标签:ack exception 接受 接口 工作 src syn 数据量 foo
java在线程同步和互斥方面在语言和工具方面都提供了相应的支撑,与此同时,java还提供了一系列的并发容器和原子类,来使得并发编程更容易。
一。并发容器
(一)。同步容器
同步容器指的是容器本身使用synchronized关键字来同步访问,包括我们都知道的HashTable,也包括Vector和Stack。另外,也可以通过工具类Collections.synchronizedList(List<T> list)这个方法将线程不安全的ArrayList转成线程安全的包装类,其他的set,map等等,都有类似的包装类。
通常都任务同步容器的性能较差,但不足以导致问题,会导致问题的是对同步容易的迭代遍历。在迭代遍历的时候,依然需要对同步容器本身进行加锁才能保证线程安全。
1 List list = Collections.synchronizedList(new ArrayList()); 2 synchronized (list) { 3 Iterator i = list.iterator(); 4 while (i.hasNext()) 5 foo(i.next()); 6 }
(二)。并发容器
同步容器的线程安全的保证主要是通过对所有的访问路径添加synchronized保护,往往造成性能不佳,所以在java 1.5之后,提供了更多的性能比较优秀的容器,这里称之为并发容器。
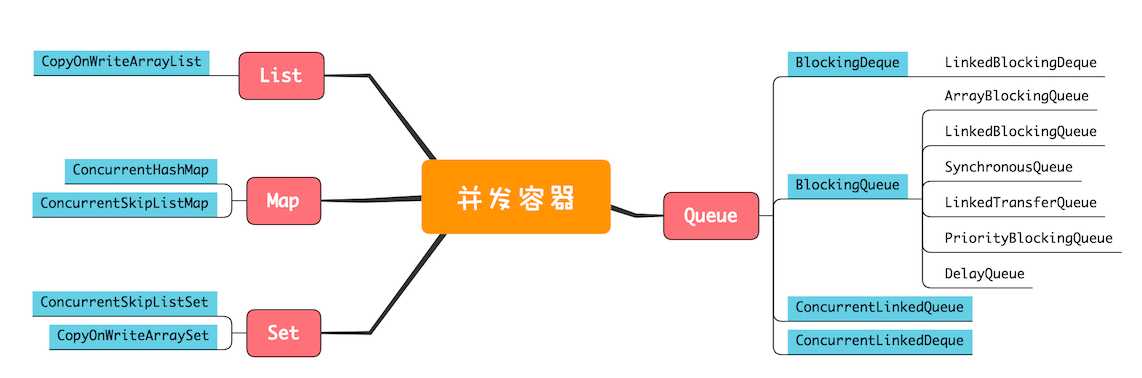
根据容器的类型,大致可以分为以上四类。
A。List
CopyOnWriteArrayList 主要体现了读写分离和最终一致的原则。即每次对CopyOnWriteArrayList 对象进行更改的话,都会新创建一个内部对象,而之前已经开始的读,还是基于之前的内部对象,之后的读在基于新的对象,会造成短暂的不一致。
如果要使用CopyOnWriteArrayList,务必保证这个业务场景中读的频率是写的频率的千百倍以上,否则效率比较差,其次就是能够接受短暂的不一致现象。
B。Map
Map 接口的两个实现是 ConcurrentHashMap 和 ConcurrentSkipListMap,它们从应用的角度来看,主要区别在于 ConcurrentHashMap 的 key 是无序的,而 ConcurrentSkipListMap 的 key 是有序的。
使用 ConcurrentHashMap 和 ConcurrentSkipListMap 需要注意的地方是,它们的 key 和 value 都不能为空,否则会抛出NullPointerException这个运行时异常。
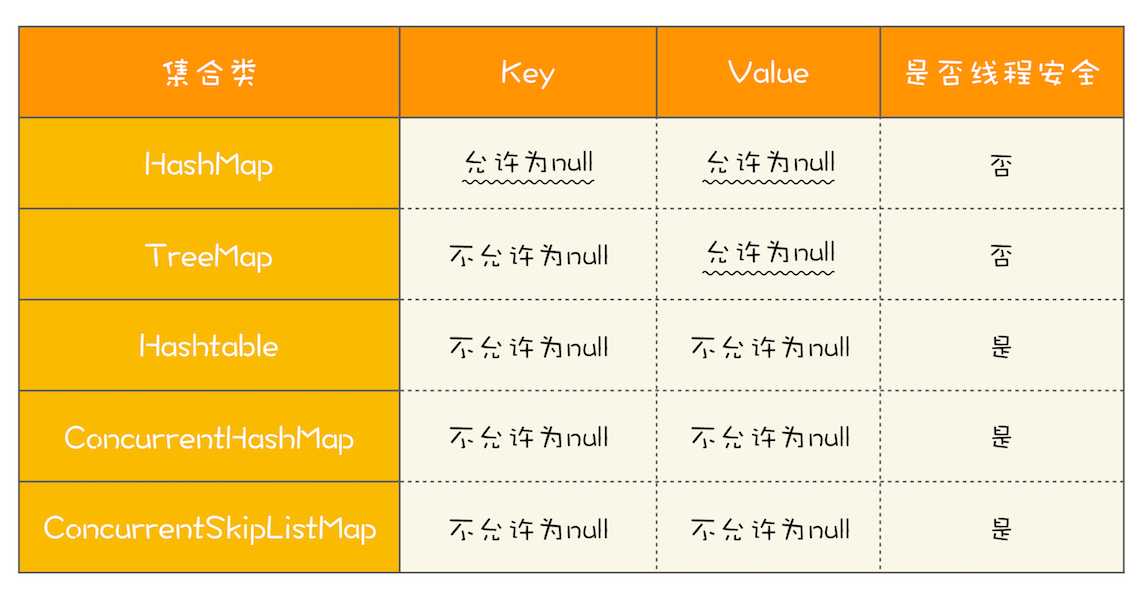
