标签:日志文件 说明 memory 推荐 span erro file 策略 时间
我们安装成功之后就会有这个配置文件,但是我们一般都不推荐直接使用出厂的配置文件,而是单独拷贝一份使用,以避免我们因为配置错误而带来不必要的麻烦。
如图我单独拷贝了一份在根目录下面的文件夹:

设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列+已经完成三次握手队列。
在这里三次握手队列我参考另一篇博文:https://blog.csdn.net/ityouknow/article/details/86710128
在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值,所以需要确认增大somaxconn和tcp_max_syn_backlog两个值来达到想要的效果。


单位为秒,如果设置成0,则不会进行keepalive检测,建议设置成60

分为四种:debug,verbose,notice,warning。从上到下日志级别越来越高。
debug通常用于开发/测试,提供的非常详细
在通过测试之后生产上线的时候通常使用notice或warning

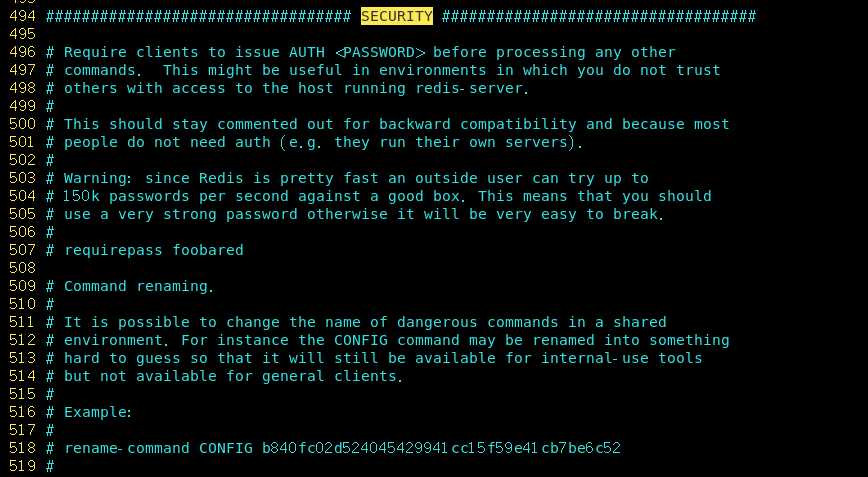
我们可以看到在配置文件中,这些全部被默认注释掉了。
那我们查看,修改密码则需要连接redis服务器进行设置:
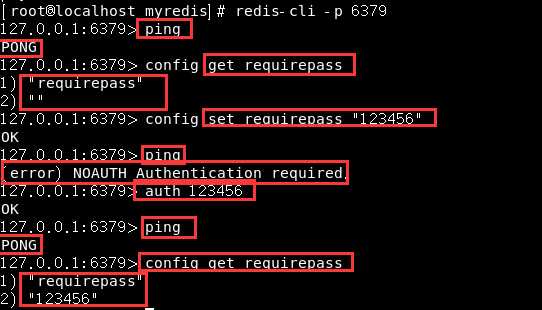
如上图:一开始可以ping通,然后我们查看requirepass发现是空字符串,然后我们设置requirepass为“123456”,再去ping就发现ping不通了,这是因为只要我们一设置安全验证,它就立刻生效,在我们输入任何命令前都需要通过验证,即键入auth 123456来通过验证。
Maxclients 最大客户连接数
Maxmemory 最大缓存
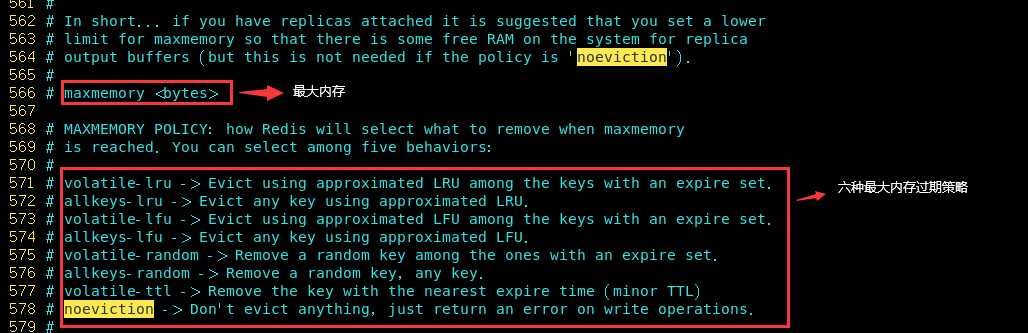
共分为六种:
(1)volatile-lru:使用LRU算法移除key,只对设置了过期时间的键
(2)allkeys-lru:使用LRU算法移除key
(3)volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
(4)allkeys-random:移除随机的key
(5)volatile-ttl:移除哪些TTL值最小的key,即那些最近要过期的key
(6)noeviction:不进行移除。针对写操作,只是返回错误信息 * 一般只在学习中设置它,实际生产中在1~5里面选一种
Maxmemory-samples :设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个
什么是redis持久化?用两个关键词来概括,就是RDB和AOF
RDB:Redis DataBase
AOF:Append Only File
那么RDB具体有什么用?
答:在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
Fork:Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
RDB保存的是dump.rdb文件
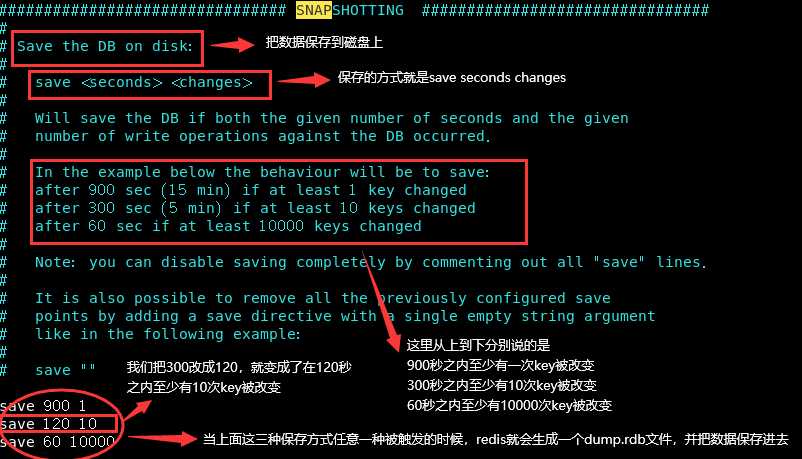

