标签:fileutil sts use 具体步骤 text 对象 add version mamicode
创建完索引之后,我们需要查询。
百度的查询接口及结果如图所示:
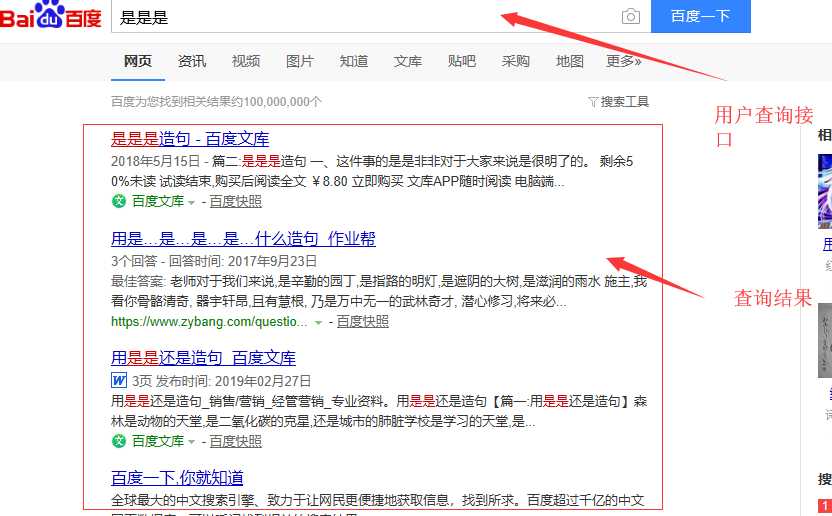
具体步骤已经在上个博客中写到,直接上代码:(由于是一个完整的程序,我把创建索引的代码也post上)
package come.me.lucene; import static org.junit.jupiter.api.Assertions.*; import java.io.File; import org.apache.commons.io.FileUtils; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.LongField; import org.apache.lucene.document.StoredField; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; import org.junit.jupiter.api.Test; public class FirstLucene { @Test public void testIndex() throws Exception{ // TODO Auto-generated method stub //创建索引 // 第一步:创建一个java工程,并导入jar包。 // 第二步:创建一个indexwriter对象。 // 1)指定索引库的存放位置Directory对象 // 2)指定一个分析器,对文档内容进行分析。 Directory directory =FSDirectory.open(new File("D:\\temp\\index"));//创建document对象 Analyzer analyzer=new StandardAnalyzer();//官方推荐标准分析器 IndexWriterConfig config=new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);//第一个变量为用的lucene版本号,第二个为分析器对象 IndexWriter indexwriter =new IndexWriter(directory,config); // 第三步:创建field对象,将field添加到document对象中。 