标签:日志管理 时间 显示 也有 执行 日志信息 问题: image 导致
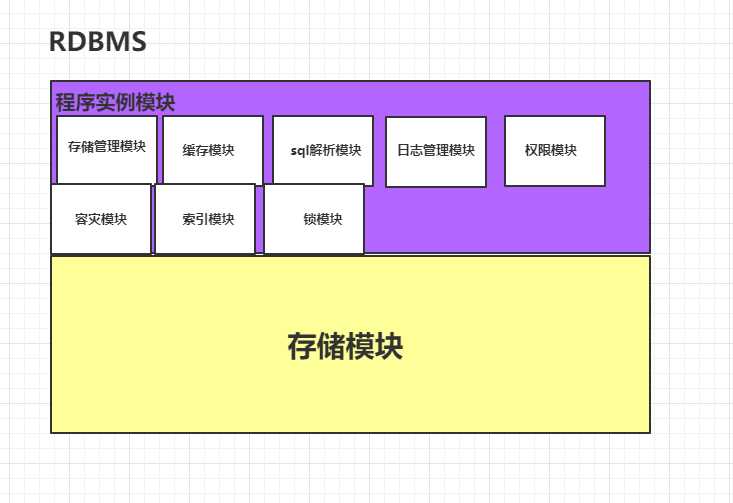
答:首先,不管是设计一个系统还是一个数据库还是搭建一个项目我们都要进行模块的划分,因此,当我们要设计一个数据库的时候也要对其进行模块的划分,设计关系型数据库主要分为两大模块,一个是存储模块,类似于一个文件系统,将数据持久化的存储到磁盘中,另一个是程序实例模块,用于组织、管理和操作数据,程序实例模块中又被细划分为很多的模块,其中包含,存储管理模块、缓存模块、sql解析模块、权限模块、容灾模块、索引模块、锁模块、日志管理模块。缓存模块用于将数据的逻辑结构转为物理结构,缓存模块用于优化执行效率,sql解析模块用于sql语句的解析,权限模块用于对多用户进行管理,索引模块和锁模块用于解决程序的高并发问题,容灾模块类似异常机制,解决异常问题。日志管理模块对数据库的操作进行记录。
答:首先建立索引的目的是为了实现快速查找功能,我们一般的查询数据都是进行全表扫描操作,将表的数据全部或分批次的加载进内存,而在数据库中数据的存储单位为块或页,该结构由多条数据工程,当我们要查询数据时会轮询内存中的块或页,直至查询到对应的数据,因此也造成了全表查询速度慢的问题,但是如果表中的数据很少使用全表查询的速度还是很快的。索引主要借鉴了咱们字典索引的特点,将一些关键信息组织起来,根据关键信息找到对应的数据。
答:主键、唯一键、其它键
答:索引的数据结构有二叉树结构,B-Tree结构,B+-Tree结构,hash结构,BitMap位图结构,当二叉树结构的索引深度较深,会导致查询时IO频繁,B-Tree中一个节点可以有多个关键字,解决了树的深度的问题,性能优于二叉树结构,B+-Tree对B-Tree进行了改进,内部节点只用于存储索引信息 ,叶子节点用于存储数据,且每个叶子节点都有一个链指针指向下一个叶子节点,这样解决了对磁盘读写的性能问题,同时对数据的查询效果更稳定,更有利于全表扫描。当然与B+Tree相比hash索引和BitMap索引的性能也有很多的弊端,如hash索引有很多hash值都相等时就要不可避免的进行全表扫描,位图索引适用于一个字段有几个具体值得统计查询,因此B+-Tree是最佳的索引结构。
1.密集索引文件的每个搜索码值对应一个索引值(每个叶子节点不仅包含主键信息,还包含其他列的信息)
2.只为搜索码的某些项建立索引值(叶子节点只存储主键信息以及改行的地址信息,再根据主键信息或地址信息进一步查询数据)
InnoDB/MyIdAm
(有且只有一个密集索引)
1.若定义了主键,将主键设置为密集索引
2.若没有定义主键,将第一个唯一非空的字段作为密集索引
3.若以上的两个条件都不满足,InnoDB内部会自动生成一个隐藏的主键作为密集索引
特点:数据和索引存在一起。
(不管是主键索引还是唯一键索引或其他键索引都是稀疏索引)
特点:索引和数据分开存储。
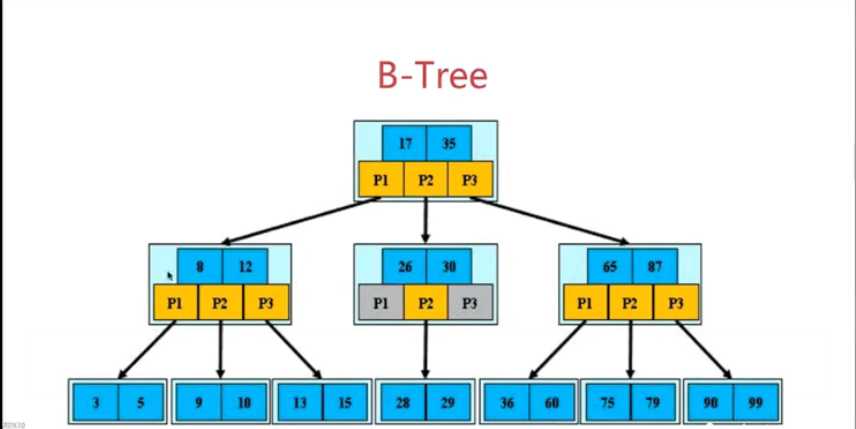
1.根节点至少包含两个孩子
2.每个节点至多包含m个孩子,m是树的阶数(m>=2)
3.除根节点和叶子节点外,每个节点至少包含ceil(m/2)个孩子,ceil取最大值
4.所有叶子节点都位于同一层
前4条规定了数的深度
5.每个终端节点包含n个关键字信息,那么,条件如下:
? 1).节点的关键字按顺序排序
? 2).关键字的个数 ceil(m/2) <= n <= m-1 (m是树的阶数)
? 3).非叶子节点的指针p[1]指向小于关键字小于k[1]的子树,p[m]指向大于关键字 k[m-1]的关键字,p[i]指向(k[i-1] k[i] )的子树
? 即节点左子树的所有关键字小于它的第一个关键字,节点的右子树的关键字都 于大于节点的最后一个关键字,如:p1指向的子树的关键字都小于8,p3指向的 子树的关键字都大于12。
第5条规定了关键数的数量和大小
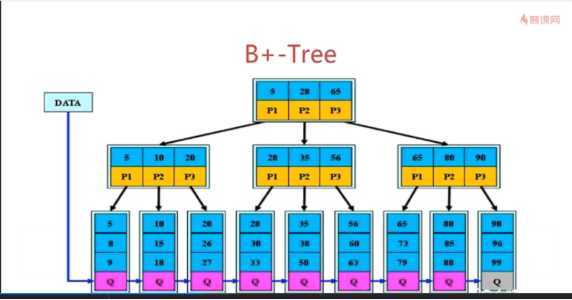
--大体与B-Tree类似
不同点:
1.节点关键的的个数和指针的个数相同
2.p[i]指向的子树关键字的范围k[i] k[i]+1, 如p[2]指向的关键数 的值介于[k[2] k[3]] 即[10, 20]之间, p[2]子树的值{10, 15, 18}
3.非叶子节点用于存储索引,叶子节点用于存储数据,这意味着所有的查询都在叶子节点中终结。
4.所有的叶子节点均有一个链指针指向下一个节点,便于做统计。
原因:
B+-Tree的非叶子节点只存储索引,叶子节点用于存储数据
当要查询一条数据时,都要通过一条从根节点到叶子节点的路径,查询关键字经过的长度都相同,因此查询效果更加稳定
B+-Tree的数据都存储在叶子节点中,所以全表扫描时我们只需遍历叶子节点,同时每个叶子节点都有一条链指针指向下一个节点,这样有利于进行范围查找。
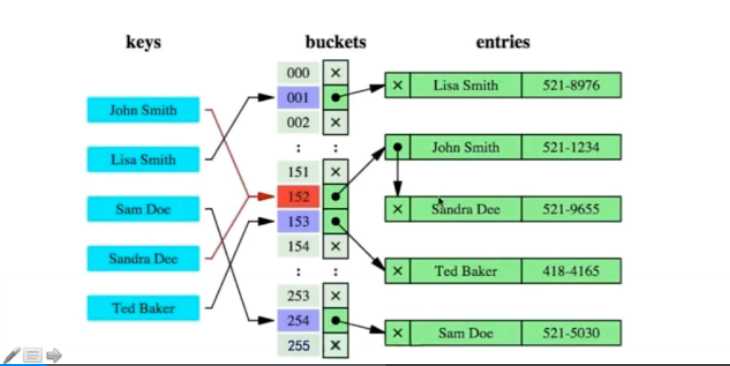
1.只能用于in == 的查询,不适用于范围查询
2.不能避免使用排序查询
3.不能使用组合索引
4.不能避免表扫描
5.遇到大量的hash值相等的情况,性能不一定比B-Tree好
当字段为确定的几个值,对其进行统计时,可以使用位图索引。
能支持位图索引的数据库比较少,一般典型的是oracle
位图索引的弊端:锁的力度很大,尝试新增或删除一条数据时都会将其他行锁住,不适合高并发系统。
1.使用慢查询日志定位慢sql
show variables like "quer" : 显示慢日志信息
慢日志信息的3个重要的字段
? long_quer_time : 定义超过多长时间的sql查询为慢查询
? slow_query _log_file: 慢查询语句信息的输出位置
? slow_query_log : 慢查询日志的开启状态
2.使用explains来分析sql语句
explains 慢查询定位到的sql语句
根据输出结果字段来分析引起慢查询的原因,type: 查询类型,index/all代表全包扫描, extra:Using FileSort代表使用外部排序而不是使用索引排序, Using temporay代表使用临时空间。
3.修改sql语句尽量让sql走索引。
答:使用show variables like %quer%根据慢查询日志定位慢sql,使用explains,根据对应的信息分析导致慢sql的原因,根据原因进行sql修改或尽量让查询走sql.
标签:日志管理 时间 显示 也有 执行 日志信息 问题: image 导致
原文地址:https://www.cnblogs.com/Auge/p/12218809.html