标签:app ble likely ica code rem 情况下 激活 selected
\1. Suppose your training examples are sentences (sequences of words). Which of the following refers to the jth word in the ith training example?( 假设你的训练样本是句子(单词序列),下 面哪个选项指的是第??个训练样本中的第??个词?)
【 】 $??^{(??)} $
【 】 \(??^{<??>(??) }\)
【 】 \(??^{(??)<??>}\)
【 】 \(??^{<??>(??)}\)
【★】 ??(??) (注:首先获取第??个训练样本(用括号表示),然后到??列获取单词(用括尖括号表示)。)
?
\2. Consider this RNN: This specific type of architecture is appropriate when: (看一下下面的这 个循环神经网络:在下面的条件中,满足上图中的网络结构的参数是)
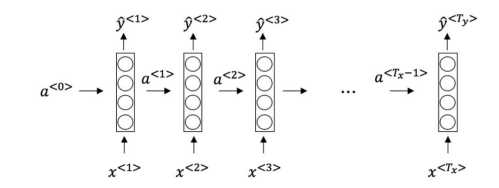
【 】$??_?? = ??_?? $
【 】 $??_?? < ??_?? $
【 】\(??_?? > ??_??\)
【 】$ ??_?? = 1 $
【★】???? = ????
?
\3. To which of these tasks would you apply a many-to-one RNN architecture? (Check all that apply). (上图中每一个输入都与输出相匹配。 这些任务中的哪一个会使用多对一的 RNN 体 系结构?)
【 】 Speech recognition (input an audio clip and output a transcript) (语音识别(输入语音, 输出文本)。)
【 】 Sentiment classification (input a piece of text and output a 0/1 to denote positive or negative sentiment) (情感分类(输入一段文字,输出 0 或 1 表示正面或者负面的情绪)。)
【 】Image classification (input an image and output a label) (图像分类(输入一张图片,输出 对应的标签)。)
【 】 Gender recognition from speech (input an audio clip and output a label indicating the speaker’s gender) (人声性别识别(输入语音,输出说话人的性别)。)
【★】 Sentiment classification (input a piece of text and output a 0/1 to denote positive or negative sentiment) (情感分类(输入一段文字,输出 0 或 1 表示正面或者负面的情绪)。)
【★】 Gender recognition from speech (input an audio clip and output a label indicating the speaker’s gender) (人声性别识别(输入语音,输出说话人的性别)。)
?
\4. You are training this RNN language model.
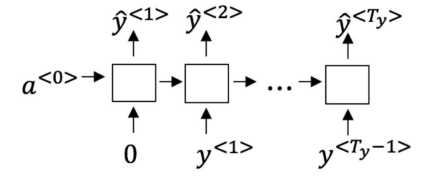
At the \(??^{th}\) time step, what is the RNN doing? Choose the best answer.( 假设你现在正在训练下面 这个 RNN 的语言模型: 在??时,这个 RNN 在做什么?)
【 】 Estimating ??(\(??^{<1>}, ??^{<2>},… , ??^{<???1>}\))( 计算 ??(\(??^{<1>}, ??^{<2>},… , ??^{<???1>}\)) )
【 】 Estimating ??(\(??^{<??>}\)) (计算 ??(\(??^{<??>}\)) )
【 】Estimating \(??(?? ∣ ??^{<1>}, ??^{<2>},… , ??^{<??>})\) ( 计算 \(??(?? ∣ ??^{<1>}, ??^{<2>},… , ??^{<??>})\))
【 】Estimating \(??(?? ∣ ??^{<1>}, ??^{<2>}, … , ??^{<???1>})\)( 计算 \(??(?? ∣ ??^{<1>}, ??^{<2>}, … , ??^{<???1>})\))
Yes,in a language model we try to predict the next step based on the knowledge of all prior steps
【★】Estimating ??(?? ∣ ?? <1>, ?? <2>,… , ?? ) ( 计算 ??(?? ∣ ?? <1>, ?? <2>, … , ?? ) )
?
\5. You have finished training a language model RNN and are using it to sample random sentences, as follows: What are you doing at each time step ???( 你已经完成了一个语言模型 RNN 的训练,并用它来对句子进行随机取样,如下图: 在每个时间步??都在做什么?)
