分析和聚类分析算法)前言
本篇文章继续我们的微软挖掘系列算法总结,前几篇文章已经将相关的主要算法做了详细的介绍,我为了展示方便,特地的整理了一个目录提纲篇:大数据时代:深入浅出微软数据挖掘算法总结连载,有兴趣的童鞋可以点击查阅,本篇我们将要总结的算法为:Microsoft顺序分析和聚类分析算法,此算法为上一篇中的关联规则分析算法的一个延伸,为关联规则分析算法所形成的种类进行了更细粒度的挖掘,挖掘出不同种类内部的事例间的顺序原则,进而用以引导用户进行消费。
应用场景介绍
Microsoft顺序分析和聚类分析算法,根据名称就可以联想到其应用特点,该挖掘算法是基于聚类分析算法之上然后对其分类内的事例顺序进行挖掘,其分析的重点在于事例间的顺序规则,上一篇我们介绍的Microsoft关联规则算法它的重点在于挖掘事例间的关联关系,而对产生关联关系的顺序则不关系,简单点讲:关联规则算法研究的是“鸡与蛋的关系”,而顺序分析和聚类分析算法则研究的就是“先有鸡还是先有蛋的问题”,上一篇文章中我们挖掘出几组产品间关联关系最强的,比如:山地自行车、轮胎和内胎;自行车、水壶、水壶框,这几种产品关联关系最强,也就是说客户想买其中的一些产品,就会产生最大可能的购买其他相关的产品,但是购买这几种产品的顺序是什么样的呢?
Microsoft顺序分析好聚类分析算法常用的场景:
