标签:interface 赋值函数 exce except function org case 原因 数列
Go不是一门纯函数式的编程语言,但是函数在Go中是“第一公民”,表现在:
Go是通过编译成本地代码且基于“堆栈”式执行的,Go的错误处理和函数也有千丝万缕的联系。
函数是Go程序源代码的基本构造单位,一个函数的定义包括如下几个部分:
1.函数声明关键字func
2.函数名
3.参数列表
4.返回列表
5.函数体。
函数名遵循标识符的命名规则,首字母的大小写决定该函数在其他包的可见性:大写时其他包可见,小写时只有相同的包可以访问;
函数的参数和返回值需要使用“()”包裹,如果只有一个返回值,而且使用的是非命名的参数,则返回参数的“()”可以省略。
函数体使用“{}”包裹,并且“{”必须位于函数返回值同行的行尾。
func funcName(param-list) (result-list) {
function-body
}函数的特点
func A() {
//do something
//...
}
func A() int {
//do something
//...
return 1
)func add(a, b int) int { //a int, b int简写为a, b int
return a+b
}//sum 相当于函数内的局部变量,被初始化为0
func add(a, b int) (sum int) { //sum 是命名返回值变量
sum = a + b
return //return sum 简写
//sum := a + b //如果是sum := a + b,则相当于新声明一个sum变量命名返回变量sum覆盖
//return sum //需要显式的调用return sum
}func add(a, b int) (sum int) {
anonymous := fumc(x, y int) int {
return x + y
}
return anonymous(a, b)
}Go函数支持多值返回,定义多值返回的返回参数列表时要使用“()”包裹,支持命名参数的返回。
fune swap(a,b int) (int, int){
return b, a
}注意:
如果多值返回值有错误类型,则一般将错误类型作为最后一个返回值。
Go函数实参到形参的传递永远是值拷贝,有时函数调用后实参指向的值发生了变化,那是因为参数传递的是指针值的拷贝,实参是一个指针变量,传递给形参的是这个指针变量的副本,二者指向同一地址,本质上参数传递仍然是值拷贝。
func chvalue(a int) int {
a = a + 1
return a
}
func chpointer(a *int) {
*a = *a + 1
}
func main() {
a := 10
chvalue(a)
fmt.Println(a) //10 ,实参传递给形参是值拷贝
chpointer(&a)
fmt.Println(a) //11,仍然是值拷贝,但是复制的是地址值
}Go函数支持不定数目的形式参数,不定参数声明使用param ...type的语法格式。
函数的不定参数有如下几个特点:
func sum(arr ...int) (sum int) {
for _, v := range arr { //此时 arr 就相当于切片,可以使用 range 访问
sum += v
}
return
}func sum(arr ...int) (sum int) {
for _, v := range arr { //此时 arr 就相当于切片,可以使用 range 访问
sum += v
}
return
}
func main() {
slice := []int{1, 2, 3, 4} //切片
array := [...]int{1, 2, 3, 4} //数组
//数组不可以作为实参传递给不定参数的函数
sum(slice...)
