标签:特征 坐标 set 缺点 height col ica stage multi
3D点云做detection的一篇milestone paper。经典的two-stage方法(region proposal-based method)。思路来自于经典的faster rcnn。
整个模型如下图
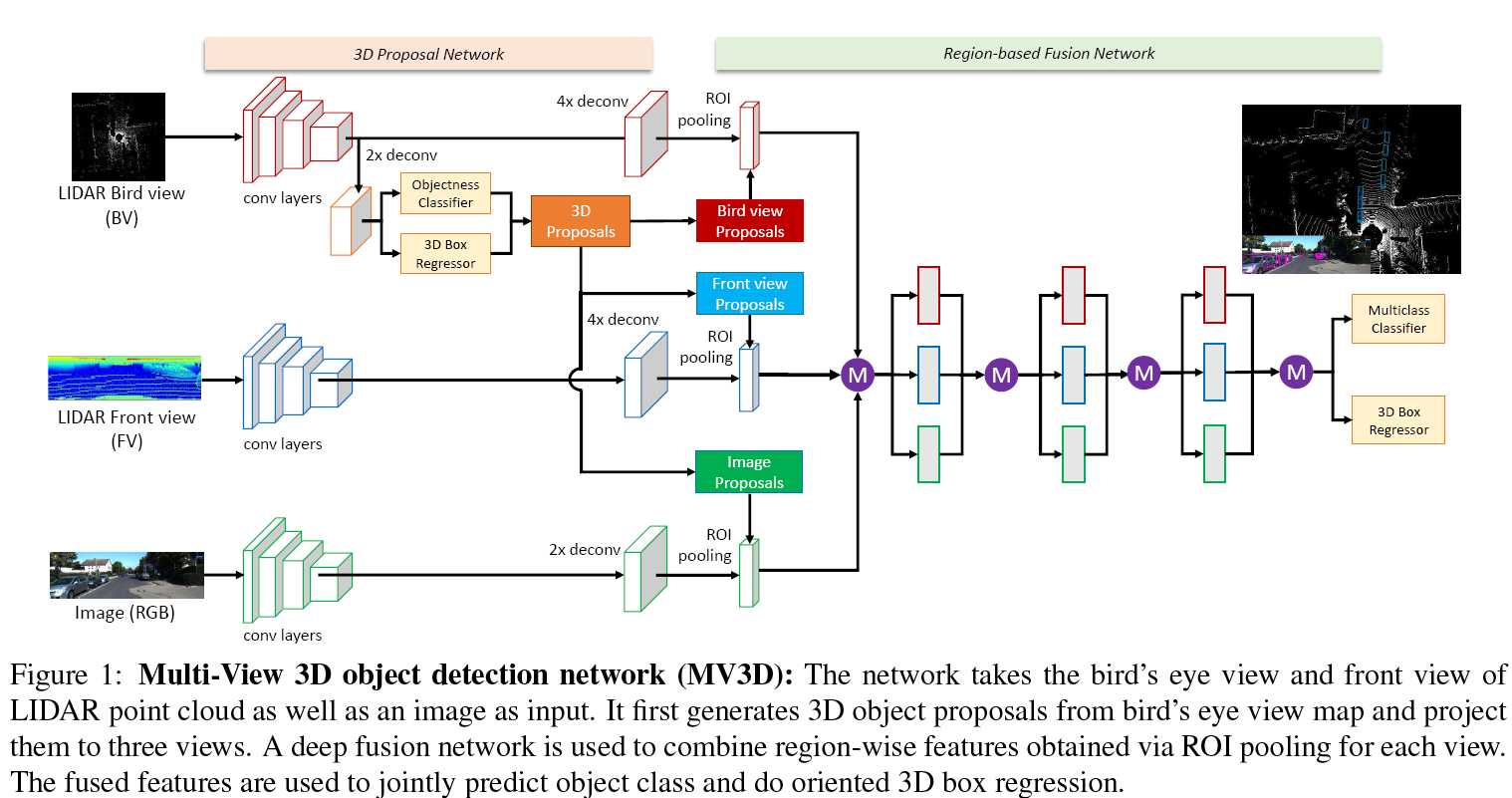
图一. 整体模型
这篇文章可以归纳为是multiview-based method,multi-view的方法是指将三维点云按照不同view进行映射,得到很多的2D图像,因为2D图像的CNN很强大,这样就可以用2D CNN处理。最后将不同view得到的feature进行融合(fusion),再进行后续的不同task,如classification、detection、segmentation等等。这种方法优缺点都很明显,优点是CNN处理2D图像很强大也更成熟,缺点是有限的views会造成信息的损失。
这篇文章映射的角度包括Bird‘s Eye View(鸟瞰图)和Front View(前视图)。
对整个点云按照鸟瞰的视角,按照0.1米的分辨率进行网格化(grid)采样。每个网格(cell)在高度这一特征(height feature)上取该网格里所有点云的最大值。特别地,作者并不是仅仅只取一个鸟瞰图,而是对整个点云按照不同高度,均匀切片成M片(M slices)。每个切片产生一张height map,里面记录了每个切片里面每个cell的最大高度。