1、网站中的浏览网站所产生的web点击流,进而进行用户行为预测
2、发生事故(比如服务器宕机、数据库死锁等)之前的事件日志,进而预测下一次事故发生的点
3、根据用户发生购买、添加购物车的顺序记录,根据产品优先级进行最佳产品推荐
其实该算法应用场景类似于聚类分析算法,但相比而言此算法更细粒度化,对聚类中的事例间的顺序进而进行挖掘。
技术准备
(1)微软案例数据仓库(AdventureWorksDW208R2),和上一篇的关联规则用到的表一样,两张表:vAssocSeqLineItems 表和 vAssocSeqOrders 表,这两张表典型的“一对多”的关联关系,vAssocSeqOrders为订单表,vAssocSeqLineItems 表为订单明细表,两者通过OrderNumber关联,具体内容可参照上篇博客:Microsoft 关联规则分析算法
(2)VS2008、SQL Server、 Analysis Services
操作步骤
(1)我们这里还是利用上一期的解决方案,数据源视图同样也是继续沿用,直接看图
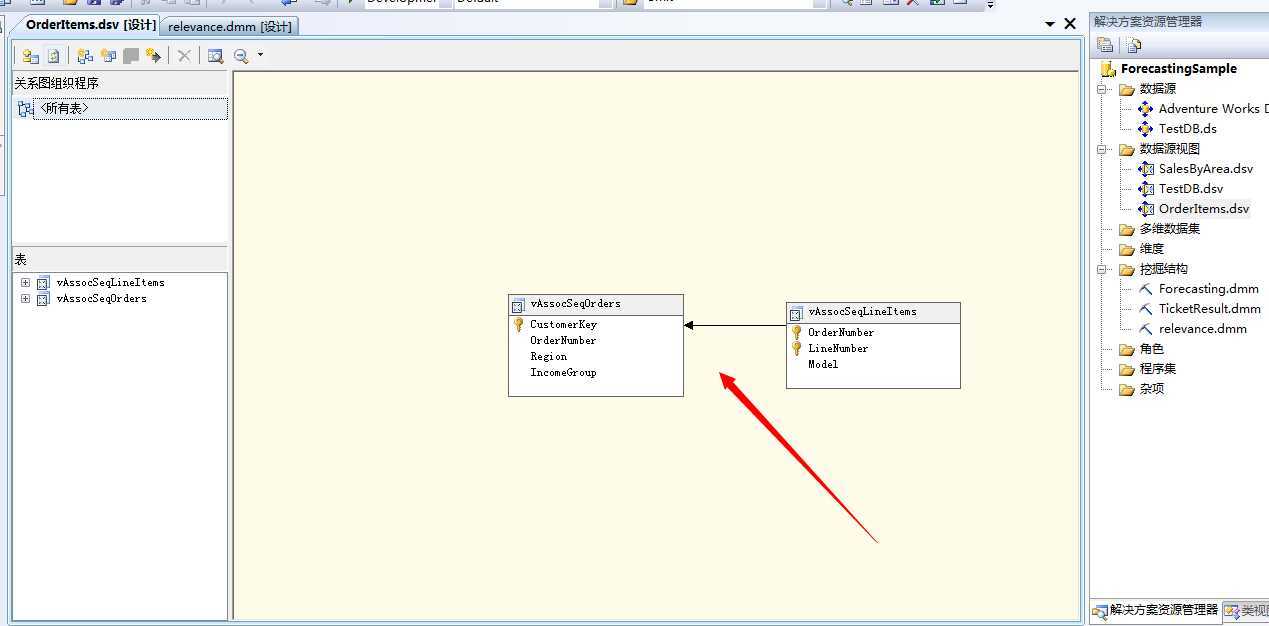
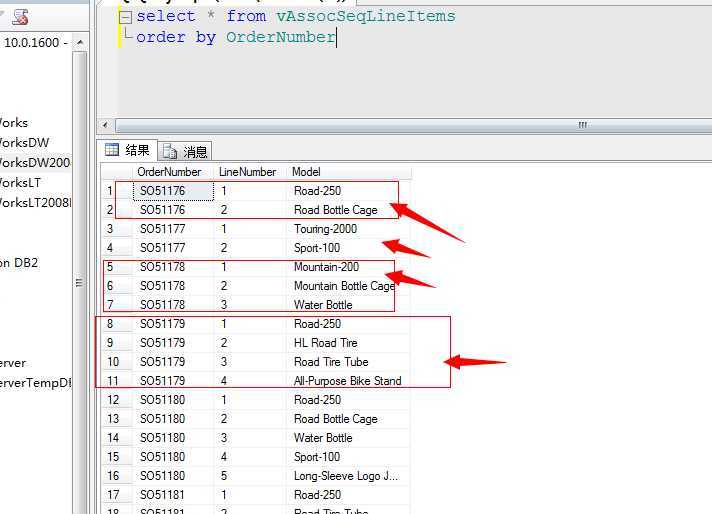
其实这里面应用的最重要的一列就是LineNumber列,该列记录的就是产品的购买顺序,进而就是反应顺序规则,我们来浏览一下该数据:
(2)新建挖掘结构
我们来新建这个数据挖掘模型,新简单的步骤,具体内容可参照我之前的博客内容,看几个关键步骤:
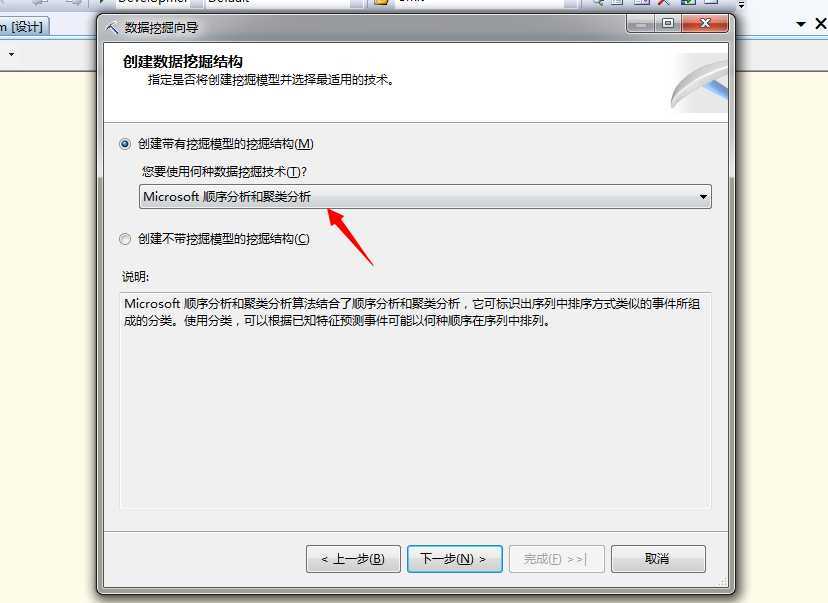
选择该算法,然后单击下一步,选择数据源视图,然后选择好事例表和嵌套表:
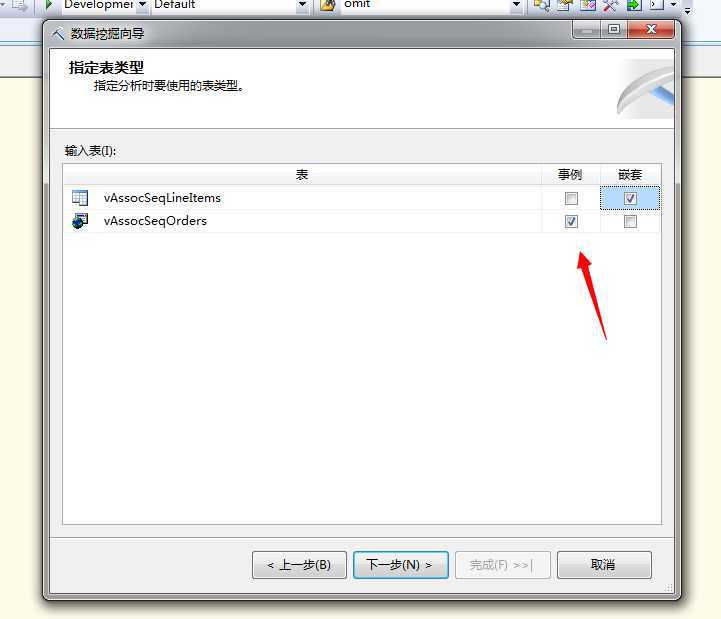
点击下一步,来设置输入输出列:
然后下一步我们起个名字即可:
我们来部署该挖掘模型,然后进行处理,过程简单,不废话介绍。
结果分析
部署完程序之后,我们通过“挖掘模型查看器”进行查看分析,不废话,我们直接看图:
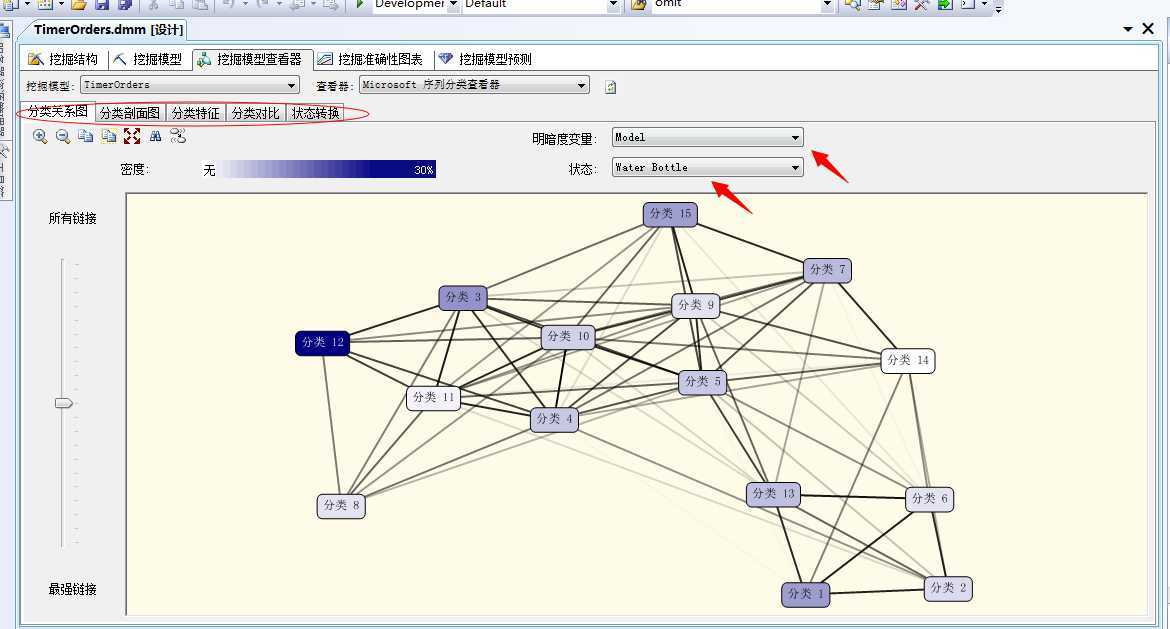
嘿,多么熟悉的面板,如果有童鞋看过我之间的文章,可以看到此算法用的结果展示面板其实和前面的Microsoft聚类分析算法是一样的,只是这里添加了一个新的面板:状态转换,下面我们简要的分析这几个面板,有不清楚的可以参照之前文章,重点的看看这个新添加的面板有啥作用。
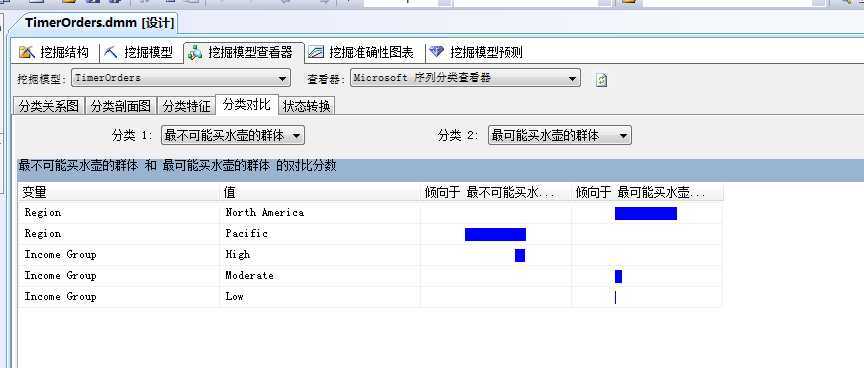
这里我们随便找一个产品来分析,我们就选择上一篇关联规则算法中最出众的水壶(Water Bottle)来看看:
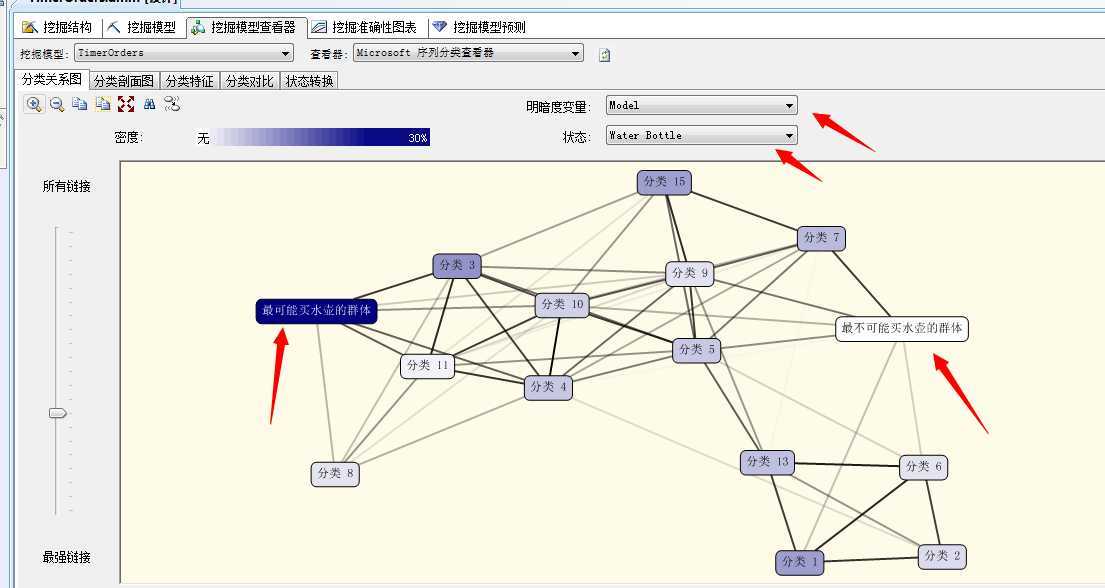
我们重命名了两类群体,颜色最深的最可能买水壶的群体和颜色最浅的最不可能买水壶的群体,我们针推这两个群体进行聚类分析‘,我们来看第二个面板: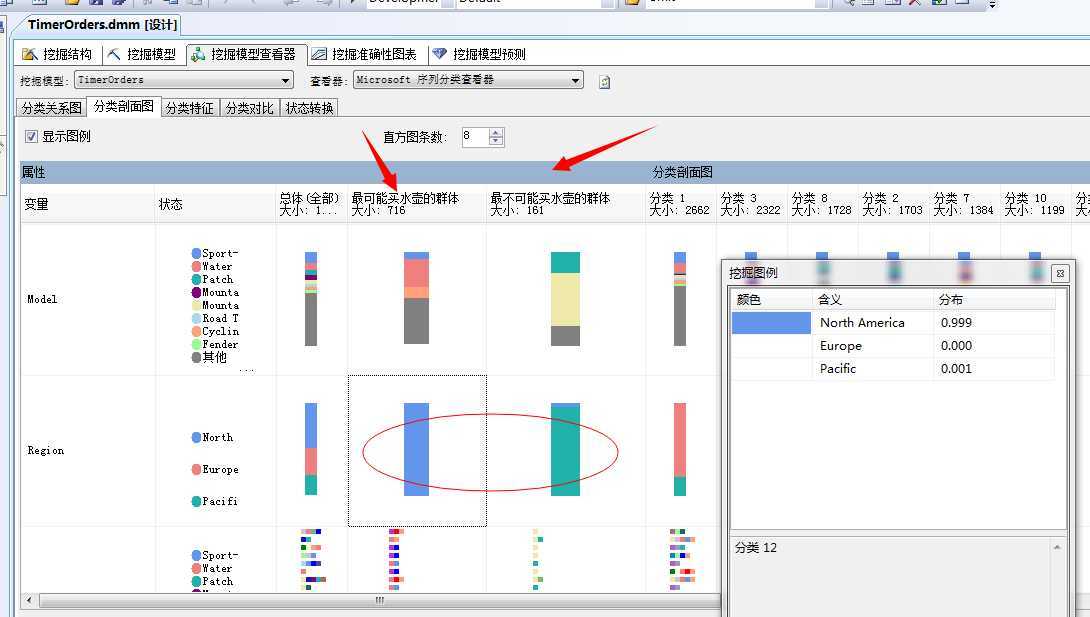
我们可以看到买不买水壶的两种群体和地区有着非常大的关系,比如上图中最想买的人群集中在北美,而在太平洋地区则买的人很少,如果向下拖动的话,还可以看到和收入也有着很大的关系,比如收入高的人群买水壶的人数就少,汗...估计都是买水喝,相反收入低的屌丝阶层买水壶的人就多!嘿嘿...微软的案例数据库给出的数据看样子还挺真实。
接下来我们来看“分类特征”这一面板:
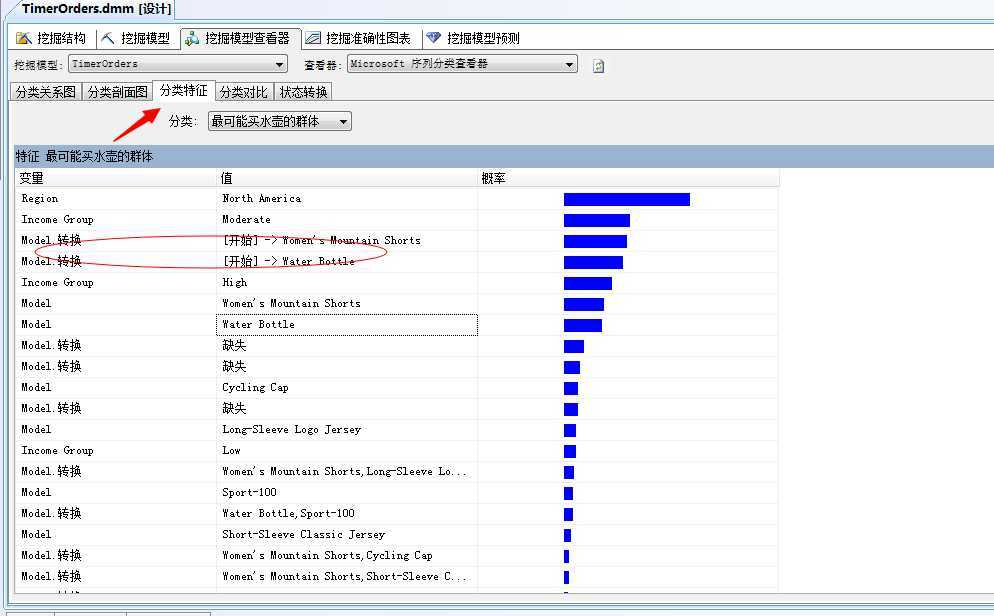
我们选择一个群体,来查看明细数据,上图中我勾选出的数据,展示的就是本章算法的重点,[开始]->Women‘s Mountain Shorts表示的就是一个客户来商店,最想放入购物篮的第一个产品就是:Women‘s Mountain Shorts(妇女的山地短裤?我去...为什么是妇女的!!...妇女最喜欢买短裤?...);[开始]->Water Bottle,也是同样的含义,表示最先放入购物篮的就是水壶这个神器了。当然还有其它几个比较重要的概率属性:都是在北美、收入是有节制的人群。