}func suma(arr ...int) (sum int) {
for _, v := range arr { //此时 arr 就相当于切片,可以使用 range 访问
sum += v
}
return
}
func sumb(arr []int) (sum int) {
for v := range arr {
sum += v
}
return
}
func main() {
fmt.Printf("%T", suma) //func(...int) int
fmt.Printf("%T", sumb) //func([]int) int
}函数类型又叫函数签名,一个函数的类型就是函数定义首行去掉函数名、参数名和"{",可以使用fimt.Printf的“%T“格式化参数打印函数的类型。如上程序。
两个函数类型相同的条件是:拥有相同的形参列表和返回值列表(列表元素的次序、个数和类型都相同),形参名可以不同。以下2个函数的函数类型完全一样。
func add(a,b int) int { return a+b }
func sub(x int, y int)(c int) { c = x-y; return c }可以使用type定义函数类型,函数类型变量可以作为函数的参数或返回值
package main
import "fmt"
func add(a, b int) int {
return a + b
}
func sub(a, b int) int {
return a - b
}
type Op func(int, int) int //定义一个函数类型,输入的是两个int类型,返回值是一个int类型
func do(f Op, a, b int) int {
return f(a, b) //函数类型变量可以直接用来进行函数调用
}
func main() {
a := do(add, 1, 2) //函数名add可以当作相同函数类型形参
fmt.Println(a) //3
s := do(sub, 1, 2)
fmt.Println(s) //-1
}函数类型和map、slice、chan一样,实际函数类型变量和函数名都可以当作指针变量,该指针指向函数代码的开始位置。
通常说函数类型变量是一种引用类型,未初始化的函数类型的变量的默认值是nil。
Go中有名函数的函数名可以看作函数类型的常量,可以直接使用函数名调用函数,也可以直接赋值给函数类型变量,后续通过该变量来调用该函数。
package main
func sum(a, b int) int {
return a + b
}
func main() {
sum(3, 4) //1.直接调用
f := sum //2.有名函数可以直接赋值给变量
f(1, 2)
}匿名函数可以看作函数字面量,所有直接使用函数类型变量的地方都可以由匿名函数代替。匿名函数可以直接赋值给函数变量,可以当作实参,也可以作为返回值,还可以直接被调用。
package main
import "fmt"
//匿名函数被直接赋值函数变量
var sum = func(a, b int) int {
return a + b
}
func doinput(f func(int, int) int, a, b int) int {
return f(a, b)
}
func wrap(op string) func(int, int) int {
switch op {
case "add":
return func(a, b int) int {
return a + b
}
case "sub":
return func(a, b int) int {
return a - b
}
default:
return nil
}
}
func main() {
//匿名函数直接被调用
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
sum(1, 2)
//匿名函数作为实参
doinput(func(x, y int) int {
return x + y
}, 1, 2)
opFunc := wrap("add")
re := opFunc(2, 3) //5
fmt.Printf("%d\n", re)
}package main
func main() {
//先进后出
defer func() {
println("first")
}()
defer func() {
println("second")
}()
println("function bldy")
}
//结果(先注册,后执行)
//function bldy
//second
//first函数或方法的调用,不能是语句,否则会报expression in defer must be function call错误。func f() int {
a := 0
defer func(i int) {
println("defer i=", i) //defer i= 0
}(a) //a注册时是以值拷贝传递,所以先执行a++也不会影响注册时的a值
a++
return a
}
func main() {
a := f()
fmt.Println(a) //1
}os.Exit(int)退出进程时,defer将不再被执行(即使defer已经提前注册)。func main() {
defer func() {
println("defer")
}()
println("func body")
os.Exit(1)
}
//运行结果
//func bodydefer的好处是可以在一定程度上避免资源泄漏,特别是在有很多return语句,有多个资源需要关闭的场景中,很容易漏掉资源的关闭操作。例如:
func CopyFile(dst, src string) (w int64, err error) {
src, err := os.Open(src)
if err != nil {
return
}
dst, err := os.Create(dst)
if err != nil {
src.Close() //src 很容易忘记关闭