ConcurrentSkipListMap 的插入、删除、查询操作平均的时间复杂度是 O(log n),理论上和并发线程数没有关系,所以在并发度非常高的情况下,若你对 ConcurrentHashMap 的性能不满意,可以尝试一下 ConcurrentSkipListMap。
C。Set
Set 接口的两个实现是 CopyOnWriteArraySet 和 ConcurrentSkipListSet,使用场景可以参考前面讲述的 CopyOnWriteArrayList 和 ConcurrentSkipListMap。
D。Queue
Queue 并发容器可以从以下两个维度来分类:
* 一个维度是阻塞与非阻塞,所谓阻塞指的是当队列已满时,入队操作阻塞;当队列已空时,出队操作阻塞。Java 并发包里阻塞队列都用 Blocking 关键字标识。
* 一个维度是单端与双端,单端指的是只能队尾入队,队首出队;而双端指的是队首队尾皆可入队出队。单端队列使用 Queue 标识,双端队列使用 Deque 标识。
a.单端阻塞队列,ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue。LinkedTransferQueue 融合 LinkedBlockingQueue 和 SynchronousQueue 的功能,性能比 LinkedBlockingQueue 更好;PriorityBlockingQueue 支持按照优先级出队;DelayQueue 支持延时出队。
b.双端阻塞队列,LinkedBlockingDeque。
c.单端非阻塞队列,ConcurrentLinkedQueue。
d.双端非阻塞队列,ConcurrentLinkedDeque。
使用队列时,需要格外注意队列是否支持有界(所谓有界指的是内部的队列是否有容量限制)。实际工作中,一般都不建议使用无界的队列,因为数据量大了之后很容易导致 OOM。上面提到的这些 Queue 中,只有 ArrayBlockingQueue 和 LinkedBlockingQueue 是支持有界的,所以在使用其他无界队列时,一定要充分考虑是否存在导致 OOM 的隐患。
(三)。性能比较
下图对比了都具有线程安全特性的List的三个实现的性能,可以看出CopyOnWriteArrayList在遍历操作的时候性能最好,在读操作上与其他两个相差无几,而写操作非常差。

二。原子类
对于简单的原子性问题,还有一种无锁方案。Java SDK 并发包将这种无锁方案封装提炼之后,实现了一系列的原子类。无锁方案相对互斥锁方案,最大的好处就是性能。互斥锁方案为了保证互斥性,需要执行加锁、解锁操作,而加锁、解锁操作本身就消耗性能;同时拿不到锁的线程还会进入阻塞状态,进而触发线程切换,线程切换对性能的消耗也很大。 相比之下,无锁方案则完全没有加锁、解锁的性能消耗,同时还能保证互斥性,既解决了问题,又没有带来新的问题,可谓绝佳方案。
