标签:结构图 ram get 第一步 net 原理 base mem randn
一.RNN简介
RNN是一种特殊的神经网络结构,考虑前一时刻的输入,且赋予了网络对前面的内容的一种‘记忆‘功能.
时间先后顺序的问题都可以使用RNN来解决,比如:音乐,翻译,造句,语音识别,视频图像预测,语言处理等等,后来经过变种甚至可以达到CNN的作用
具体例子1 Car which.............,() .........。使用RNN可以预测括号里面的内容应该为 is/was.
2 学习莎士比亚写的诗词,然后进行模仿
3 你想为朋友的生日创作一段爵士乐,然而,你不会任何乐器、乐理,幸运的是,你了解深度学习并将使用LSTM网络来解决这个问题
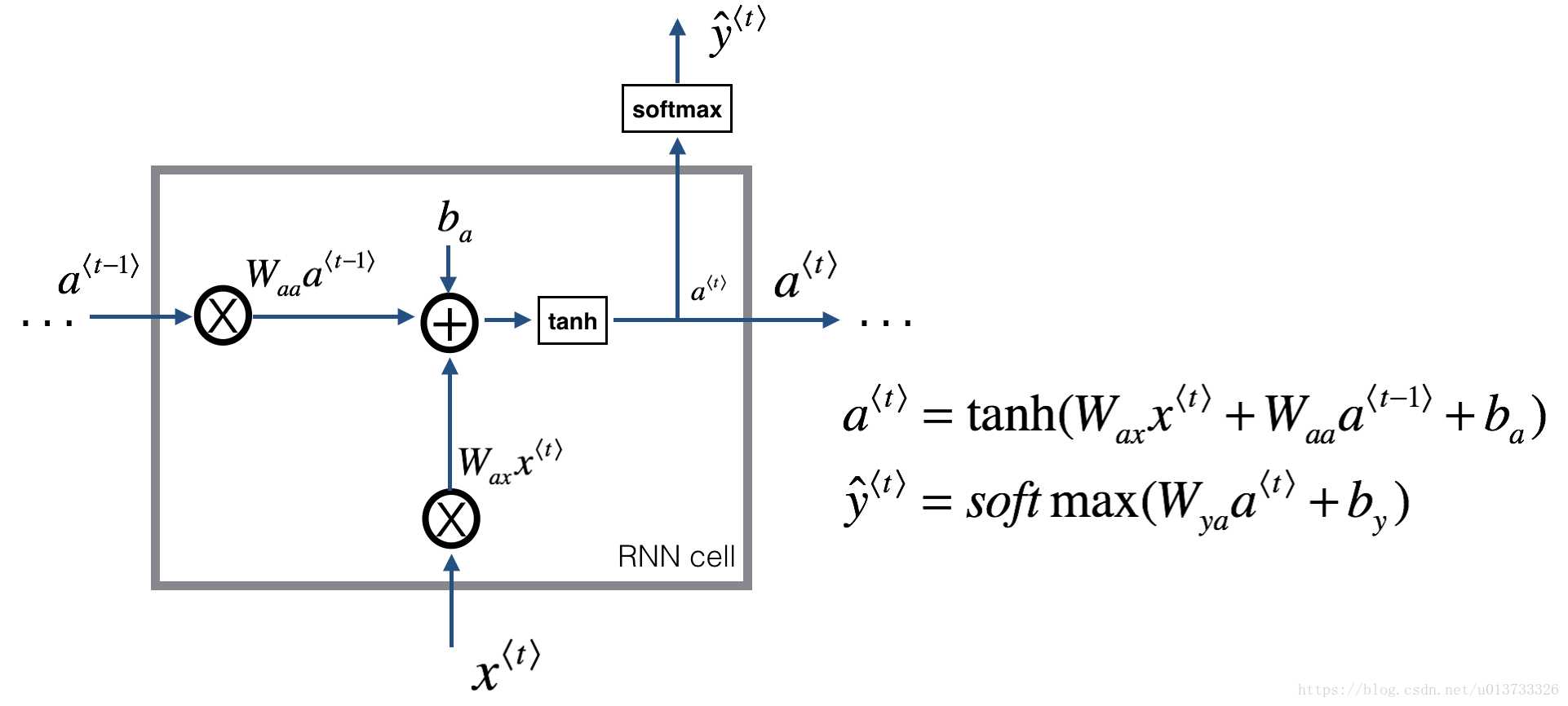