File f=new File("C:\\Users\\lenovo\\Desktop\\searchsource\\searchsource"); File[] listFiles = f.listFiles(); for(File file: listFiles) {//遍历文件 //由于对文件的某些属性不需要分析例如大小路径,所以field有很多个实现类,可以选择是否储存,是否分析,是否索引 // 第四步:创建document对象。 Document document =new Document(); // 文件名字 String file_name = file.getName(); Field fileNameField=new TextField("fileName", file_name, Store.YES); // 文件大小 long file_size = FileUtils.sizeOf(file);//使用文件工具类获取文件大小 Field fileSizeFiled=new LongField("fileSize", file_size, Store.YES); // 文件路径 String file_path = file.getPath(); Field filePathField=new StoredField("filePath", file_path); // 文件内容 String file_content = FileUtils.readFileToString(file);//使用文件工具类获取文件内容 Field fileContentField =new TextField("fileContent", file_content, Store.YES); document.add(fileNameField); document.add(fileSizeFiled); document.add(filePathField); document.add(fileContentField); // 第五步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。 indexwriter.addDocument(document); } // 第六步:关闭IndexWriter对象。 indexwriter.close(); } @Test void testSearch() throws Exception { // 第一步:创建一个Directory对象,也就是索引库存放的位置。 Directory directory =FSDirectory.open(new File("D:\\temp\\index")); // 第二步:创建一个indexReader对象,需要指定Directory对象。 