标签:修改器 arrays oca ram 覆盖 eval block list 环境
以变量值的读写为例,向读者介绍基于这种理念的语言处理器性能优化方式。
假如函数包含局部变量x与y,程序可以事先将x设为数组的第0个元素,将y设为第1个元素,以此类推。这样一来,语言处理器引用变量时就无需计算哈希值。也就是说,这是一个通过编号,而非名称来查找变量值的环境
为了实现这种设计,语言处理器需要在函数定义完成后遍历对应的抽象语法树节点,获取该节点使用的所有函数参数与局部变量。遍历之后程序将得到函数中用到的参数与局部变量的数量,于是确定了用于保存这些变量的数组的长度
之后,语言处理器在实际调用函数,对变量的值进行读写操作时,将会直接引用数组中的元素。变量引用无需再像之前那样通过在哈希表中查找变量名的方式实现。
确定变量的值在数组中的保存位置之后,这些信息将被记录于抽象语法树节点对象的字段中。例如,程序中出现的变量名在抽象语法树中以Name对象表示。这一Name对象将事先在字段中保存数组元素的下标,这样语言处理器在需要引用该变量时,就能知道应该引用数组中的哪一个元素。Name对象的eval方法将通过该字段来引用数组元素,获得变量的值。
不必在程序执行时通过变量名来查找变量。
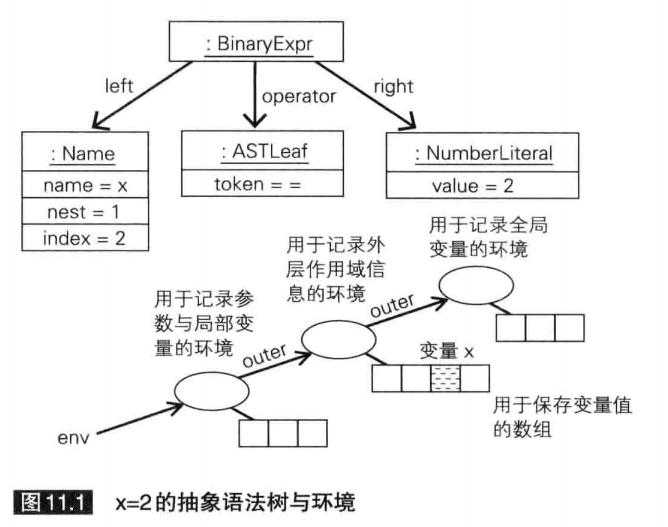
如果希望在Name对象的字段中保存变量的引用,仅凭数组元素仍然不够,还需要同时记录与环境对应的作用域。环境将以嵌套结构实现闭包。为此,Environment对象需要通过outer字段串连。此外,Name对象还要记录环境所处的层数,即从最内层向外数起,当前环境在这一连串Environment对象中的排序位置。该信息保存于Name对象的nest字段中。index字段则用于记录变量的值在与nest字段指向的环境对应的数组中,具体的保存位置。
下图是表示x=2的抽象语法树。在该图中,变量x的值保存于从最内层数起的第2个环境对应的数组中,因此Name对象的nest字段的值为1(如果是最内层,则值为0)。由于变量x的值保存于该数组的第3个元素中,因此index字段的值为2
为了实现一个通过数组来保存变量值的环境,需要新定义一个ArrayEnv类。提供了与NestedEnv类几乎相同的功能,实现了Environment接口。ArrayEnv类没有使用哈希表,仅通过简单的数组实现了变量值的保存。
package chap11;
import stone.StoneException;
import chap11.EnvOptimizer.EnvEx2;
import chap6.Environment;
public class ArrayEnv implements Environment {
protected Object[] values;
protected Environment outer;
public ArrayEnv(int size, Environment out) {
values = new Object[size];
outer = out;
}
public Symbols symbols() {
throw new StoneException("no symbols");
}
public Object get(int nest, int index) {
if (nest == 0)
return values[index];
else if (outer == null)
return null;
else
return ((EnvEx2) outer).get(nest - 1, index);
}
public void put(int nest, int index, Object value) {
if (nest == 0)
values[index] = value;
else if (outer == null)
throw new StoneException("no outer environment");
else
((EnvEx2) outer).put(nest - 1, index, value);
}
public Object get(String name) {
error(name);
return null;
}
public void put(String name, Object value) {
error(name);
}
public void putNew(String name, Object value) {
error(name);
}
public Environment where(String name) {
error(name);
return null;
}
public void setOuter(Environment e) {
outer = e;
}
private void error(String name) {
throw new StoneException("cannot access by name: " + name);
}
}ArrayEnv实现了用于记录函数的参数与局部变量的环境,但要记录全局变量,我们还需要另外设计一个不同的类,使用该类的对象来实现用于记录全局变量的环境。除了ArrayEnv类的功能,该类还需要随时记录变量的名称与变量值的保存位置(也就是数组元素的下标)之间的对应关系。它不仅能够通过编号查找变量值,还能通过变量名找到与之相应的变量值。
之前设计的Stone语言处理器可以在执行程序的同时以对话的形式添加新的语句。用户不必一次输入全部程序,从头至尾完整运行。因此,为了让之后添加的语句也能访问全局变量,我们必须始终记录变量的名称与该值保存位置的对应关系。
语言处理器必须能够通过变量名查找新添加语句中使用的变量值的保存位置。
另一方面,局部变量仅能在函数内部引用。函数在定义完成时就能确定所有引用了局部变量之处,且之后无法新增。这时,所有引用该变量的标识符都会在各自的Name对象中记录它的保存位置。由于语言处理器记录了这些信息之后便无需再了解变量名与保存位置的对应关系,因此环境不必记录变量的名称。作为用于记录局部变量的环境,ArrayEnv对象已经足够。
代码清单11.2中的ResizableArrayEnv类用于实现记录全局变量的环境。它是ArrayEnv的子类。ArrayEnv对象只能保存固定数量的变量,ResizableArrayEnv对象则能保存任意数量的变量。
