标签:删除 参数 查看 排序 nbsp mil mic 搜索 数据
符号:^ 开头
$ 结尾
awk 是一种处理文本的语言,一个强大的文本分析命令!
1:提取文件中的每行的第二个
提取前文本中内容为
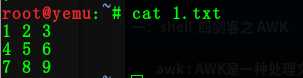
命令:cat 1.txt | awk ‘{print($2)}‘
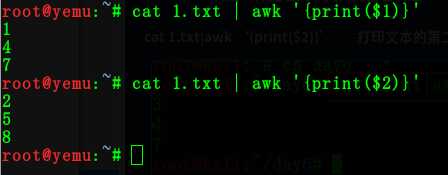
在 AWK 命令中,它将文本每列的部分当做一部分!
或着我们可以指定分隔符,指定提取某一部分!
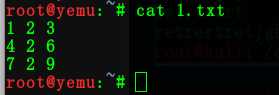
我们以2为分隔符
命令:cat 1.txt | awk -F "2" ‘{print($2)}‘

输出前三行
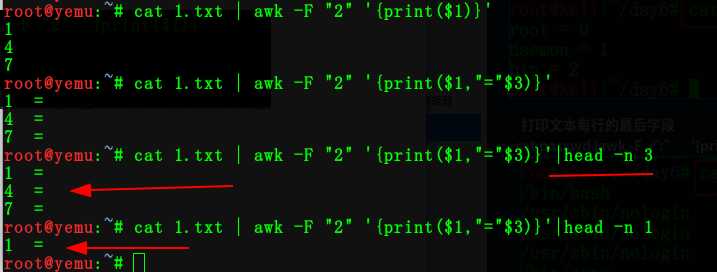
打印文件每行最后的字段
命令:cat 1.txt|awk "2" ‘{print($NF)}‘

sed 是一种流编编器,它是文本处理中非常中的工具
能够完美的配合正则表达式便用,功物能不同凡响。
提取前 文本的内容
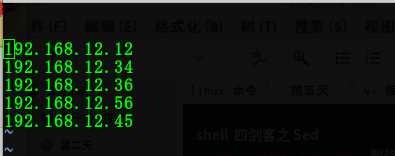
1:删除文本内空白的内容!
命令:cat 1.txt |sed ‘/^\s*$/d‘
删除注释的行
命令:cat 1.txt | sed ‘/^#.*/d‘
这里就不实操了!
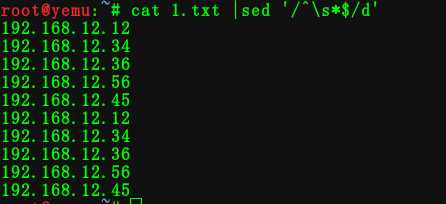
2:替换文本里的东西
命令:cat 1.txt | sed ‘s#^192#ym#g‘
将 192 替换为 ym
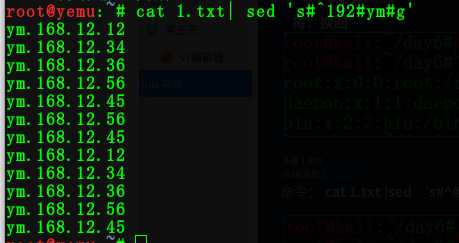
3:在文本的开头或结尾添加东西
命令:cat 1.txt | sed ‘s#^#https://#g‘
4:在文本后面添加东西
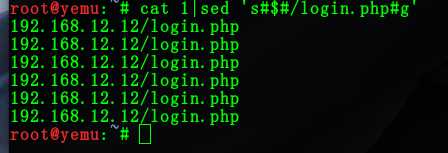
命令:cat 1.txt | sed ‘s#$#/login.php#g‘
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式
预设 grep 指令会把含有范本样式的那一列显示出来。
若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
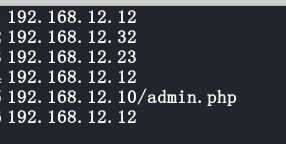
示范前的文本内容:
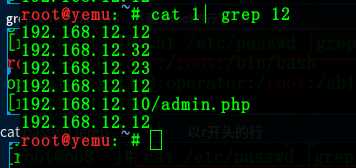
1:查看含有12的行
命令:cat 1 | grep 12
2:匹配含有 12 的行
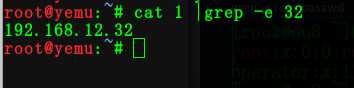
3:查找以 192 开头的行
命令:cat 1 | grep -E ‘^192'
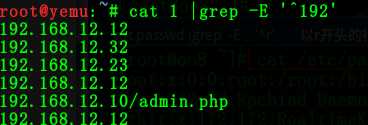
4:查找以 php 结尾的行
命令:cat 1 | grep -E ‘php$‘

