标签:处理过程 理解 机制 精确 要求 扫描 溢出 标记 技术
以前收集器的特点
- 年轻代和老年代是各自独立且连续的内存块
- 年轻代收集必须使用单个eden+S0+S1进行复制算法
- 老年代收集扫描整个老年代区域
- 都是以尽可能少而快速地执行GC为设计原则
G1是什么
G1(Garbage-Frist)收集器,是一款面向服务端应用的收集器

从官网的描述中,我们知道G1是一种服务器端的垃圾收集器,应用在多处理器和大容量内存环境中,在提高吞吐量的同时,尽可能的满足垃圾收集暂停时间的要求。另外,它还具有以下特性:
- 像CMS收集器一样,能与应用程序线程并发执行
- 整理空闲空间更快
- 需要更多的时间来预测GC停顿时间
- 不希望牺牲大量的吞吐性能
- 不需要更大的Java Heap
G1收集器的设计目标是取代CMS收集器,它同CMS相比,在以下方面表现更出色:
- G1是一个有整理内存过程的垃圾收集器,不会产生很多内存碎片
- G1的Stop-The-World(STW)更可控,G1在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
CMS垃圾集器虽然减少了暂停应用程序的运行时间,但是它还是存在着内存碎片问题。于是,为了去除内存碎片问题,同时又保留CMS垃圾收集器低暂停时间的优点,JAVA7发布了一个新的垃圾收集器-G1垃圾收集器。
G1是在2012年才在jdk1.7u4中可用。oracle官方计划在jdk9中将G1变成默认的垃圾收集器以替代CMS。它是一款面向服务端应用的收集器,主要应用在多CPU和大内存服务器环境下,极大的减少垃圾收集的停顿时间,全面提升服务器的性能,逐步替换java8以前的CMS收集器。
主要改变是Eden,Survivor和Tenured等内存区域不再是连续的了,而是变成了一个个大小一样的region,每个region从1M到32M不等。一个region有可能属于Eden,Survivor或者Tenured内存区域。
G1特点
- G1能充分利用多CPU、多核环境硬件优势,尽量缩短STW(除GC以后的线程暂停时间)
- G1整体上采用标记-整理算法,局部是通过复制算法,不会产生内存碎片。
- 宏观上看G1之中不再区分年轻代和老年代。把内存划分成多个独立的了区域(Region),可以近似理解为一个围棋的棋盘。
- G1收集器里面讲整个的内存区都混合在一起了,但其本身依然在小范围内要进行年轻代和老年代的区分,保留了新生代和老年代,但它们不再是物理隔离的,而是一部分Region的集合且不需要Region是连续的,也就是说依然会采用不同的GC方式来处理不同的区域。
- G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(tospace)堆做复制
准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换;
G1底层原理
Region区域化垃圾收集器
- 区域化内存划片Region,整体编为了一系列不连续的内存区域,避免了全内存区的GC操作。
- 核心思想是将整个堆内存区域分成大小相同的子区域(Region),在JVM启动时会自动设置这些子区域的大小,在堆的使用上,G1并不要求对象的存储一定是物理上连续的只要逻辑上连续即可,每个分区也不会固定地为某个代服务,可以按需在年轻代和老年代之间切换。启动时可以通过参数-XX:G1HeapRegionSize=n可指定分区大小(1MB~32MB,且必须是2的幂),默认将整堆划分为2048个分区。
- 大小范围在IMB、32MB,最多能设置2048个区域,也即能够支持的最大内存为:32MB2048=65536MB=64G内存
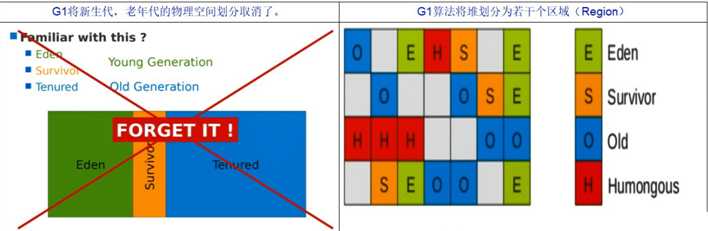
G1算法将堆划分为若干个区域(Region),它仍然属于分代收集器(在微观上来说仍然有将年轻代转移到老年代的操作存在)
这些Region的一部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者survivor空间。
这些Region的一部分包含老年代,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有CMS内存碎片问题的存在了。
在G1中,还有一种特殊的区域,叫Humongous(巨大的)区域
如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象默认直接会被分配在年老代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC
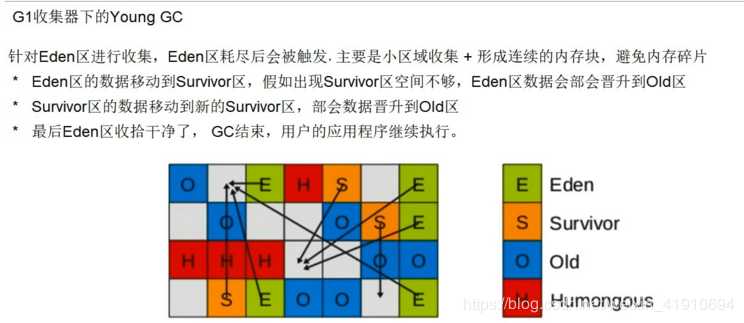
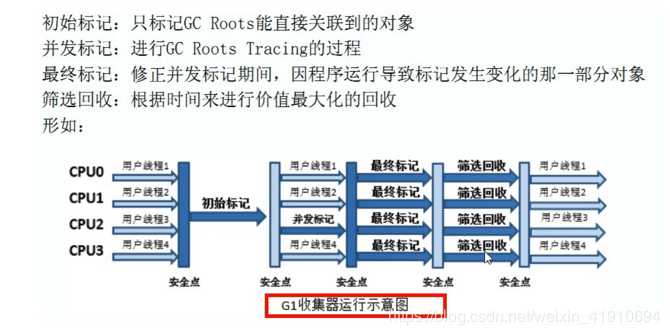
G1回收步骤
部分G1参数设置
- -XX:+UseG1GC
- -XX:G1HeapReginSize=n 设置的G1区域的大小。值是2的幂,范围是1MB到32MB。目标是根据最小的Java堆大小划分出约2048个区域
- -XX:MaxGCPauseMillis=n 最大GC停顿时间,这是个软目标,JVM将尽可以(但不保证)停顿小于这个时间
- -XX:InitiatingHeapOccupancyPercent 堆占用了多少的时候就触发GC,默认为45
- -XX:ConGCThreads 并发GC使用的线程数
- -XX:G1ReservePercent 设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险,默认是100%
和CMS相比的优势
比起CMS有两个优势:
1.G1不会产生内存碎片。
2.G1可以精确控制停顿。该收集器是把整个堆(新生代、老年代)划分成多个固定大小的区域,每次根据运行 停顿的时间去收集垃圾最多的区域。
java - GC垃圾收集器详解(三)
标签:处理过程 理解 机制 精确 要求 扫描 溢出 标记 技术
原文地址:https://www.cnblogs.com/cjunn/p/12233492.html