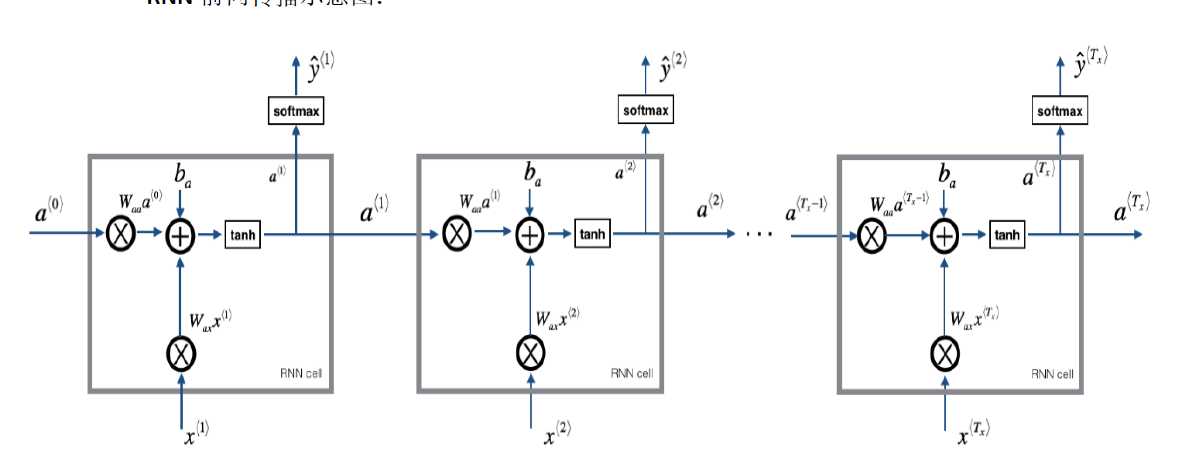
上一时间t-1隐藏状态与本时刻t的输入xt 乘以权重矩阵Wa,加上一个偏置ba,再使用tanh激活函数得到本时间t得隐藏状态at。
使用本时间的隐藏状态at预测出yt
答:我们称a^t为隐藏状态,由图可知,它是根据X^t计算得到的,也就是说它保留了上一个单元的输入信息,这就是它记忆的原理
答:sigmod导数复杂,使用sigmod函数容易出现梯度消失,(tanh也会有此问题,lstm网络解决此问题)
 ,
,
 ,
, 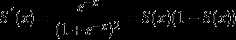
pass
t时刻的损失值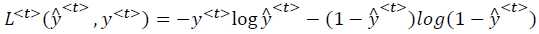
总损失值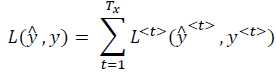
