标签:info and pytho 结束 就是 自己的 upgrading 最新版本 目录
“人生苦短,我用python”。最近了解到一个很好的Spider框架——Scrapy,自己就按着官方文档装了一下,出了些问题,在这里记录一下,免得忘记。
Scrapy的安装是基于Twisted进行安装的,在Python3.8的环境中,并不像是网上许多教程所说的那样需要安装许多的插件,只需要安装好Twisted就够了。所以,为了确保一次安装成功,我们首先要安装Twisted。
下载Twisted网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
下拉找到如下内容:

按照自己的版本进行下载,注意,cp后为python的版本号,python3.8就是 cp38 ;32位win32,64位为win_amd64
下载成功后,win+R输入cmd.exe,进入到Twisted所在目录,使用 pip install 你自己的版本 命令进行安装。

安装结束后,在结尾处显示Successfully installed ...即安装成功。
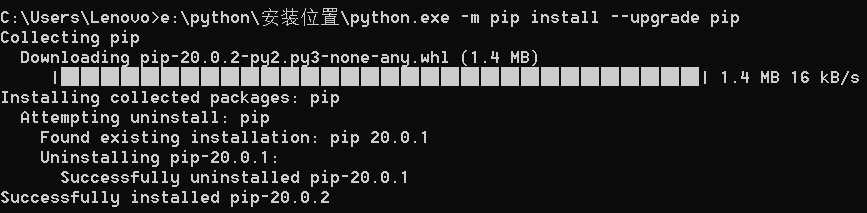
如果在安装时出现pip版本过低的问题,如 You are using pip version 20.0.1; however, version 20.0.2 is available. You should consider upgrading via the ‘e:\python\安装位置\python.exe -m pip install --upgrade pip‘ command. 则升级pip重新安装即可。升级pip的命令,按照提示命令进行即可,如 e:\python\安装位置\python.exe -m pip install --upgrade pip
安装后如下图所示:
安装Twisted结束后,使用命令 pip install scrapy 进行安装即可(默认安装最新版本)。
创建Scrapy项目--两种方法进行创建(以在visual studio code中为例,其他Windows终端中创建方法相同)
Scrapy项目结构目录如下:
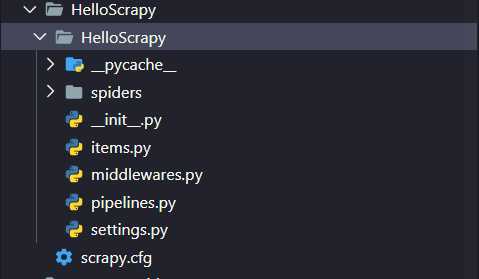
1、官方给出的创建的方法是,在项目目标位置进行创建 scrapy startproject 你的项目名字

进入创建的项目,然后创建你的代码py文件。创建.py文件命令 scrapy genspider .py文件名字 带爬取的网站网址

2、使用bat文件进行创建
创建.bat文件,填写如下代码:

在文件夹中点击运行,项目自动创建,以后在只需要更改 name= 后的内容即可。
运行目标项目.py文件
1、按照官方给出的方法
scrapy crawl 要运行的.py文件
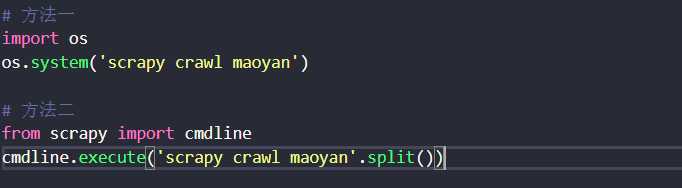
2、在二级HelloScrapy下创建runspider.py,填写如下代码:
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
框架的具体爬取流程正在学习中。。。。。。。。。。
标签:info and pytho 结束 就是 自己的 upgrading 最新版本 目录
原文地址:https://www.cnblogs.com/yandashan666/p/12236764.html