return
}
w, err = io.Copy(dst, src)
dst.Close()
src.Close()
return
}使用defer改写后,在打开资源无报错后直接调用defer关闭资源,一旦养成这样的编程习惯,则很难会忘记资源的释放。
func CopyFile(dst, src string) (w int64, err error) {
src, err := os.Open(src)
if err != nil {
return
}
defer src.Close
dst, err := os.Create(dst)
if err != nil {
return
}
defer dst.Close()
w, err = io.Copy(dst, src)
return
}defer语句的位置不当,有可能导致panic,一般 defer 语句放在错误检查语句之后。
defer也有明显的副作用:defer会推迟资源的释放,defer尽量不要放到循环语句里面,将大函数内部的defer语句单独拆分成一个小函数是一种很好的实践方式。
defer相对于普通的函数调用需要间接的数据结构的支持,相对于普通函数调用有一定的性能损耗。
defer中最好不要对有名返回值参数进行操作,否则会引发匪夷所思的结果。
闭包是由函数及其相关引用环境组合而成的实体,一般通过在匿名函数中引用外部函数的局部变量或包全局变量构成。
闭包=函数+引用环境
闭包对闭包外的环境引入是直接引用,编译器检测到闭包,会将闭包引用的外部变量分配到堆上。
如果函数返回的闭包引用了该函数的局部变量(参数或函数内部变量):
(1)多次调用该函数,返回的多个闭包所引用的外部变量是多个副本,原因是每次调用函数都会为局部变量分配内存。
(2)用一个闭包函数多次,如果该闭包修改了其引用的外部变量,则每一次调用该闭包对该外部变量都有影响,因为闭包函数共享外部引用。
示例如下:
func fa(a int) func(i int) int {
return func(i int) int {
println(&a, a)
a = a + i
return a
}
}
func main() {
f := fa(1) //f引用的外部的闭包环境包括本次函数调用的形参a的值1
g := fa(1) //g引用的外部的闭包环境包括本次函数调用的形参a的值1
println(f(1))
println(f(1))
println(g(1))
println(g(1))
}
/*
运行结果:
0xc00004a000 1
2
0xc00004a000 2
3
0xc00004a008 1
2
0xc00004a008 2
3
*/f和g引用的是不同的a。
如果一个函数调用返回的闭包引用修改了全局变量,则每次调用都会影响全局变量。
如果函数返回的闭包引用的是全局变量a,则多次调用该函数返回的多个闭包引用的都是同一个a。同理,调用一个闭包多次引用的也是同一个a。此时如果闭包中修改了a值的逻辑,则每次闭包调用都会影响全局变量a的值。使用闭包是为了减少全局变量,所以闭包引用全局变量不是好的编程方式。
var (
a = 0
)
func fa() func(i int) int {
return func(i int) int {
println(&a, a)
a = a + 1
return a
}
}
func main() {
f := fa() //f引用外部的闭包环境包括全局变量a
g := fa() //g引用的外部环境闭包环境包括全局变量a
println(f(1)) //1
println(g(1)) //2
println(f(1)) //3
println(g(1)) //4
}
/*
运行结果:
0x4e49f8 0
1
0x4e49f8 1
2
0x4e49f8 2
3
0x4e49f8 3
4
*/用一个函数返回的多个闭包共享该函数的局部变量。
func fa(base int) (func(int) int, func(int) int) {
println(&base, base)
add := func(i int) int {
base += i
println(&base, base)
return base
}
sub := func(i int) int {
base -= i
println(&base, base)
return base
}
return add, sub
}
func main() {
f, g := fa(0) //f、g 闭包引用的 base 是同一个,是 fa 函数调用传递过来的实参值
s, k := fa(0) //s、k 闭包引用的 base 是同一个,是 fa 函数调用传递过来的实参值
println(f(1), g(2))
println(s(1), k(2))
}闭包最初的目的是减少全局变量,在函数调用的过程中隐式地传递共享变量,有其有用的一面;但是这种隐秘的共享变量的方式带来的坏处是不够直接,不够清晰,除非是非常有价值的地方,一般不建议使用闭包。
对象是附有行为的数据,而闭包是附有数据的行为,类在定义时已经显式地集中定义了行为,但是闭包中的数据没有显式地集中声明的地方,这种数据和行为耦合的模型不是一种推荐的编程模型,闭包仅仅是锦上添花的东西,不是不可缺少的。
但在有些情况,当程序发生异常时,无法继续运行。在这种情况下,我们会使用 panic 来终止程序。当函数发生 panic 时,它会终止运行,在执行完所有的延迟函数后,程序控制返回到该函数的调用方。这样的过程会一直持续下去,直到当前协程的所有函数都返回退出,然后程序会打印出 panic 信息,接着打印出堆栈跟踪(Stack Trace),最后程序终止。当程序发生 panic 时,使用 recover 可以重新获得对该程序的控制。
可以认为 panic 和 recover 与其他语言中的 try-catch-finally 语句类似,只不过一般我们很少使用 panic 和 recover。而当我们使用了 panic 和 recover 时,也会比 try-catch-finally 更加优雅,代码更加整洁。
什么时候应该使用 panic?