采样的每个网格(cell)的intensity feature就是max height的那个点的intensity。点云的density feature指每个cell的点数量(记为$N$),按照$min(1.0, \frac{log(N+1}{log(64)})$进行归一化。因此共有M个height map,1个density feature和1个intensity feature,共$N+2$维的特征。
前视图作为鸟瞰图的补充信息。但是由于点云数据稀疏程度是不均匀的,很多地方非常稀疏,因此作者并不是将点云投射到图像平面(image plane),而是投射到圆柱平面(cylinder plane)来产生密集的前视图。
极坐标投影转换关系如下图,得到前视图极坐标$P_{f_c}=(r,c)$
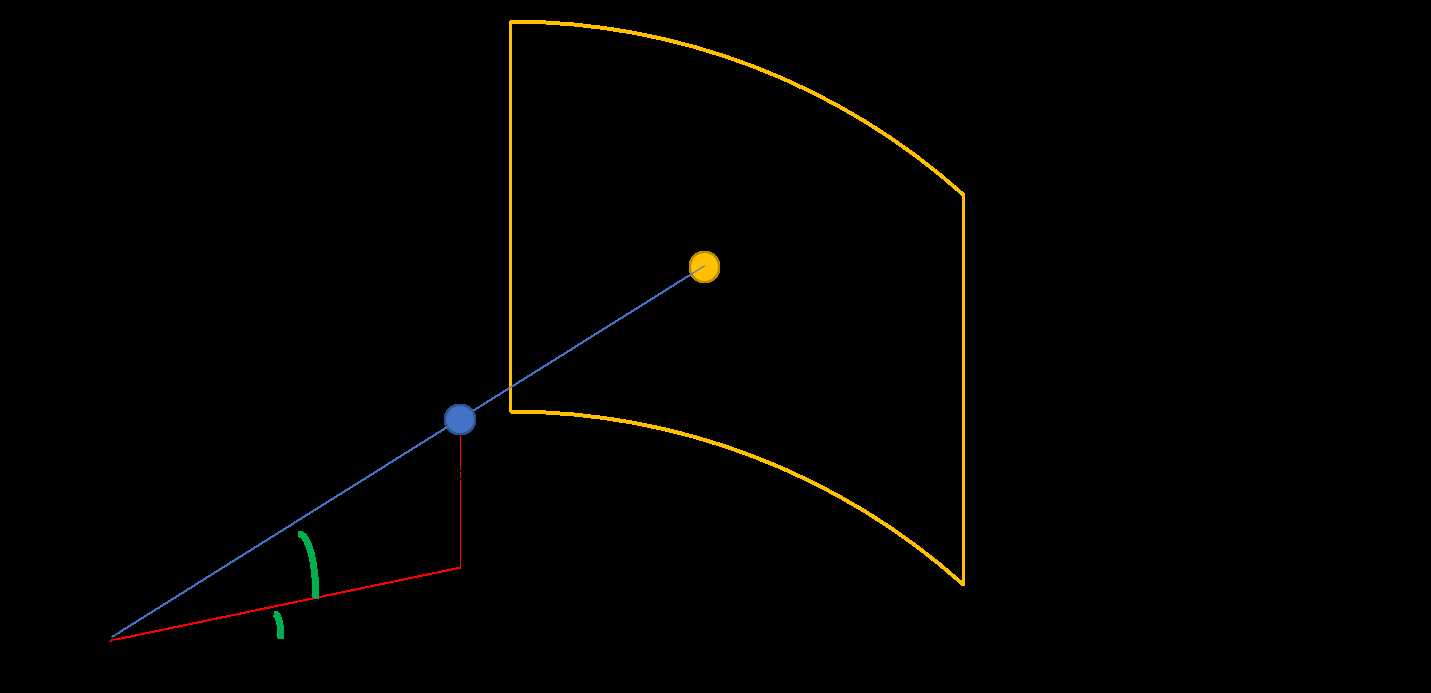
图二. 前视图圆柱投影
首先用一个网络生成region proposals.
整个模型是针对KITTI数据集,所以输入包括①BEV(鸟瞰图)、②RGB image和③front view of LIDAR point cloud。
[cvpr17]Multi-View 3D Object Detection Network for Autonomous Driving
标签:特征 坐标 set 缺点 height col ica stage multi
原文地址:https://www.cnblogs.com/xiaoaoran/p/12213024.html