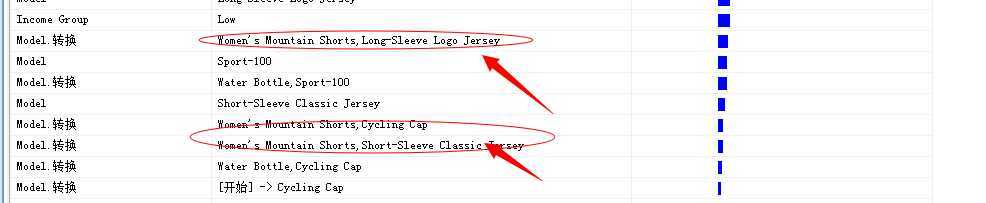
图中给出的商品顺序即是Microsoft 顺序分析和聚类分析算法推测出的顺序产品,也就是说一定按照此顺序发生购买行为的,比如上面的第一个:
Women‘s Mountain Shorts(妇女的山地短裤),然后Long-Sleeve Logo Jesey(长袖?)
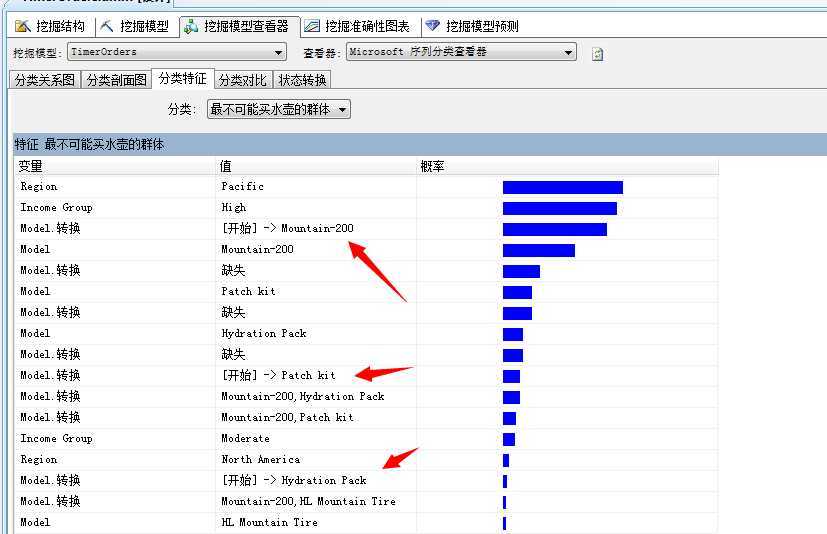
最不可能买自行车的群体...来瞅瞅...太平洋地区、高收入、直接上来就买自行车(Mountain-200)或者Patch kit...
我们直接通过“分类对比”面板进行对比,查看结果:
不介绍,上图介绍的很全面。
下面我们来看最后一个:状态转换面板
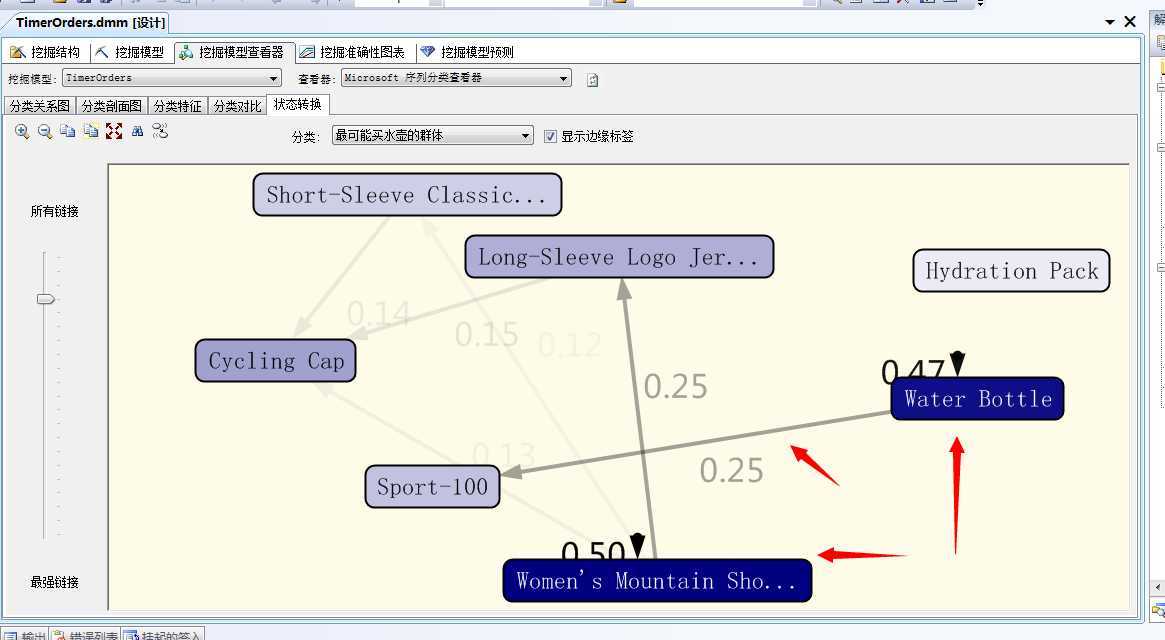
上图给出的就是各个产品间的状态转换问题,首先颜色的深浅告诉了我们这个群体的特征,然后就是产品之间转换的可能性,可以通过拖动左侧的滑动条查看,首先与Water Bottle关联的是Sport-100,也就是说卖完水壶之后,最先买的就是Sport-100;然后是卖完Women’s Mountain Shorts,最先买的是Long-Sleeve Logo...