IndexReader indexreader=DirectoryReader.open(directory); // 第三步:创建一个indexsearcher对象,需要指定IndexReader对象 IndexSearcher indexsearcher=new IndexSearcher(indexreader); // 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。 Query query=new TermQuery(new Term("fileName","apache")); // 第五步:执行查询。 // 第六步:返回查询结果。遍历查询结果并输出。 TopDocs topDocs = indexsearcher.search(query, 2); ScoreDoc[] scoreDoc = topDocs.scoreDocs; for(ScoreDoc scoreDoc1:scoreDoc) { int doc= scoreDoc1.doc; Document doc2 = indexsearcher.doc(doc); //文件名称 System.out.println("文件名称"); String fileName=doc2.get("fileName"); System.out.println(fileName); //文件内容 System.out.println("文件内容"); String fileContent=doc2.get("fileContent"); System.out.println(fileContent); //文件路径 System.out.println("文件路径"); String filePath=doc2.get("filePath"); System.out.println(filePath); //文件大小 System.out.println("文件大小"); String fileSize=doc2.get("fileSize"); System.out.println(fileSize); System.out.println("-------------------"); } // 第七步:关闭IndexReader对象 indexreader.close(); } }
运行结果如图:
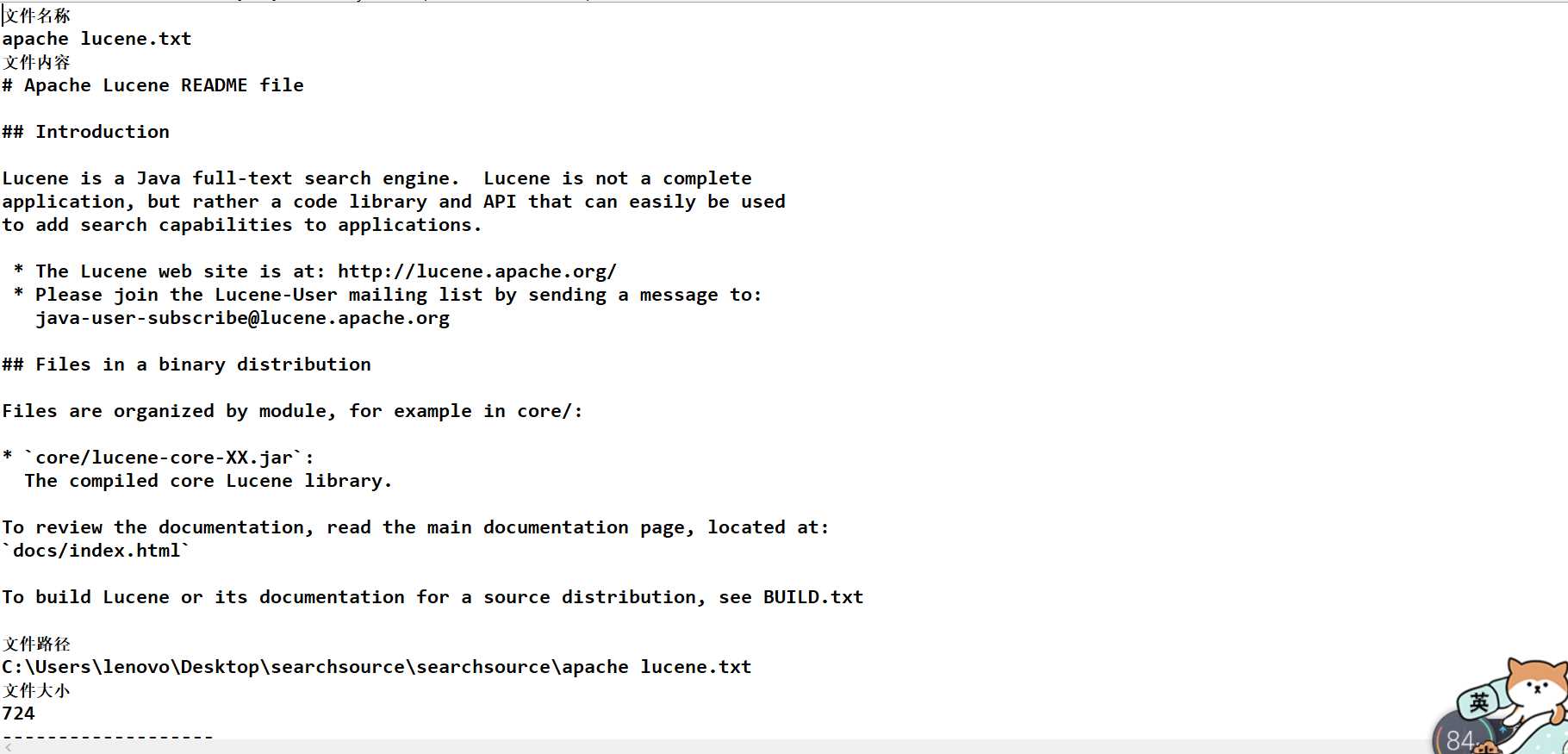

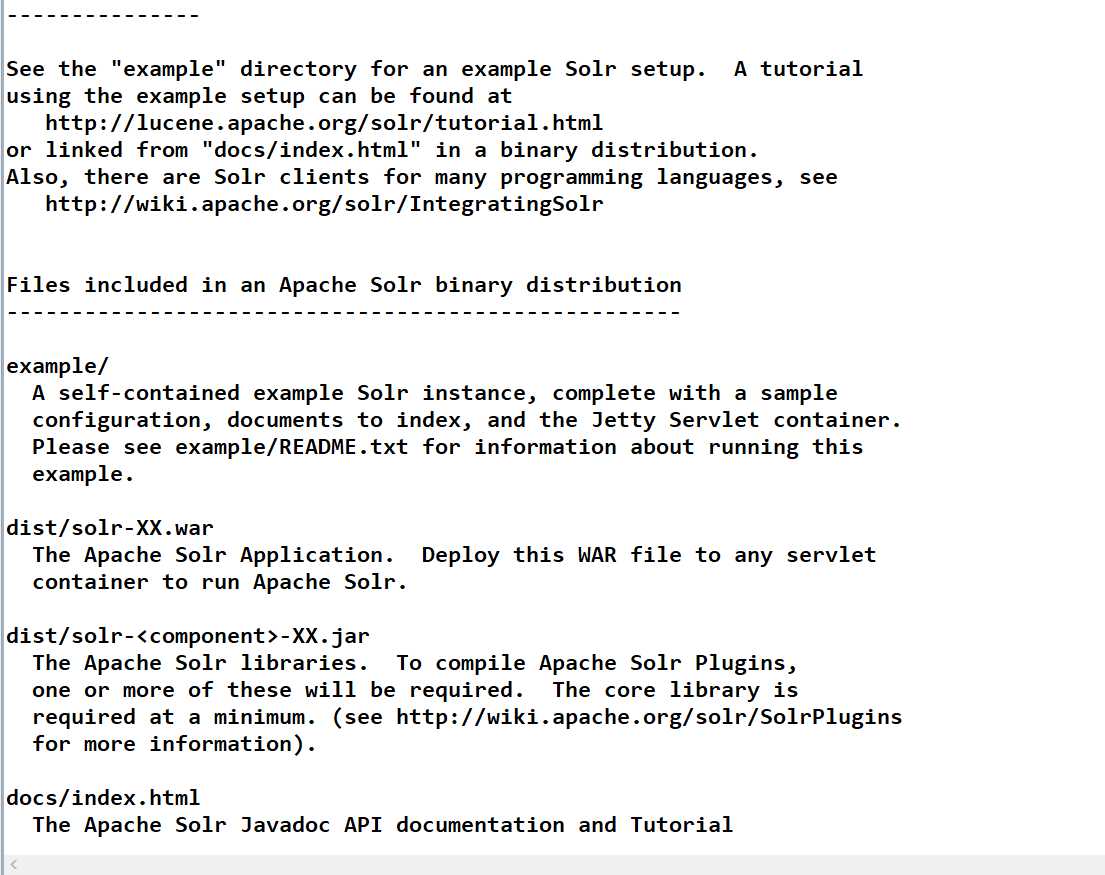
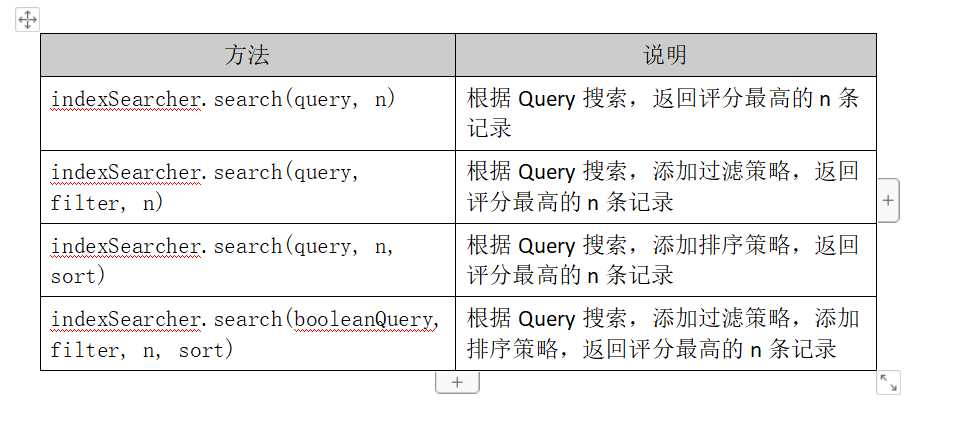
需要注意的是搜索方法有多种:
标签:fileutil sts use 具体步骤 text 对象 add version mamicode
原文地址:https://www.cnblogs.com/tkg1314/p/12249921.html