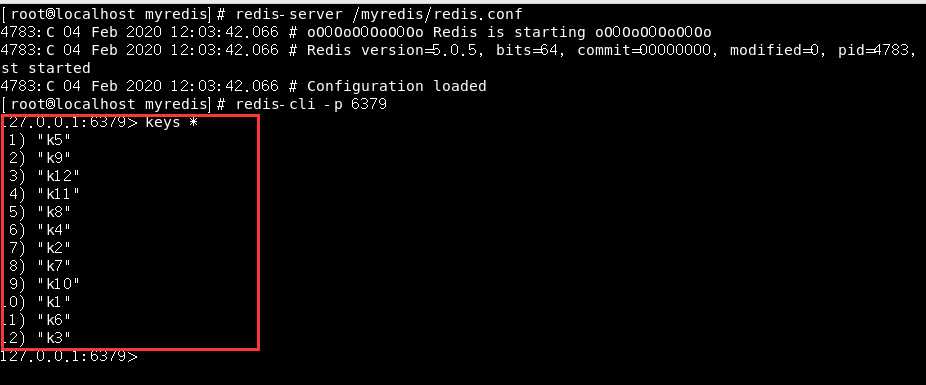
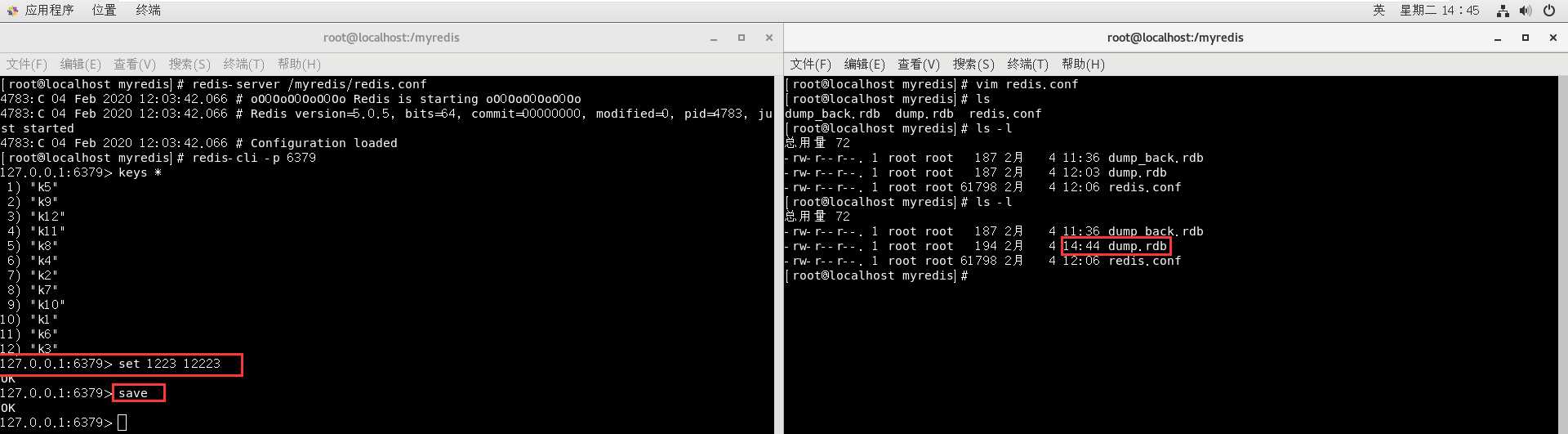
我们为了方便解释,先把这个dump.rdb删掉,然后开两个窗口