由于程序新增的语句可能会引入新的全局变量,因此环境能够保存的变量数量也必须能够修改。ResizableArrayEnv类的对象含有names字段,它的值是一个Symbols对象。Symbols对象是一张哈希表,用于记录变量名与保存位置之间的对应关系。代码清单11.3是Symbols类的定义。
package chap11;
import java.util.Arrays;
import chap6.Environment;
import chap11.EnvOptimizer.EnvEx2;
public class ResizableArrayEnv extends ArrayEnv {
protected Symbols names;
public ResizableArrayEnv() {
super(10, null);
names = new Symbols();
}
@Override
public Symbols symbols() {
return names;
}
@Override
public Object get(String name) {
Integer i = names.find(name);
if (i == null)
if (outer == null)
return null;
else
return outer.get(name);
else
return values[i];
}
@Override
public void put(String name, Object value) {
Environment e = where(name);
if (e == null)
e = this;
((EnvEx2) e).putNew(name, value);
}
@Override
public void putNew(String name, Object value) {
assign(names.putNew(name), value);
}
@Override
public Environment where(String name) {
if (names.find(name) != null)
return this;
else if (outer == null)
return null;
else
return ((EnvEx2) outer).where(name);
}
@Override
public void put(int nest, int index, Object value) {
if (nest == 0)
assign(index, value);
else
super.put(nest, index, value);
}
protected void assign(int index, Object value) {
if (index >= values.length) {
int newLen = values.length * 2;
if (index >= newLen)
newLen = index + 1;
values = Arrays.copyOf(values, newLen);
}
values[index] = value;
}
}package chap11;
import java.util.HashMap;
public class Symbols {
public static class Location {
public int nest, index;
public Location(int nest, int index) {
this.nest = nest;
this.index = index;
}
}
protected Symbols outer;
protected HashMap<String, Integer> table;
public Symbols() {
this(null);
}
public Symbols(Symbols outer) {
this.outer = outer;
this.table = new HashMap<String, Integer>();
}
public int size() {
return table.size();
}
public void append(Symbols s) {
table.putAll(s.table);
}
public Integer find(String key) {
return table.get(key);
}
public Location get(String key) {
return get(key, 0);
}
public Location get(String key, int nest) {
Integer index = table.get(key);
if (index == null)
if (outer == null)
return null;
else
return outer.get(key, nest + 1);
else
return new Location(nest, index.intValue());
}
public int putNew(String key) {
Integer i = find(key);
if (i == null)
return add(key);
else
return i;
}
public Location put(String key) {
Location loc = get(key, 0);
if (loc == null)
return new Location(0, add(key));
else
return loc;
}
protected int add(String key) {
int i = table.size();
table.put(key, i);
return i;
}
}接下来为抽象语法树中的类添加1ookup方法,它的作用是在函数定义时,查找函数用到的所有变量,并确定它们在环境中的保存位置。该方法还将根据需要,在抽象语法树的节点对象中记录这些保存位置。这样语言处理器就能够通过编号来查找保存在环境中的变量值
代码清单11.4是为抽象语法树的各个类添加lookup方法的修改器。这里仅对支持函数与闭包的Stone语言进行性能优化,不会涉及类的优化
lookup方法如果在遍历时发现了赋值表达式左侧的变量名,就会查找通过参数接收的Symbols对象,判断该变量名是否是第一次出现、尚未记录。如果它是首次出现的变量名,lookup方法将为它在环境中分配一个保存位置,在Symbols对象中记录由该变量名与保存位置组成的名值对。除了赋值,lookup方法还会在所有引用该变量的抽象语法树节点中记录变量值的保存位置
