标签:顺序 聚集 没有 lib mysql tin 主键索引 inf 索引
Mysql是使用B+树作为索引的数据结构,Mysql有两种不同的数据存储引擎:MYISAM 和 INNODB,在Mysql5.5版本之前采用的是MYISAM,5.5之后采用的是INNODB
首先看看mysql是怎么保存数据的
在/var/lib/mysql这个目录下保存的是所有的数据库
使用MYISAM存储引擎的数据库有三个文件:
.frm 表的定义文件
.MYD 数据文件,所有的数据保存在这个文件中
.MYI 索引文件
在MYISAM存储引擎中,数据和索引的关系如下:
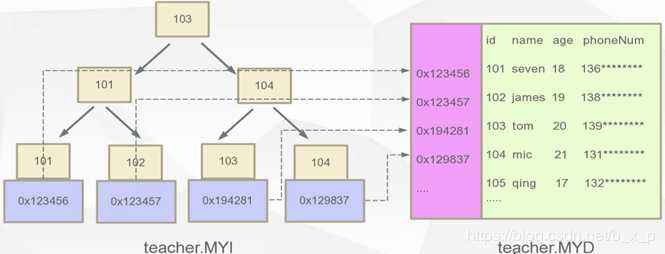
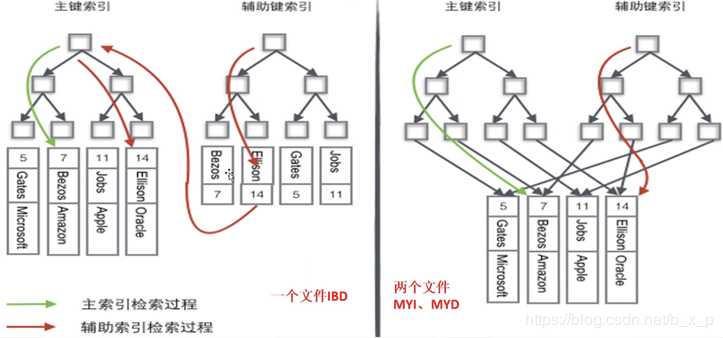
如果要查询id=101的数据,先根据MYI索引文件去找id=101的节点,通过这个节点的数据区拿到真正保存数据的磁盘地址,再通过这个地址从MYD数据文件中加载对应的记录
如果有多个索引,表现如下:
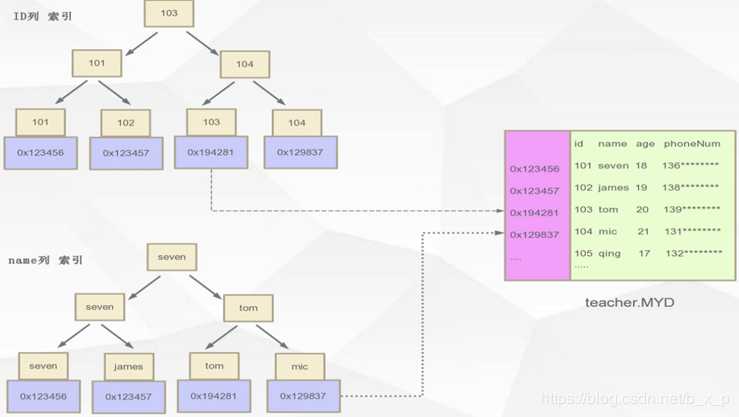
所以在MYISAM存储引擎中,主键索引和辅助索引是同级别的,没有主次之分。
Innodb存储引擎:
Innodb以主键索引来聚集和组织数据的存储,看下Innodb的数据库文件:
.frm 表的定义文件
.ibd 索引文件
没有专门的数据文件,数据都是在叶子节点中,innodb设计的初衷也是也为主键才是最主要的索引
首先看一下聚集索引的概念:数据表中行的数据的物理顺序和键值的逻辑顺序相同
在Innodb中,索引文件是这样的:
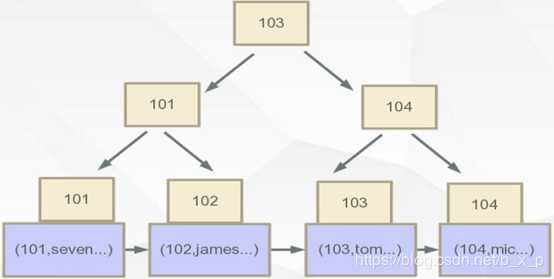
叶子节点的数据区保存的是真实的数据,再通过索引进行检索的时候,命中叶子节点,就可以直接从叶子节点中取出行数据
那么在Innodb中,辅助索引和主键索引是怎么表现形式呢?
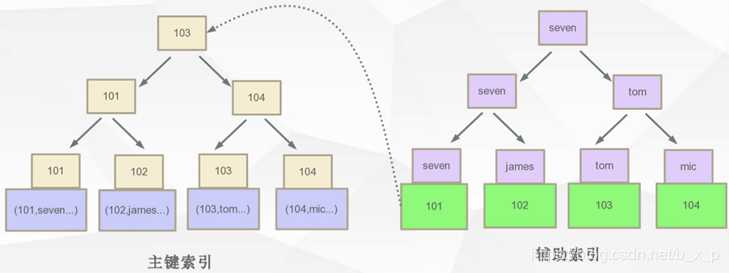
因为主键索引的叶子节点保存的是真正的数据,辅助索引的叶子节点的数据区保存的是主键索引关键字的值,所以如果按照辅助索引的字段去查询数据,执行的过程是
现在辅助索引中查询到主键id=101,再到主键索引中搜索id=101的数据,最终在主键索引的叶子节点中获取真正的数据,通过辅助索引进行检索,需要检索两次索引
两个不同的存储引擎查找数据的过程:
创建索引的几大原则:
1、列的离散型:
离散型的计算公式:count(distinct col):count(col),离散型越高,选择型越好。
标签:顺序 聚集 没有 lib mysql tin 主键索引 inf 索引
原文地址:https://www.cnblogs.com/wangflower/p/12237846.html