5:在多级目录中对文本进行递归查找。
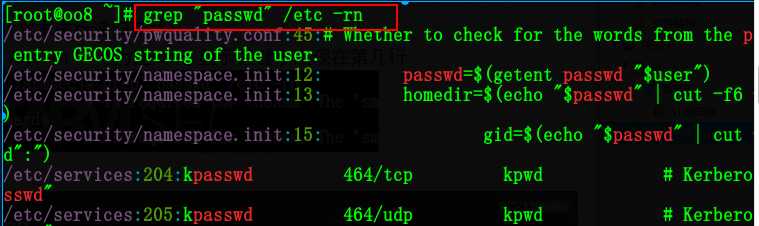
grep “passwd” /etc -rn
-r 为递归 -n 显示关键字出现在第几行
find 命令:用来在指定目录下查找文件。
任何位于参数之前的字符串都将被视为欲查找的目录名。
如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。
并且将查找到的子目录和文件全部进行显示。
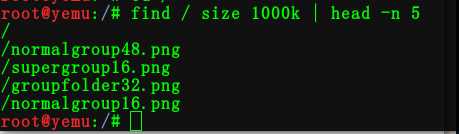
1:在 / 目录下,按照大小查找,并只输出前5行
命令:find / size 1000k | head -n 5
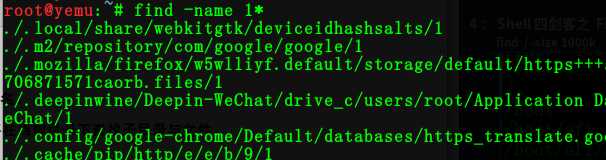
2:在当前目录下查找以1开头的文件
命令:find -name 1*
3:按照属主查找
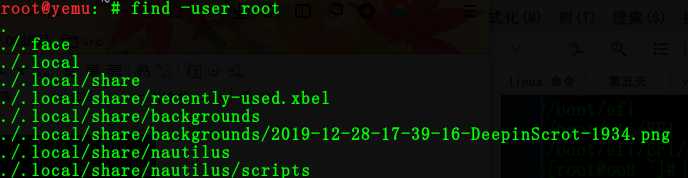
命令:find / -user root | head -n 5
4:搜索7天内当前目录下修改过的文件
命令:find . -type f -mtime -7 |head -n 10
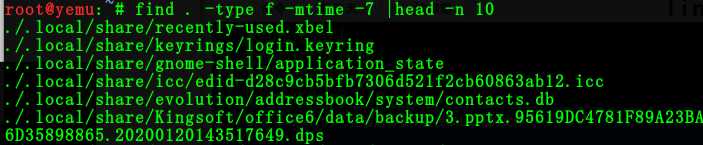
-7 代表7天内 7 代表前7天那一天 +7 代表7天前
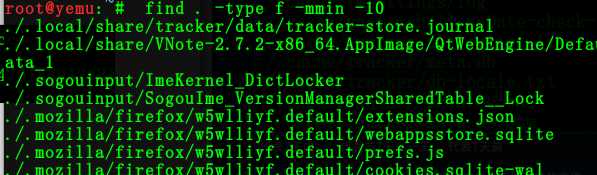
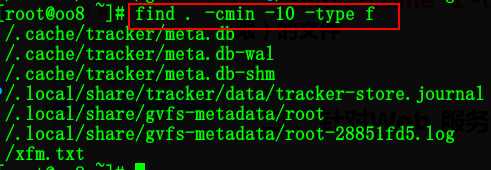
5:搜索10分钟内当前目录下修改过的文件
find . -type f -mmin -10
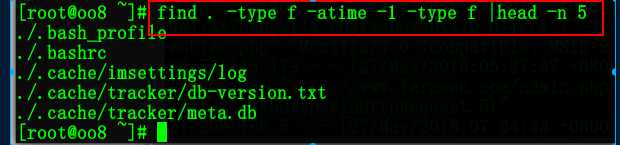
find . -atime -1 -type f
搜索当前目录下一天内被访问的文件
(-1 代表1天内 1代表前1天那一天 +1 代表1天前)
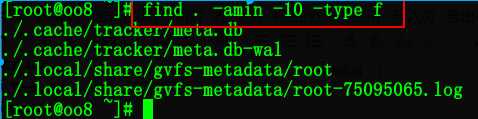
find . -atime -10 -type f
搜索当前目录下10分钟内被访问的文件
find . -ctime -1 -type f
搜索当前目录下一天内状态被改变(列如权限)的文件
针对Web 服务器日志进行分析
统计IP地址的访问数量并按照数量进行排序
cat access_log |awk ‘{print($1)}’|sort |uniq -c | sort -nr |more
标签:删除 参数 查看 排序 nbsp mil mic 搜索 数据
原文地址:https://www.cnblogs.com/yemu/p/12233591.html