有兴趣的可以分析其它群体的特征和购买顺序。
推测结果导出
我们到此步骤直接将该模型的分析结果进行预测,进入到“挖掘模型预测”面板:
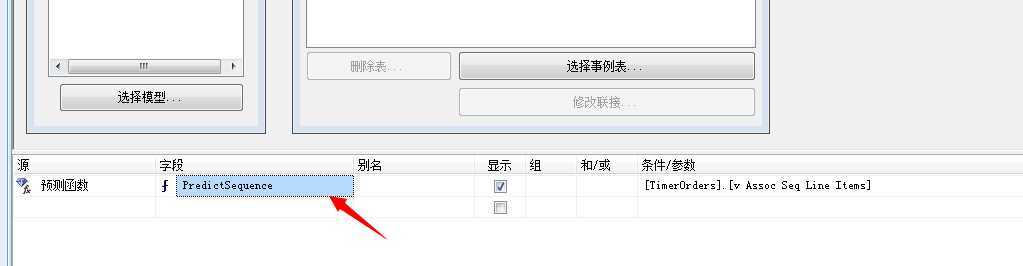
我们来设置挖掘函数:源选择:预测函数、字段选择:PredictSequence、条件/参数:直接将v Assoc Seq Line Items拖入,点击运行查看结果:
我们来查看结果:
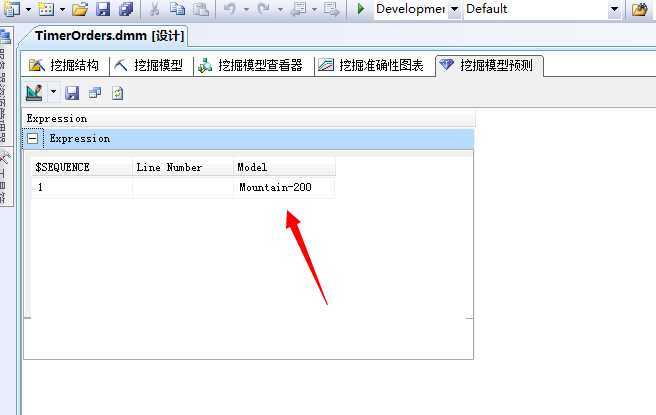
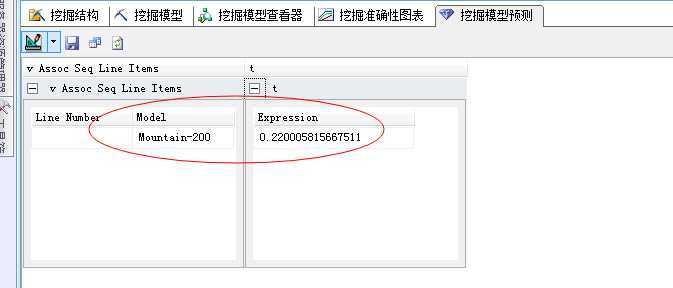
可以看到所有结果中,最先放入购物篮的产品为Mountain-200这款山地自行车。如果默认不加任何选择条件的话,此结果输出项只有一个,也就是预测的第一个事例,当然很多的需求并非如此简单,比如:有时候我们需要根据地区去区分不同的购买序列问题,因为上面我们从“分类特征”面板中已经分析出来,产品件的顺序和地区有着很大的区别;
我们选择“单独查询输入”,点击“Region”,选择Europe地区:
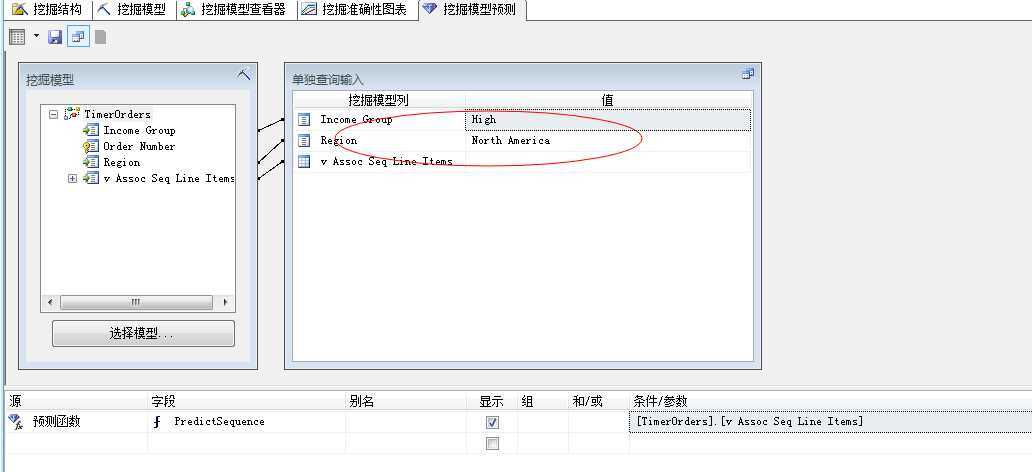
