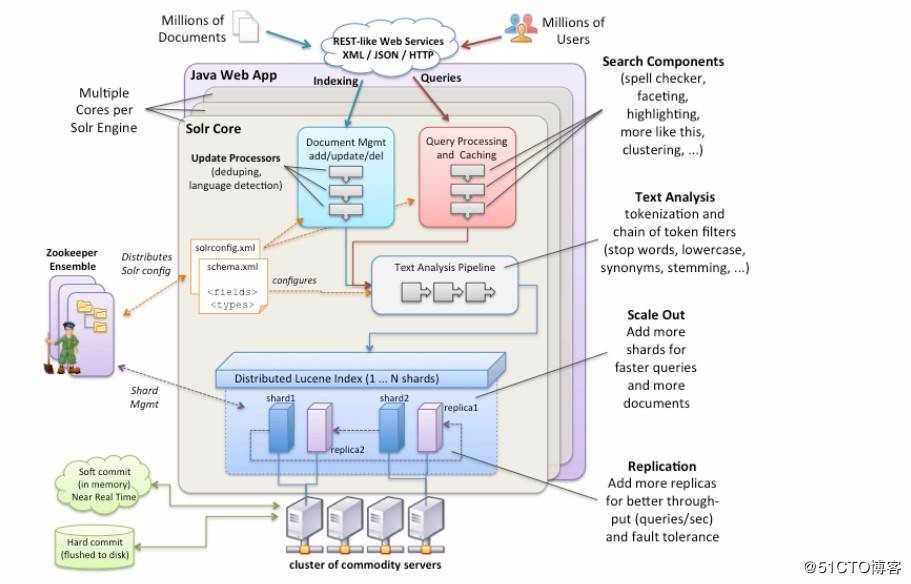
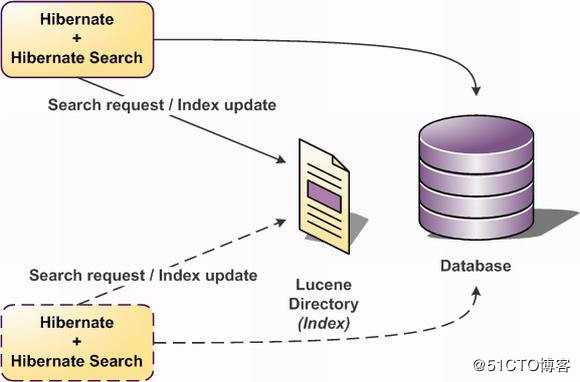
标签:ber json 调用 必须 com http 根据 高效 通过
Lucene、Solr、ElasticSearch、hibernate-search四部曲
原文地址:https://blog.51cto.com/13479739/2468679