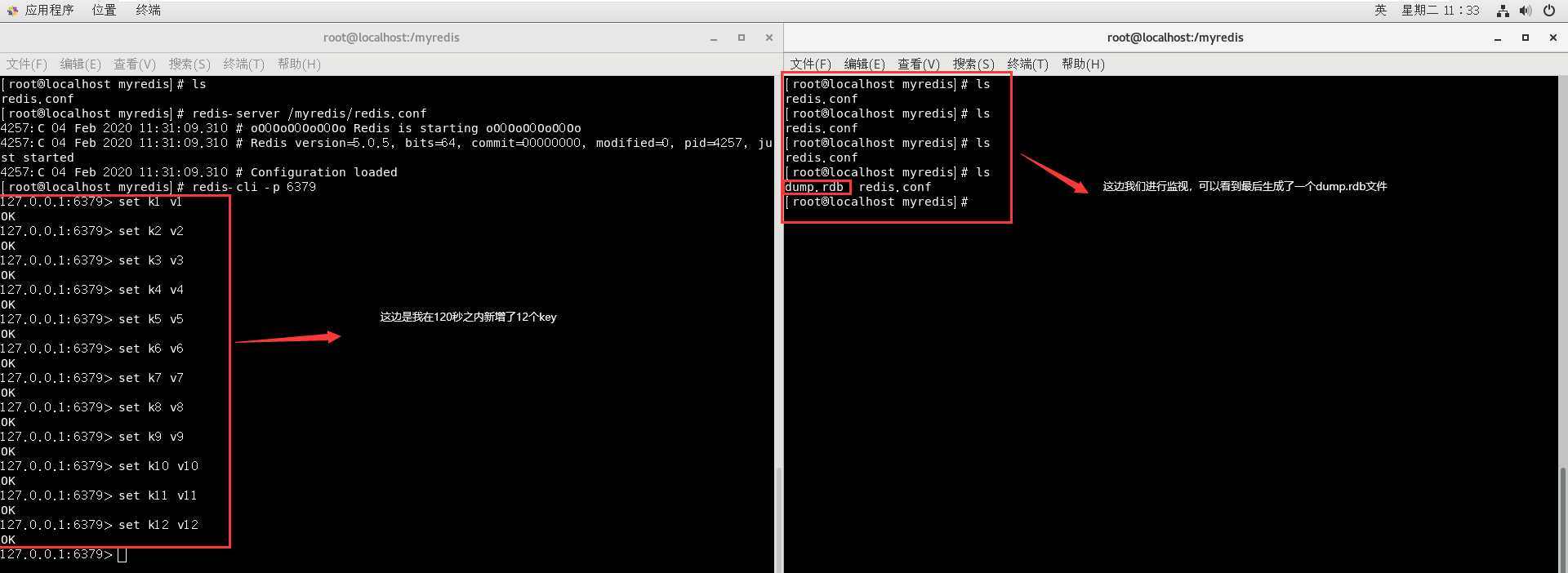
然后我们备份一份dump.rdb文件并命名为dump_back.rdb文件:

之后我们在redis中进行清库操作,然后关闭连接:

那么此时,我们的dump.rdb文件应该记录的是什么?

