标签:代码 函数 大小 eject 工作 one 通过 return 成员
管理一组线程集合,方便线程的复用,免了频繁创建和销毁线程所带来的开销,相关类的继承关系如下:
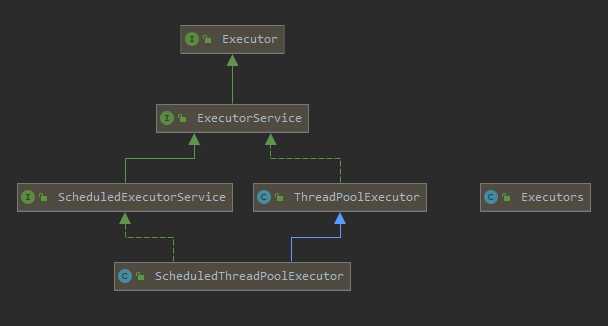
Executor 仅声明了一个方法execute,代表要执行某个任务。
ExecutorService 接口在其父类接口基础上,声明了包含但不限于shutdown、submit、invokeAll、invokeAny 等管理线程池的方法。
ScheduledExecutorService 接口,则是声明了一些和定时任务相关的方法,比如 schedule和scheduleAtFixedRate。
ThreadPoolExecutor是线程池的核心实现
Executors 提供newFixedThreadPool、newSingleThreadExecutor和newCachedThreadPool等静态方法创建线程池,返回的均是 ThreadPoolExecutor 类型
ThreadPoolExecutor是线程池的核心实现,构造方法如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize 核心线程数。当遇到任务时并且线程数小于该值时,线程池会优先创建新线程来执行新任务
maximumPoolSize 线程池所能维护的最大线程数
keepAliveTime 空闲线程的存活时间
workQueue 任务队列,用于缓存未执行的任务
threadFactory 线程工厂。可通过工厂为新建的线程设置更有意义的名字
handler 拒绝策略。当线程池和任务队列均处于饱和状态时,使用拒绝策略处理新任务。默认是 AbortPolicy,即直接抛出异常
当提交一个任务时:
总结以上的规则就是:
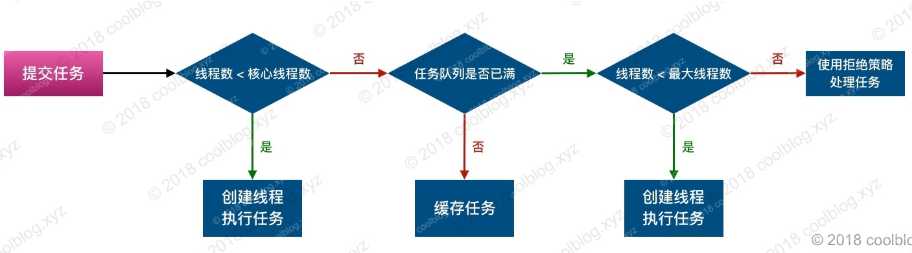
非核心线程空闲时间超过指定的keepAliveTime就会被回收;核心线程默认不回收,可以通过配置修改。
任务队列BlockingQueue接口的实现,常见的有如下几种:
| 实现类 | 类型 | 说明 |
|---|---|---|
| SynchronousQueue | 同步队列 | 该队列不存储元素,每个插入操作必须等待另一个线程调用移除操作,否则插入操作会一直阻塞 |
| ArrayBlockingQueue | 有界队列 | 基于数组的阻塞队列,按照 FIFO 原则对元素进行排序 |
| LinkedBlockingQueue | 无界队列 | 基于链表的阻塞队列,按照 FIFO 原则对元素进行排序 |
| PriorityBlockingQueue | 优先级队列 | 具有优先级的阻塞队列 |
拒绝策略
| 实现类 | 说明 |
|---|---|
| AbortPolicy(默认) | 丢弃新任务,并抛出 RejectedExecutionException |
| DiscardPolicy | 不做任何操作,直接丢弃新任务 |
| DiscardOldestPolicy | 丢弃队列队首的元素,并执行新任务 |
| CallerRunsPolicy | 由调用线程执行新任务 |
提交任务的两个方法:
void execute(Runnable command)
<T> Future<T> submit(Runnable task, T result)
submit内将Runnable包装成一个RunnableFuture,然后通过execute提交给线程池。所以核心的任务处理方法在ThreadPoolExecutor#execute中
在线程池中,线程的复用是线程池的关键所在。这就要求线程在执行完一个任务后,不能立即退出。
对应到具体实现就是,工作线程在执行完一个任务后,会再次到任务队列获取新的任务。如果任务队列中没有任务,且 keepAliveTime 也未被设置,工作线程则会被一致阻塞下去。通过这种方式即可实现线程复用。
不管是线程等待、超时移除非核心线程,都是通过任务队列来实现了,这也就意味着任务队列必须是BlockingQueue类型,具备一直阻塞和超时阻塞机制。
通过execute提交任务后,会触发addWorker方法:
如上所述,这个这个函数已经运行在一个独立的线程中了。这里循环调用getTask方法来从队列中获取要执行的任务,简化后的代码如下:
try{
while((task = getTask()) != null){
task.run();
}
} finally{
processWorkerExit();
}
当这个循环结束时,意味当前线程要结束了(后续会提到为什么)。
以上循环结束有两种情况:
这个方法会清理当前worker,同时做一些数据统计之类的收尾工作。
如果是因为异常而终止的,则新增一个worker(这里体现出线程池遇到任务内的异常时,就会结束当前线程,换一个先的线程来执行剩余任务)。
此时当前线程已经结束,新增的worker运行在新的线程中,如果不是因为异常终止的,那肯定是因为有非核心线程,并且超时等待任务没等待到。所以这个函数中不管是哪一种情况,都要先移除一个worker。
关键的线程休眠、超时等待都在这个函数中,简化后的核心代码如下:
// 判断是否需要超时,超时如果获取不到任务的话,就会返回null,当前线程就会结束,线程池会移除当前这个worker,即以上的processWorkerExit逻辑
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 如果不需要超时,则调用take方法,会一直阻塞直到任务队列中有任务,核心线程就会通过这个方法一直休眠
// 如果需要超时,则等待特定keepAliveTime之后还没有任务就返回null,这里体现出超时移除非核心线程的特点
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
Worker对象本身是没有被标记为是否是核心线程,核心线程仅仅是一个数目上的概念,实际的线程对象并不是固定不变的,如出现了异常,就会换一个新的线程来执行任务。
所以一个线程是否是核心线程,就看当前运行时的worker数量,即线程的总数是否小于核心池大小,是的话,则当前线程就是核心线程,否则就是非核心线程。
线程池内使用AtomicInteger ctl来记录worker的数量
标签:代码 函数 大小 eject 工作 one 通过 return 成员
原文地址:https://www.cnblogs.com/hellohello/p/12228362.html