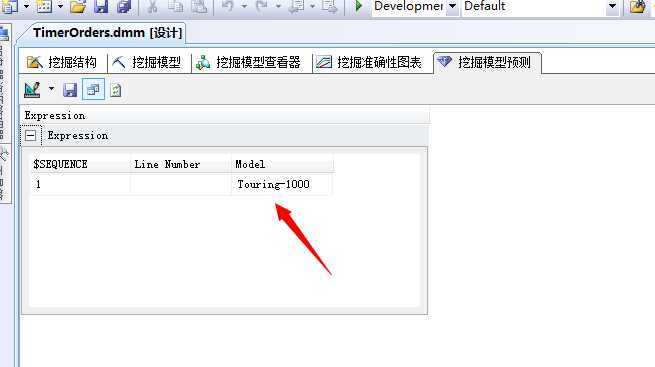
我们可以看到这个群体的第一个最有可能购买的产品已经变了,改成了:Touring-1000,当然我们直接写DMX语句就可以:
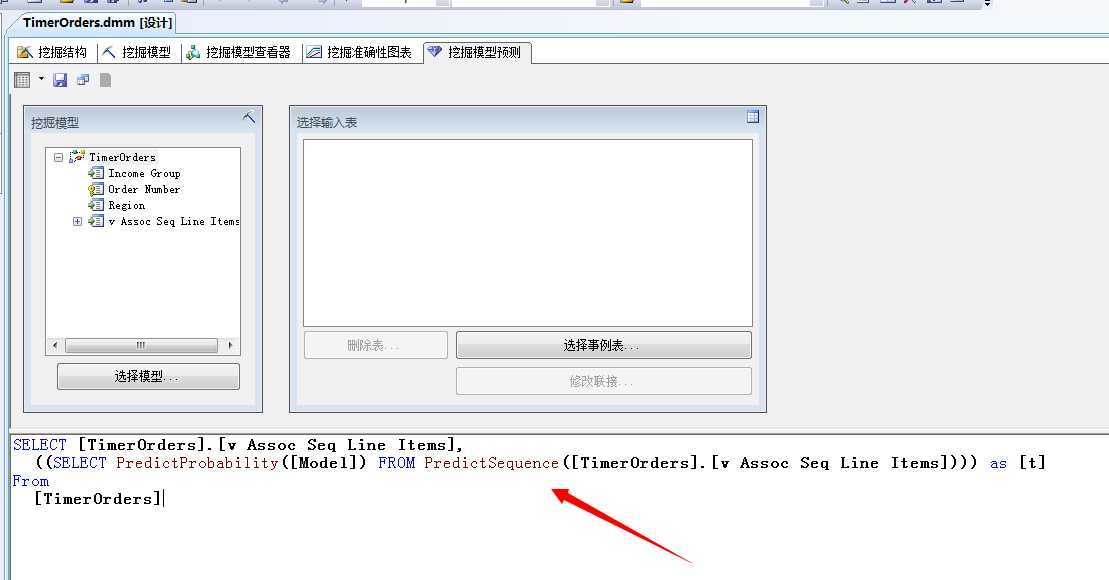
这样实现方式更灵活,我们可以查询出产品和概率项:
其实,对于SSAS所产生的结果集,有其专用的DMX语言进行灵活的查询和操作,这里我们就不多解释了,有时间专门来解析这块。
当然,此块我们也可以根据已有的客户列表中,进行挖掘,推测出该用户最大可能性的选择的下一款产品是神马?我们选择现有的事例表和嵌套表,然后设计语句:
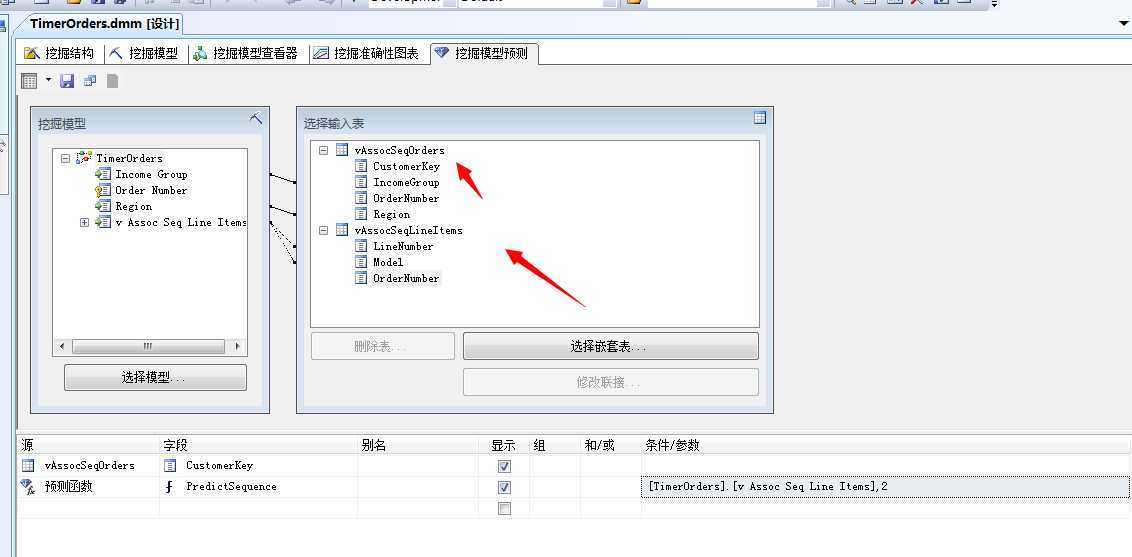
我们来查看结果:
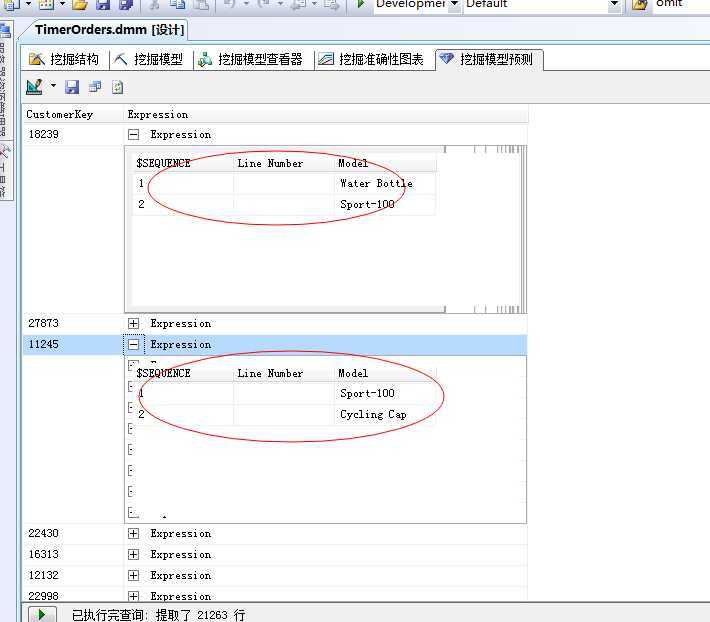
看上图,根据本篇的Microsoft 顺序分析和聚类分析算法,已经将不同的用户可能按照顺序购买的产品有哪些,这里面分析的结果是严格按照顺序进行的,我们可以看到上面有一个顾客编号的为18239的,他最可能先买Water Bottle,然后再买Sport-100....