(需要注意的是:你应该尽可能地使用错误,而不是使用 panic 和 recover。只有当程序不能继续运行的时候,才应该使用 panic 和 recover 机制)
panic 有两个使用情况:
发生了一个不能恢复的错误,此时程序不能继续运行。 主动调用panic函数结束程序运行。
例如: web 服务器无法绑定所要求的端口。在这种情况下,就应该使用 panic,因为如果不能绑定端口,啥也做不了。
发生了一个编程上的错误。 在调试程序中,通过主动调用panic来实现快速推出,painc打印出的堆栈能更快的定位错误。
例如:我们有一个接收指针参数的方法,而其他人使用 nil 作为参数调用了它。在这种情况下,我们可以使用 panic,因为这是一个编程错误:用 nil 参数调用了一个只能接收合法指针的方法。
为了保证程序的健壮性,需要主动在程序的分支流程上使用recover()拦截运行时错误。
panic和recover的函数签名如下:
panic(i interface{})
recover()interface{}panic用法挺简单的, 其实就是throw exception。panic是golang的内建函数,panic会中断函数F的正常执行流程, 从F函数中跳出来, 跳回到F函数的调用者。 对于调用者来说, F看起来就是一个panic, 所以调用者会继续向上跳出, 直到当前goroutine返回。在跳出的过程中, 进程会保持这个函数栈。 当goroutine退出时, 程序会crash。
要注意的是, F函数中的defer定义的函数会正常执行, 按照defer的规则。
同时引起panic除了我们主动调用panic之外, 其他的任何运行时错误, 例如数组越界都会造成panic
调用panic的方法非常简单:panic(xxx)。
package main
import (
"fmt"
)
func main() {
test()
}
func test() {
defer func() { fmt.Println("打印前") }()
defer func() { fmt.Println("打印中") }()
defer func() { fmt.Println("打印后") }()
panic("触发异常")
fmt.Println("test")
}
/*
运行结果:
打印后
打印中
打印前
panic: 触发异常
goroutine 1 [running]:
main.test()
C:/Users/WINDSUN/Desktop/Golang/CloseFunc.go:15 +0xd1
main.main()
C:/Users/WINDSUN/Desktop/Golang/CloseFunc.go:8 +0x27
Process finished with exit code 2
*/panic与defer
panic 其实是一个终止函数栈执行的过程,但是在函数退出前都会执行defer里面的函数,直到所有的函数都退出后,才会执行panic。发生panic后,程序会从调用panic的函数位置或发生panic的地方立即返回,逐层向上执行函数的defer 语句,然后逐层打印函数调用堆栈,直到被recover 捕获或运行到最外层函数而退出。
func fullName(firstName *string, lastName *string) {
defer fmt.Println("deferred call in fullName")
if firstName == nil {
panic("runtime error: first name cannot be nil")
}
if lastName == nil {
panic("runtime error: last name cannot be nil")
}
fmt.Printf("%s %s\n", *firstName, *lastName)
fmt.Println("returned normally from fullName")
}
func main() {
defer fmt.Println("deferred call in main")
firstName := "Elon"
fullName(&firstName, nil)
fmt.Println("returned normally from main")
}
/*
运行结果:
deferred call in fullName
deferred call in main
panic: runtime error: last name cannot be nil
goroutine 1 [running]:
main.fullName(0xc00007df20, 0x0)
C:/Users/WINDSUN/Desktop/Golang/CloseFunc.go:14 +0x255
main.main()
C:/Users/WINDSUN/Desktop/Golang/CloseFunc.go:23 +0xe0
Process finished with exit code 2
*/panic不但可以在函数正常流程中抛出,在defer逻辑里也可以再次调用panic或抛出panic。如果defer中也有panic 那么会依次按照发生panic的顺序执行。
recover也是golang的一个内建函数, 其实就是try catch。
不过需要注意的是:
1. recover如果想起作用的话, 必须在defer函数中使用。