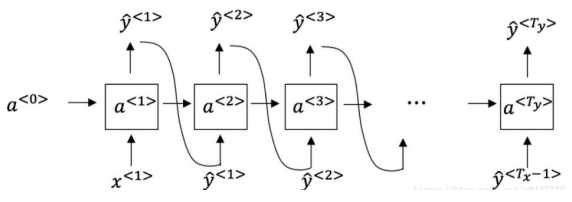
【 】Use the probabilities output by the RNN to pick the highest probability word for that time-step as \(??^{<??>}\). (ii) Then pass the ground-truth word from the training set to the next timestep. ((1)使用 RNN 输出的概率,选择该时间步的最高概率单词作为\(??^{<??>}\),(2)然后将训练集中 的正确的单词传递到下一个时间步。)
【 】Use the probabilities output by the RNN to randomly sample a chosen word for that time-step as \(??^{<??>}\). (ii) Then pass the ground-truth word from the training set to the next timestep. ((1)使用由 RNN 输出的概率将该时间步的所选单词进行随机采样作为 \(??^{<??>}\),(2)然后将训 练集中的实际单词传递到下一个时间步。)
【 】Use the probabilities output by the RNN to pick the highest probability word for that time-step as \(??^{<??>}\). (ii) Then pass this selected word to the next time-step. ((1)使用由 RNN 输出 的概率来选择该时间步的最高概率词作为 \(??^{<??>}\),(2)然后将该选择的词传递给下一个时间步。)
【 】 Use the probabilities output by the RNN to randomly sample a chosen word for that time-step as \(??^{<??>}\). (ii) Then pass this selected word to the next time-step. ((1)使用 RNN 该时间 步输出的概率对单词随机抽样的结果作为\(??^{<??>}\),(2)然后将此选定单词传递给下一个时间步。)
【★】 (i) Use the probabilities output by the RNN to randomly sample a chosen word for that time-step as ?? . (ii) Then pass this selected word to the next time-step. ((1)使用 RNN 该时间 步输出的概率对单词随机抽样的结果作为?? ,(2)然后将此选定单词传递给下一个时间步。)
?
\6. You are training an RNN, and find that your weights and activations are all taking on the value of NaN (“Not a Number”). Which of these is the most likely cause of this problem?
【 】 Vanishing gradient problem. (梯度消失。)
【 】Exploding gradient problem. (梯度爆炸。)
【 】 ReLU activation function g(.) used to compute g(z), where z is too large. (ReLU 函数作为 激活函数??(. ),在计算??(??)时,??的数值过大了。)
【 】 Sigmoid activation function g(.) used to compute g(z), where z is too large. (Sigmoid 函数 作为激活函数??(. ),在计算??(??)时,??的数值过大了。)
【★】Exploding gradient problem. (梯度爆炸。)
?
7.Suppose you are training a LSTM. You have a 10000 word vocabulary, and are using an LSTM with 100-dimensional activations a. What is the dimension of Γu at each time step?( 假设你正 在训练一个 LSTM 网络,你有一个 10,000 词的词汇表,并且使用一个激活值维度为 100 的 LSTM 块,在每一个时间步中,????的维度是多少?)
【 】 1
【 】 100
【 】300
【 】 10000
【★ 】 100
(注: ????的向量维度等于 LSTM 中隐藏单元的数量。)
?
\8. Here’re the update equations for the GRU. Alice proposes to simplify the GRU by always removing the \(??_??\). I.e., setting \(??_??\) = 1. Betty proposes to simplify the GRU by removing the \(??_??\) . I. e., setting \(??_??\)=1 always. Which of these models is more likely to work without vanishing gradient problems even when trained on very long input sequences?( 这里有一些 GRU 的更新方程: 爱丽丝建议通过移除\(??_??\)来简化 GRU, 即设置\(??_??\) = 1。贝蒂提出通过移除\(??_??\)来简化 GRU,即设置\(??_??\)=1。哪种模型更容易在梯度不消失问题的情况下训练,即使在很长的输入序列上也可以进行训练?)