RNN基础版,存在着一些问题, 其中较为严重的是容易出现梯度消失或者梯度爆炸的问题. 注意: 这里的梯度消失主要指由于时间过长而造成记忆值较小的现象,例如Car 和 后面的 距离太远了,网络无法记住
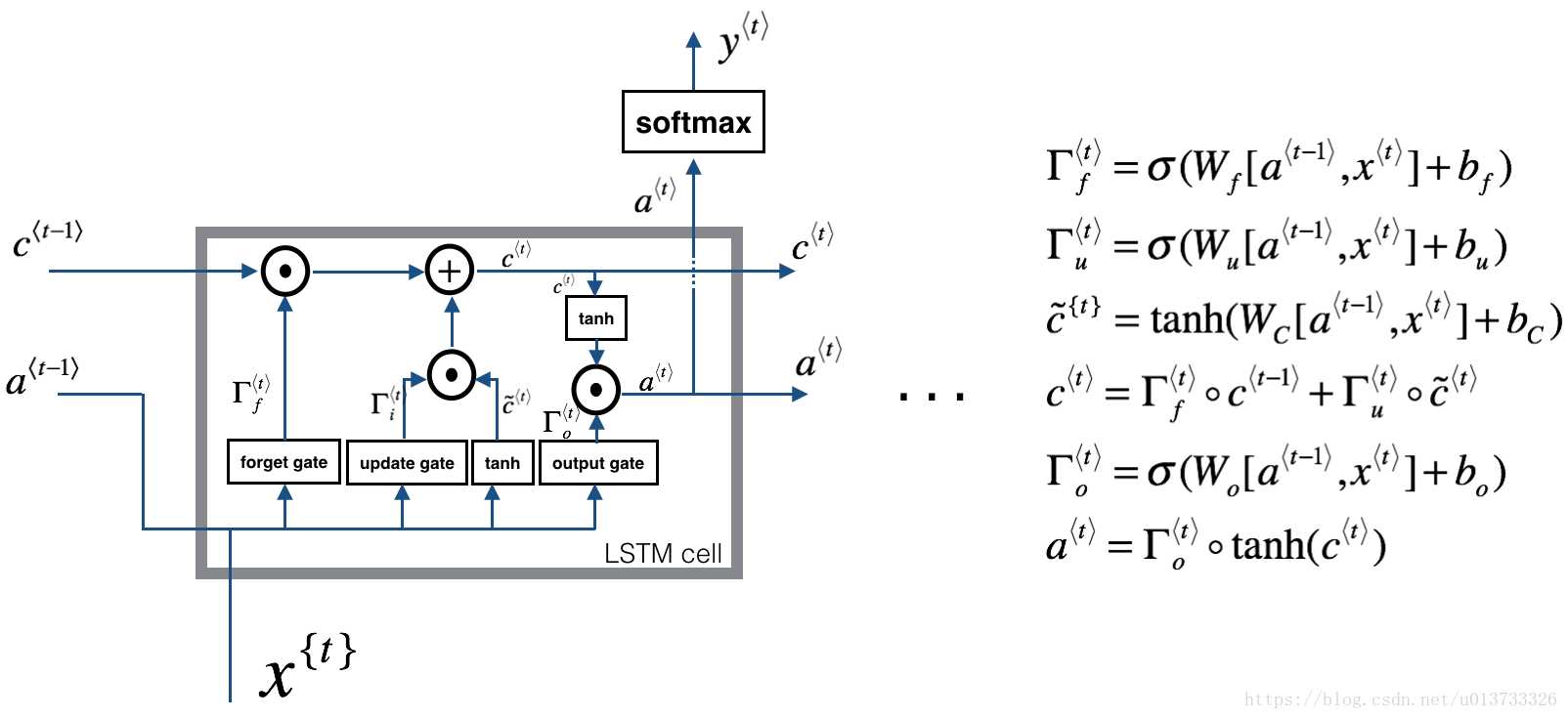
我们称Ct为细胞状态
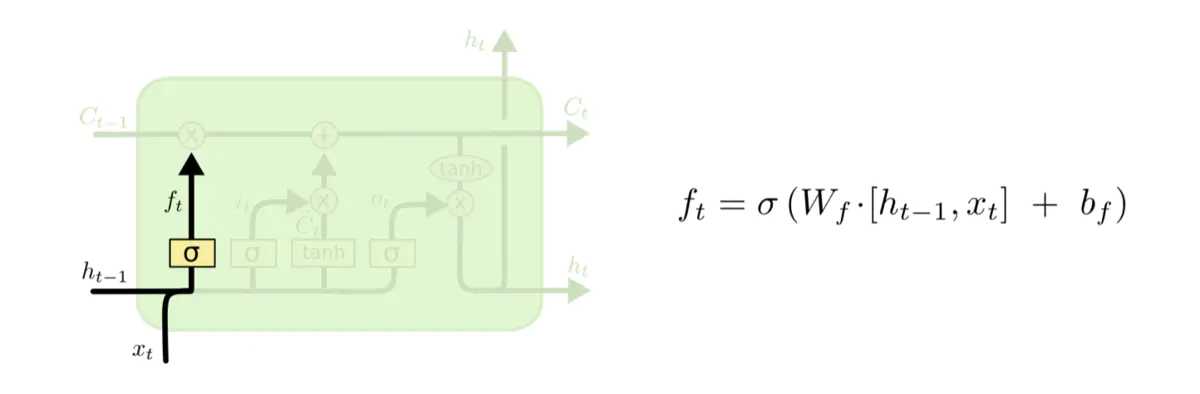
忘记门 Γf?t??=σ(Wf?[a?t−1?,x?t?]+bf?) 使用 sigmod激活函数,向量里面的0-1值表示细胞状态中的哪些信息保留或丢弃多少。0表示不保留,1表示都保留
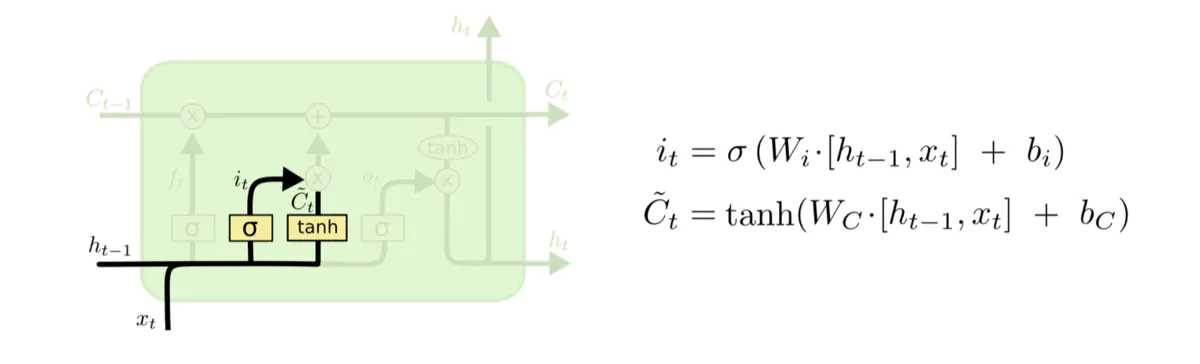
输入门 Γu?t?=it?=σ(Wu?[a?t−1?,x?t?]+bu?),使用sigmod激活函数,决定更新哪些信息