我们重新进入redis查看:

可以看到 ,我们之前新增的12个key已经没有了,这是因为我们在执行flushall指令的时候它会立即生成一个新的dump.rdb文件并把原来的覆盖掉,
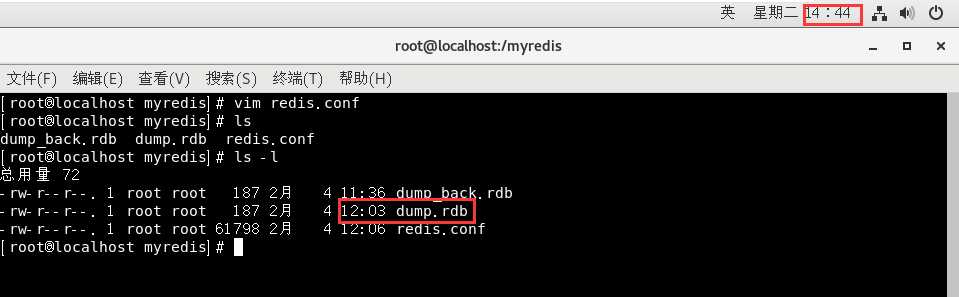
不过这时候我们之前备份的dump_back.rdb文件就可以派上用场了:
我们先把这次的dump.rdb文件删掉,然后把之前的备份文件复制一份并命名为dump.rdb:
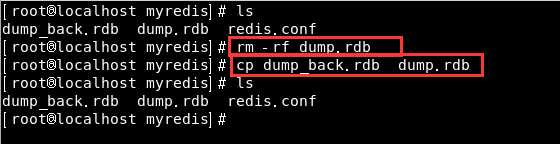
然后我们再进入redis查看,就可以看到之前 新增的12个key了:
RDB是整个内存压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件。
如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数就可以了。
如果我们传入的参数很重要,要求它立即备份,也可以再redis中键入save来完成手动备份
stop-writes-on-bgsave-error yes
这一行说的是当后台保存数据时错误,那么禁止继续写入数据,当然如果配置成no,表示你不在乎数据不一致或者有其他的收端发现和控制。

rdbcompression :对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能

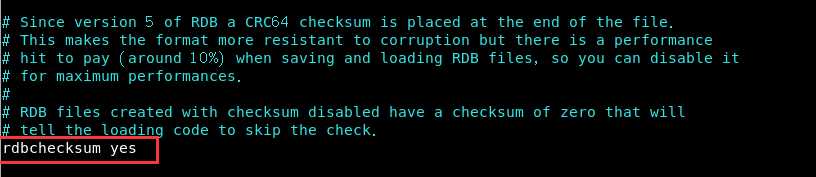
rdbchecksum:在存储快照后,还可以让rdis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
总结一下:
如何触发RDB快照:
1、配置文件中默认的快照配置-冷拷贝后重新使用 可以cp dump.rdb dump_back.rdb
2、执行save命令或bgsave:
save:save时只管保存,其他不管,一律阻塞
bgsave:redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。可以通过lastsave命令获取最后一次成功执行快照的时间。
3、执行flushall命令,也会产生dump.rdb文件,单里面是空的,无意义
如何恢复:
将备份文件(dump.rbd)移动到redis的启动目录(你在哪个目录下启动的redis,哪个目录就是你的启动目录)下并启动服务即可
config get dir 获取目录
1、适合大规模的数据恢复
2、对数据的完整性和一致性要求不高
1、在一定时间间隔做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改
2、Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
如何停止:
动态所有停止RDB保存规则的方法:redis-cli config set save “”
AOF是什么:以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
我们为了方便解释,先复制一个redis.conf 并命名为redis_aof.conf,然后把所有的rdb文件全部删掉:
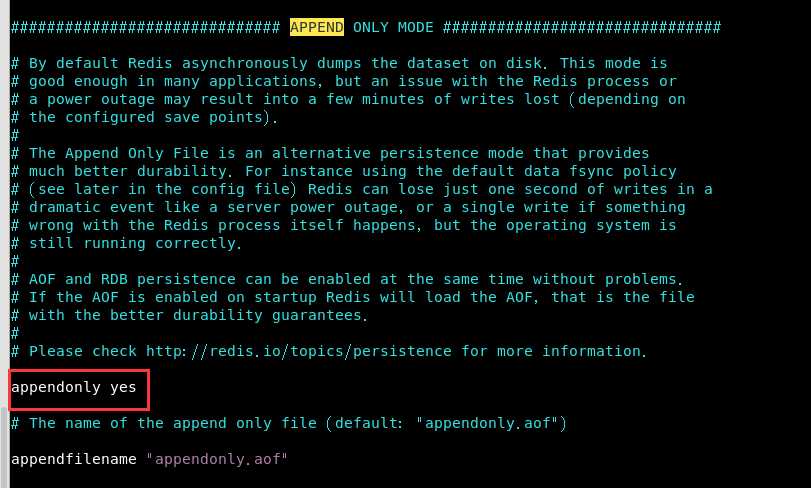
然后把redis_aof.conf里的appendonly 那一项改为yes(默认是no)
然后我们在左边的窗口启动redis_aof.conf:

然后我们会发现我们的目录里多出来一个appendonly.aof文件:

我们在redis中新增四个key:
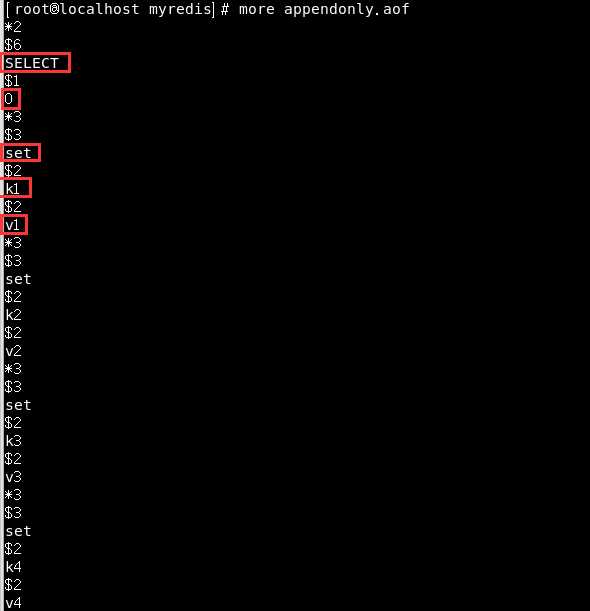
然后我们可以在appendonly.aof文件中可以看到它原模原样记录了我们的写动作(甚至我们在哪个库都记录下来了):
然后我们执行flushall指令:

我们会发现appendonly.aof文件中也把flushall这个指令记录下来了:

可以看到现在我们的库里面是空的:

然后我们把appendonly.aof文件里面的那行flushall删掉(实际生产中不允许直接修改appendonly.aof文件):

然后我们重新启动redis:
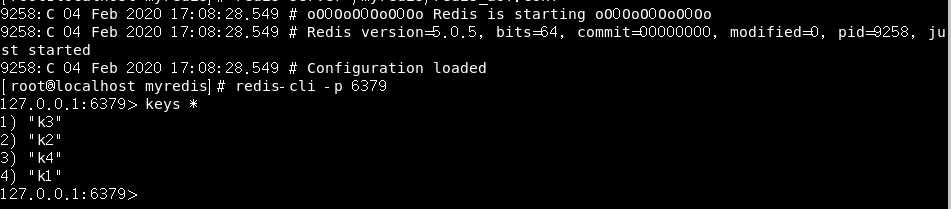
可以看到,我们的数据又恢复了。
第二个问题,如果dump.rdb和appendonly.aof文件共存,那么启动的是谁?
我们执行一个shutdown命令,它会自动生成一个dump.rdb文件:
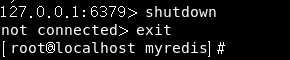

然后我们给appendonly.aof文件搞破坏:
我们键入一大堆无用字符,并保存:
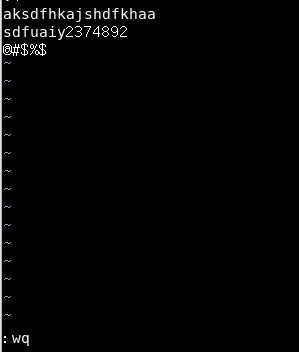
那么现在这个文件相当于被损坏掉了。
那么我们再启动redis的时候,如果能够正常启动,说明它找的是dump.rdb文件,如果不能正常启动,那说明它找的是aof文件:

如上图,我们可以看到进程并没有被正常启动,说明它是先识别aof文件的,那么我们把aof文件删掉,只保留rdb文件,他就应该能正常启动了,我们来试一下:


果然可以正常启动,这也再次证明redis启动的时候识别的是aof文件。
那如果不删除aof,怎么修复呢?
我们要用到src目录下的redis-check-aof文件:
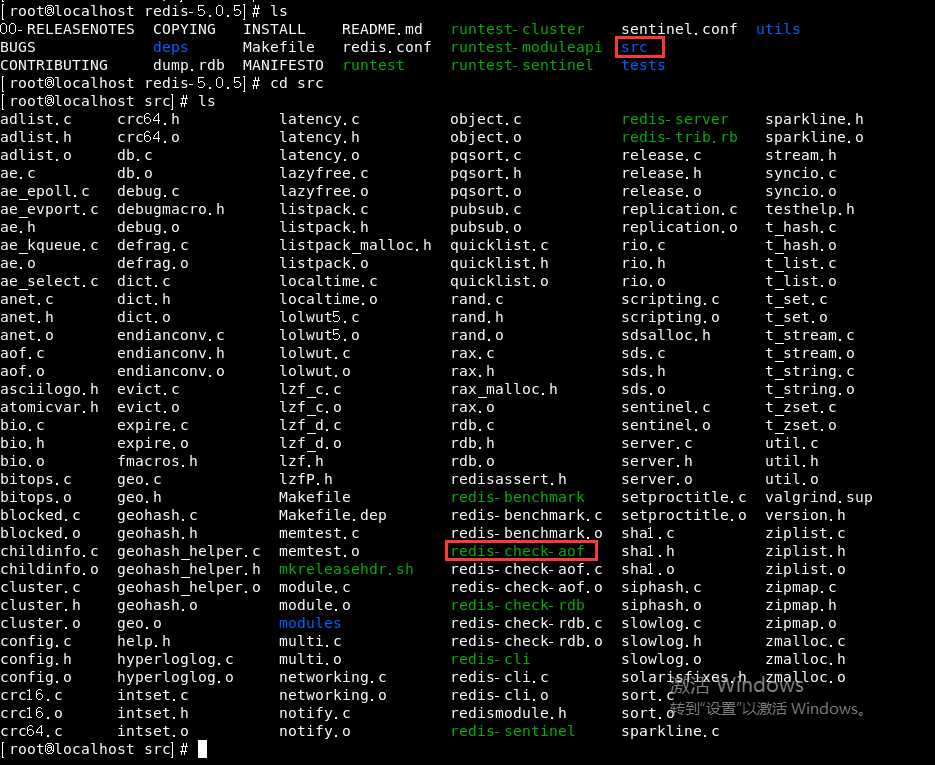
我们把它复制一份到我的启动目录下,然后执行如下操作:
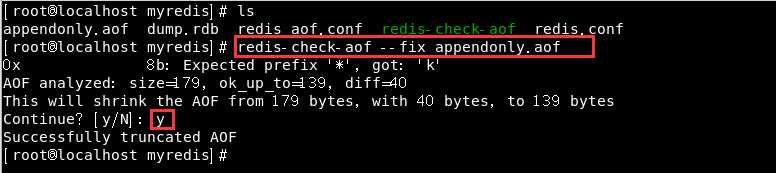
然后我们就可以正常启动redis了:
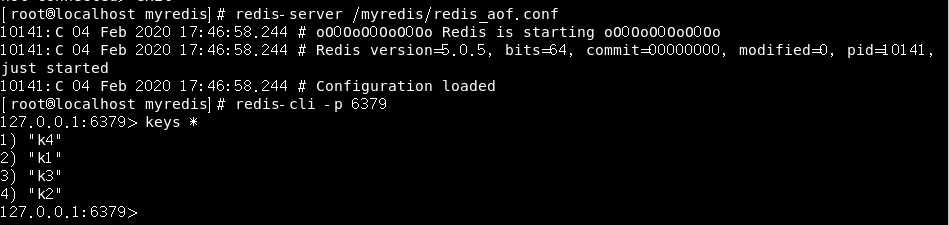
------------------------------------------------------------------未完待续---------------------------------------------------------
标签:日志文件 说明 memory 推荐 span erro file 策略 时间
原文地址:https://www.cnblogs.com/wanghaoyu666/p/12256502.html