2. 在正常函数执行过程中,调用recover没有任何作用, 他会返回nil。如这样:fmt.Println(recover()) 。
3. 如果当前的goroutine panic了,那么recover将会捕获这个panic的值,并且让程序正常执行下去。不会让程序crash。
package main
import "fmt"
func main() {
fmt.Println("c")
defer func() { // 必须要先声明defer,否则不能捕获到panic异常
fmt.Println("d")
if err := recover(); err != nil {
fmt.Println(err) // 这里的err其实就是panic传入的内容
}
fmt.Println("e")
}()
f() //开始调用f
fmt.Println("f") //这里开始下面代码不会再执行
}
func f() {
fmt.Println("a")
panic("异常信息")
fmt.Println("b") //这里开始下面代码不会再执行
}
/*
运行结果:
c
a
d
异常信息
e
Process finished with exit code 0
*/可以有连续多个panic被抛出,连续多个panic的场景只能出现在延迟调用里面,否则不会出现多个panic被抛出的场景。但只有最后一次panic能被捕获。
package main
import "fmt"
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
//只有最后一次panic调用能够被捕获
defer func() {
panic("first defer panic")
}()
defer func() {
panic("second defer panic")
}()
panic("main body panic")
}
/*
运行结果:
first defer panic
*/Go的错误处理涉及接口的相关知识。
error
Go 语言内置错误接口类型error。任何类型只要实现Error() string方法,都可以传递error接口类型变量。Go语言典型的错误处理方式是将error作为函数最后一个返回值。在调用函数时,通过检测其返回的error值是否为nil来进行错误处理。
type error interface {
Error() string
}Go语言标准库提供的两个函数返回实现了error接口的具体类型实例,一般的错误可以使用这两个函数进行封装。遇到复杂的错误,用户也可以自定义错误类型,只要其实现error接口即可。例如:
//http://golang. org/src/pkg/fmt/print. go
//ErrOFf formats according to a format specifier and returns the string
//as a value that satisfies error.
func Errorf(format string, a... interface{}) errort {
return errors.New(Sprintf(format,a...))
}
//http://golang. org/src/pkg/errors/errors. go
//New returns an error that formats as the given text.
func New(text string) error {
return &errorString{ text }
}错误处理的最佳实践:
error!=nil的异常场景,正常逻辑放到if语句块的后面,保持代码平坦。错误和异常
广义上的错误:发生非期望的行为
狭义的错误:发生非期望的已知行为,这里的已知是指错误的类型是预料并定义好的。
异常:发生非期望的未知行为,未知是指错误的类型不在预先定义的错误。异常又被称为未捕获的错误。未捕获由操作系统进行异常处理,如C语言中的段错误。
错误关系如图:

Go是一门类型安全的语言,其运行时不会出现这种编译器和运行时都无法捕获的错误,也就是说,不会出现untrapped error,所以从这个角度来说,Go语言不存在所谓的异常,出现的“异常”全是错误。
Go程序需要处理的这些错误可以分为两类:
Go对于错误提供了两种处理机制:
(1)通过函数返回错误类型的值来处理错误。
(2)通过panic打印程序调用栈,终止程序执行来处理错误。
error和panic使用遵循如下规则:
(1)程序发生的错误导致程序不能容错继续执行,此时程序应该主动调用panic或由运行时抛出panic。
(2)程序虽然发生错误,但是程序能够容错继续执行,此时应该使用错误返回值的方式处理错误,或者在可能发生运行时错误的非关键分支上使用recover 捕获panic。
go的整个错误处理过程如图:
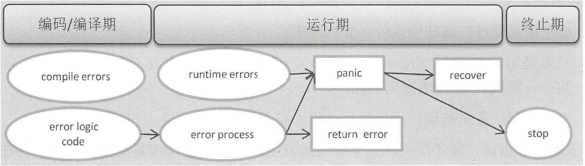
Go程序的有些错误是在运行时进行检测的,运行期的错误检测包括空指针、数组越界等。
如果运行时发生错误,则程序出于安全设计会自动产生panic。另外,程序在编码阶段通过主动调用panic来进行快速报错,这也是一种有效的调试手段。
标签:interface 赋值函数 exce except function org case 原因 数列
原文地址:https://www.cnblogs.com/WindSun/p/12232260.html