package chap11;
import static javassist.gluonj.GluonJ.revise;
import javassist.gluonj.*;
import java.util.List;
import stone.Token;
import stone.StoneException;
import stone.ast.*;
import chap11.Symbols.Location;
import chap6.Environment;
import chap6.BasicEvaluator;
import chap7.ClosureEvaluator;
@Require(ClosureEvaluator.class)
@Reviser public class EnvOptimizer {
@Reviser public static interface EnvEx2 extends Environment {
Symbols symbols();
void put(int nest, int index, Object value);
Object get(int nest, int index);
void putNew(String name, Object value);
Environment where(String name);
}
@Reviser public static abstract class ASTreeOptEx extends ASTree {
public void lookup(Symbols syms) {}
}
@Reviser public static class ASTListEx extends ASTList {
public ASTListEx(List<ASTree> c) { super(c); }
public void lookup(Symbols syms) {
for (ASTree t: this)
((ASTreeOptEx)t).lookup(syms);
}
}
@Reviser public static class DefStmntEx extends DefStmnt {
protected int index, size;
public DefStmntEx(List<ASTree> c) { super(c); }
public void lookup(Symbols syms) {
index = syms.putNew(name());
size = FunEx.lookup(syms, parameters(), body());
}
public Object eval(Environment env) {
((EnvEx2)env).put(0, index, new OptFunction(parameters(), body(),
env, size));
return name();
}
}
@Reviser public static class FunEx extends Fun {
protected int size = -1;
public FunEx(List<ASTree> c) { super(c); }
public void lookup(Symbols syms) {
size = lookup(syms, parameters(), body());
}
public Object eval(Environment env) {
return new OptFunction(parameters(), body(), env, size);
}
public static int lookup(Symbols syms, ParameterList params,
BlockStmnt body)
{
Symbols newSyms = new Symbols(syms);
((ParamsEx)params).lookup(newSyms);
((ASTreeOptEx)revise(body)).lookup(newSyms);
return newSyms.size();
}
}
@Reviser public static class ParamsEx extends ParameterList {
protected int[] offsets = null;
public ParamsEx(List<ASTree> c) { super(c); }
public void lookup(Symbols syms) {
int s = size();
offsets = new int[s];
for (int i = 0; i < s; i++)
offsets[i] = syms.putNew(name(i));
}
public void eval(Environment env, int index, Object value) {
((EnvEx2)env).put(0, offsets[index], value);
}
}
@Reviser public static class NameEx extends Name {
protected static final int UNKNOWN = -1;
protected int nest, index;
public NameEx(Token t) { super(t); index = UNKNOWN; }
public void lookup(Symbols syms) {
Location loc = syms.get(name());
if (loc == null)
throw new StoneException("undefined name: " + name(), this);
else {
nest = loc.nest;
index = loc.index;
}
}
public void lookupForAssign(Symbols syms) {
Location loc = syms.put(name());
nest = loc.nest;
index = loc.index;
}
public Object eval(Environment env) {
if (index == UNKNOWN)
return env.get(name());
else
return ((EnvEx2)env).get(nest, index);