我们看看这个顾客已经发生的购买行为:
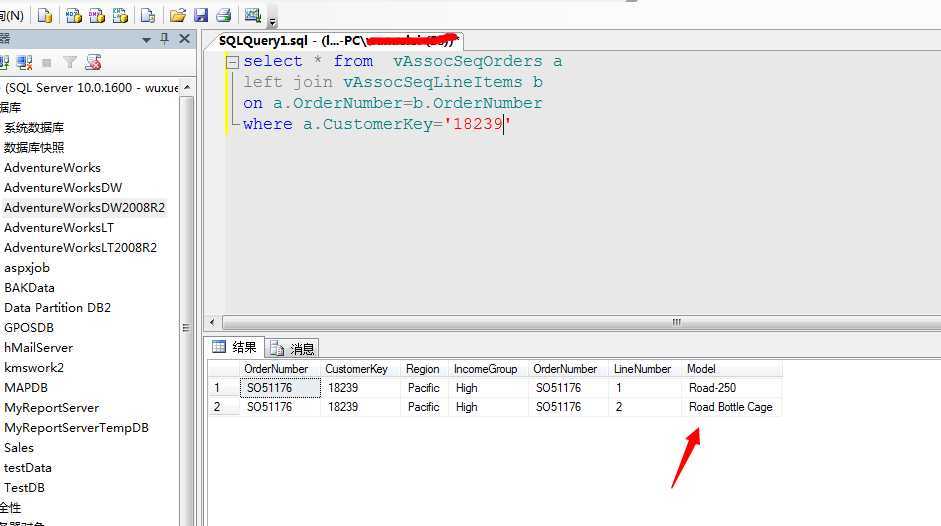
看在S051176这个订单中,这货已经买了俩产品...下一步他将买啥?我们上面已经推测出来了:Water Bottle,然后再买Sport-100....
下一步我们的工作就是保存到数据库,一段简单的代码经这部分群体的意向购买行为给挖掘出来,然后你就拿着去找BOSS可以了....
此部分过程很简单,不明白的可以参照我之间的博客。
结语
本篇文章到此结束了...关于“现有鸡先有蛋的问题”我们就研究到此,后续文章继续分析其它问题。
文章的最后我们给出前几篇算法的文章连接:
如果您看了本篇博客,觉得对您有所收获,请不要吝啬您的“推荐”。
大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 顺序分析和聚类分析算法)
标签:style blog http io color ar os sp strong
原文地址:http://www.cnblogs.com/lonelyxmas/p/4069238.html