标签:开始 节点 设置 最大 上线 细粒度 就是 精准 依赖
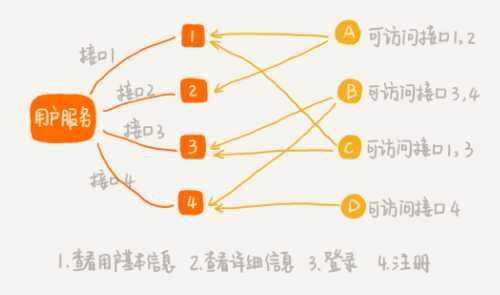
需要实现接口鉴权功能
事先将应用对接口的访问权限规则设置好。
当某个应用访问其中一个接口的时候,可以拿应用的请求 URL,在规则中进行匹配。
如果匹配成功,就说明允许访问;
如果没有可以匹配的规则,说明这个应用没有这个接口的访问权限,就拒绝服务。


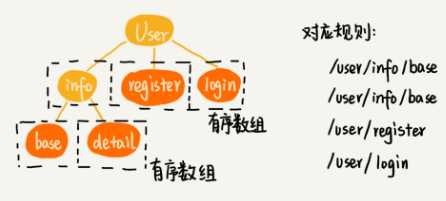
如何实现模糊匹配规则?

可以借助正则表达式那个例子的解决思路,来解决这个问题。采用回溯算法,拿请求 URL 跟每条规则逐一进行模糊匹配。
回溯算法复杂度是非常高,如何优化?
把不包含通配符的规则和包含通配符的规则分开处理(分治思想):
把不包含通配符的规则,组织成有序数组或者 Trie 树进行精确或前缀匹配(具体组织成什么结构,视具体的需求而定,是精确匹配,就组织成有序数组,是前缀匹配,就组织成 Trie 树)。
剩下的是少数包含通配符的规则,只要把它们简单存储在一个数组中就可以了。尽管匹配起来会比较慢,但是毕竟这种规则比较少,所以这种方法也是可以接受的。
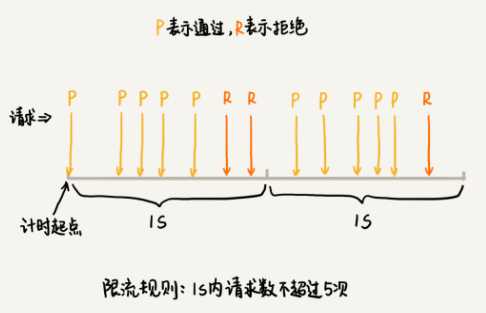
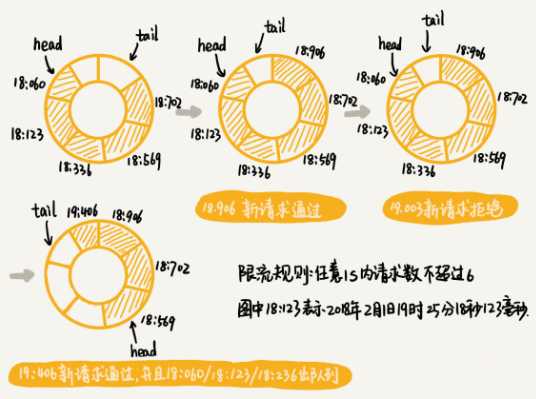
只能在选定的时间粒度上限流,对选定时间粒度内的更加细粒度的访问频率不做限制。
数据结构与算法简记--剖析微服务接口鉴权限流背后的数据结构和算法
标签:开始 节点 设置 最大 上线 细粒度 就是 精准 依赖
原文地址:https://www.cnblogs.com/wod-Y/p/12219106.html