【 】 Alice’s model (removing \(??_??\)), because if \(??_??\) ≈ 0 for a timestep, the gradient can propagate back through that timestep without much decay. (爱丽丝的模型(即移除 ????),因为对于一个 时间步而言,如果???? ≈ 0,梯度可以通过时间步反向传播而不会衰减。)
【 】Alice’s model (removing ????), because if ???? ≈ 1 for a timestep, the gradient can propagate back through that timestep without much decay. (爱丽丝的模型(即移除 ????),因为对于一个 时间步而言,如果???? ≈ 1,梯度可以通过时间步反向传播而不会衰减。)
【 】 Betty’s model (removing ???? ), because if ??u ≈ 0 for a timestep, the gradient can propagate back through that timestep without much decay. (贝蒂的模型(即移除????),因为对于一个时间 步而言,如果??u ≈ 0,梯度可以通过时间步反向传播而不会衰减。)
【 】Betty’s model (removing ???? ), because if ??u ≈ 1 for a timestep, the gradient can propagate back through that timestep without much decay. (贝蒂的模型(即移除????),因为对于一个时 间步而言,如果??u ≈ 1,梯度可以通过时间步反向传播而不会衰减。)
【★ 】 Betty’s model (removing ???? ), because if ??u ≈ 0 for a timestep, the gradient can propagate back through that timestep without much decay. (贝蒂的模型(即移除????),因为对于一个时间 步而言,如果??u ≈ 0,梯度可以通过时间步反向传播而不会衰减。)
(注:要使信号反向传播而不消失,我们需要?? 高度依赖于?? 。)
?
\9. Here are the equations for the GRU and the LSTM: From these, we can see that the Update Gate and Forget Gate in the LSTM play a role similar to _ and __ in the GRU. What should go in the the blanks?( 这里有一些 GRU 和 LSTM 的方程: 从这些 我们可以看到,在 LSTM 中的更新门和遗忘门在 GRU 中扮演类似___与___的角色,空白处应该 填什么?)
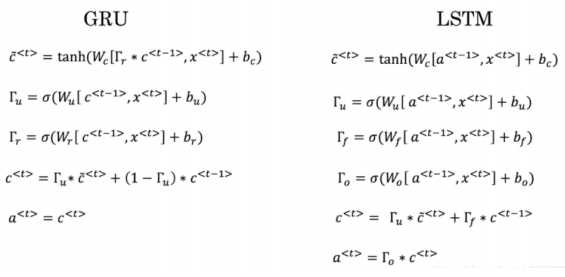
【 】???? 与 1 ? ???? (???? 与 1 ? ???? )
【 】????与 ???? (????与 ???? )
【 】1 ? ???? 与???? (1 ? ???? 与???? )
【 】???? 与???? (???? 与???? )
【★】???? 与 1 ? ???? (???? 与 1 ? ???? )
?
\10. You have a pet dog whose mood is heavily dependent on the current and past few days’ weather. You’ve collected data for the past 365 days on the weather, which you represent as a sequence as \(??^{<1>},… , ??^{<365>}\). You’ve also collected data on your dog’s mood, which you represent as \(??^{<1>}, … , ??^{<365>}\). You’d like to build a model to map from x→y. Should you use a Unidirectional RNN or Bidirectional RNN for this problem?( 你有一只宠物狗,它的心情很大 程度上取决于当前和过去几天的天气。你已经收集了过去 365 天的天气数据 \(??^{<1>},… , ??^{<365>}\),这些数据是一个序列,你还收集了你的狗心情的数据\(??^{<1>}, … , ??^{<365>}\),你想建立一个模型来从??到??进行映射,你应该使用单向 RNN 还是双向 RNN 来解决这个问 题?)
【 】Bidirectional RNN, because this allows the prediction of mood on day ?? to take into account more information. (双向 RNN,因为在??日的情绪预测中可以考虑到更多的信息。)
【 】 Bidirectional RNN, because this allows backpropagation to compute more accurate gradients.( 双向 RNN,因为这允许反向传播计算中有更精确的梯度。)
【 】 Unidirectional RNN, because the value of \(??^{<??>}\) depends only on \(??^{<1>},… , ??^{<??>}\) ,but not on \(??^{<??+1>},… , ??^{<365>}\) (单向 RNN,因为\(??^{<??>}\)的值仅依赖于\(??^{<1>},… , ??^{<??>}\),而不依赖于 \(??^{<??+1>},… , ??^{<365>}\)。)
【 】Unidirectional RNN, because the value of \(??^{<??>}\) depends only on \(??^{<??>}\), and not other days’ weather.( 单向 RNN,因为\(??^{<??>}\)的值只取决于\(??^{<??>}\),而不是其他天的天气。)
【★】 Unidirectional RNN, because the value of ?? depends only on ?? <1>,… , ?? ,but not on ?? ,… , ?? <365> (单向 RNN,因为?? 的值仅依赖于?? <1>,… , ?? ,而不依赖于 ?? ,… , ?? <365>。)
?
吴恩达《深度学习》-课后测验-第五门课 序列模型(Sequence Models)-Week 1: Recurrent Neural Networks(第一周测验:循环神经网络)
标签:app ble likely ica code rem 情况下 激活 selected
原文地址:https://www.cnblogs.com/phoenixash/p/12236960.html