原子类性能高的秘密很简单,硬件支持而已。CPU 为了解决并发问题,提供了 CAS 指令(CAS,全称是 Compare And Swap,即“比较并交换”)。CAS 指令包含 3 个参数:共享变量的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B 时,才能将内存中地址 A 处的值更新为新值 C。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
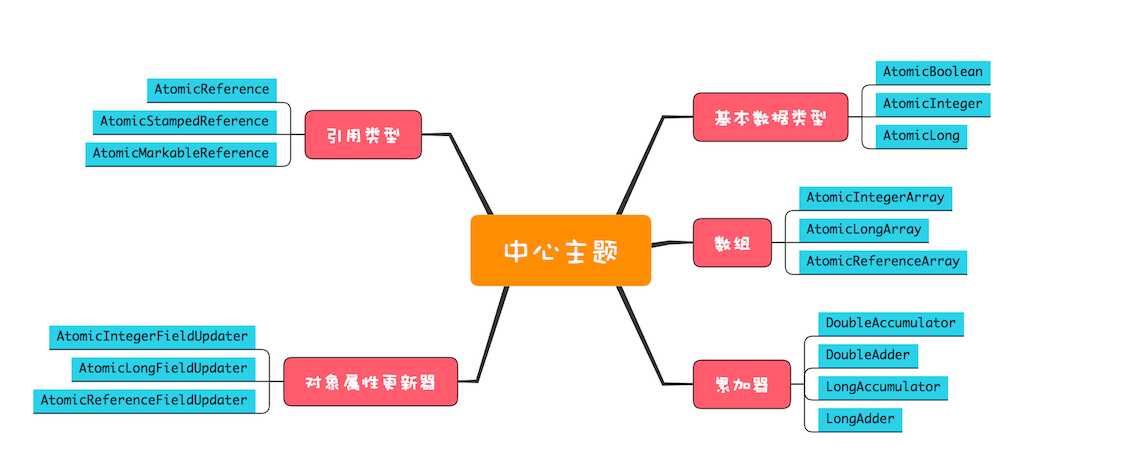
Java SDK 并发包里的原子类很丰富,可以将它们分为五个类别:原子化的基本数据类型、原子化的对象引用类型、原子化数组、原子化对象属性更新器和原子化的累加器。
(一)原子化的基本数据类型,相关实现有 AtomicBoolean、AtomicInteger 和 AtomicLong。
(二)原子化的对象引用类型,相关实现有 AtomicReference、AtomicStampedReference 和 AtomicMarkableReference,利用它们可以实现对象引用的原子化更新。AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题。
(三)原子化数组,相关实现有 AtomicIntegerArray、AtomicLongArray 和 AtomicReferenceArray,利用这些原子类,可以原子化地更新数组里面的每一个元素。
(四)原子化对象属性更新器,相关实现有 AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 和 AtomicReferenceFieldUpdater,利用它们可以原子化地更新对象的属性,这三个方法都是利用反射机制实现的。
(五)原子化的累加器,DoubleAccumulator、DoubleAdder、LongAccumulator 和 LongAdder,这四个类仅仅用来执行累加操作,相比原子化的基本数据类型,速度更快,但是不支持 compareAndSet() 方法。
无锁方案相对于互斥锁方案,优点非常多,首先性能好,其次是基本不会出现死锁问题(但可能出现饥饿和活锁问题,因为自旋会反复重试)。所有原子类的方法都是针对一个共享变量的,如果你需要解决多个变量的原子性问题,建议还是使用互斥锁方案。
标签:ack exception 接受 接口 工作 src syn 数据量 foo
原文地址:https://www.cnblogs.com/029zz010buct/p/12182098.html