}
public void evalForAssign(Environment env, Object value) {
if (index == UNKNOWN)
env.put(name(), value);
else
((EnvEx2)env).put(nest, index, value);
}
}
@Reviser public static class BinaryEx2 extends BasicEvaluator.BinaryEx {
public BinaryEx2(List<ASTree> c) { super(c); }
public void lookup(Symbols syms) {
ASTree left = left();
if ("=".equals(operator())) {
if (left instanceof Name) {
((NameEx)left).lookupForAssign(syms);
((ASTreeOptEx)right()).lookup(syms);
return;
}
}
((ASTreeOptEx)left).lookup(syms);
((ASTreeOptEx)right()).lookup(syms);
}
@Override
protected Object computeAssign(Environment env, Object rvalue) {
ASTree l = left();
if (l instanceof Name) {
((NameEx)l).evalForAssign(env, rvalue);
return rvalue;
}
else
return super.computeAssign(env, rvalue);
}
}
}代码清单11.4中的修改器将覆盖一些类的eval方法。如上所述,经过这些修改,eval方法将根据由lookup方法记录的保存位置,从环境中获取变量的值或对其进行更新
ParameterList类、Name类与BinaryExpr类的eval方法修改较为简单。Defstmnt类与Fun类的eval在修改后返回的将不再是Function类的对象,而是一个由代码清单11.5定义的OptFunction对象。OptFunction类是Function类的子类,OptFunction对象同样用于表示函数。两者的区别在于,OptFunction类将通过ArrayEnv对象来实现函数的执行环境
至此,所有修改都已完成。代码清单11.6与代码清单11.7分别是用于执行修改后的语言处理器的解释器,以及该解释器的启动程序
package chap11;
import stone.ast.BlockStmnt;
import stone.ast.ParameterList;
import chap6.Environment;
import chap7.Function;
public class OptFunction extends Function {
protected int size;
public OptFunction(ParameterList parameters, BlockStmnt body, Environment env, int memorySize) {
super(parameters, body, env);
size = memorySize;
}
@Override
public Environment makeEnv() {
return new ArrayEnv(size, env);
}
}package chap11;
import chap6.BasicEvaluator;
import chap6.Environment;
import chap8.Natives;
import stone.BasicParser;
import stone.ClosureParser;
import stone.CodeDialog;
import stone.Lexer;
import stone.ParseException;
import stone.Token;
import stone.ast.ASTree;
import stone.ast.NullStmnt;
public class EnvOptInterpreter {
public static void main(String[] args) throws ParseException {
run(new ClosureParser(), new Natives().environment(new ResizableArrayEnv()));
}
public static void run(BasicParser bp, Environment env) throws ParseException {
Lexer lexer = new Lexer(new CodeDialog());
while (lexer.peek(0) != Token.EOF) {
ASTree t = bp.parse(lexer);
if (!(t instanceof NullStmnt)) {
((EnvOptimizer.ASTreeOptEx) t).lookup(((EnvOptimizer.EnvEx2) env).symbols());
Object r = ((BasicEvaluator.ASTreeEx) t).eval(env);
System.out.println("=> " + r);
}
}
}
}package chap11;
import chap8.NativeEvaluator;
import javassist.gluonj.util.Loader;
public class EnvOptRunner {
public static void main(String[] args) throws Throwable {
Loader.run(EnvOptInterpreter.class, args, EnvOptimizer.class, NativeEvaluator.class);
}
}接下来可以通过第八天代码清单8.6中的计算斐波那契的程序来比较优化前后的执行时间,最终结果计算速度至少提升了70%
标签:修改器 arrays oca ram 覆盖 eval block list 环境
原文地址:https://www.cnblogs.com/ZCWang/p/12231283.html