标签:二进制 loader close 路径 识别 style 解压 压缩 文件内容
MNIST数据集是入门机器学习/模式识别的最经典数据集之一。最早于1998年Yan Lecun在论文:
中提出。经典的LeNet-5 CNN网络也是在该论文中提出的。
数据集包含了0-9共10类手写数字图片,每张图片都做了尺寸归一化,都是28x28大小的灰度图。每张图片中像素值大小在0-255之间,其中0是黑色背景,255是白色前景。如下图所示:

MNIST共包含70000张手写数字图片,其中有60000张用作训练集,10000张用作测试集。原始数据集可在MNIST官网下载。
下载之后得到4个压缩文件:
train-images-idx3-ubyte.gz #60000张训练集图片 train-labels-idx1-ubyte.gz #60000张训练集图片对应的标签 t10k-images-idx3-ubyte.gz #10000张测试集图片 t10k-labels-idx1-ubyte.gz #10000张测试集图片对应的标签
将其解压,得到:
train-images-idx3-ubyte train-labels-idx1-ubyte t10k-images-idx3-ubyte t10k-labels-idx1-ubyte
解压得到的四个文件都是二进制格式,我们如何获取其中的信息呢?这得首先了解MNIST二进制文件的存储格式(官网底部有介绍),以训练集图像文件train-images-idx3-ubyte为例:
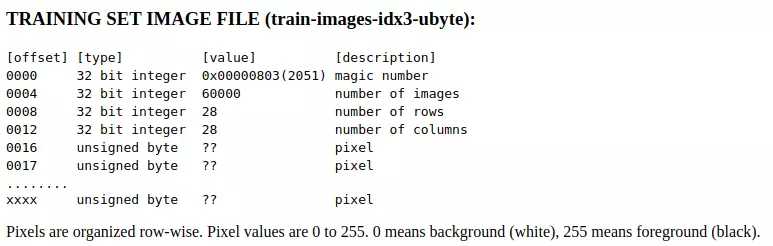
图像文件的
因为train-images-idx3-ubyte文件总共包含了60000张图片数据,按照以上的存储方式,我们算一下该文件的大小:
train-images-idx3-ubyte文件的属性: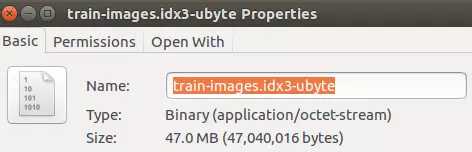
文件实际大小和我们计算的结果一致。
类似地,我们查看训练集标签文件train-labels-idx1-ubyte的存储格式:
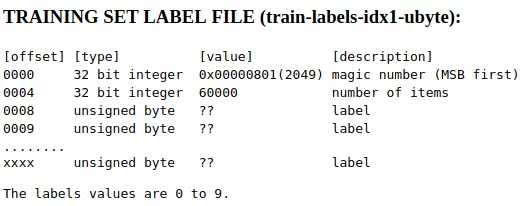
和图像文件类似:
计算一下训练集标签文件train-labels-idx1-ubyte的文件大小:
与该文件实际的大小一致:
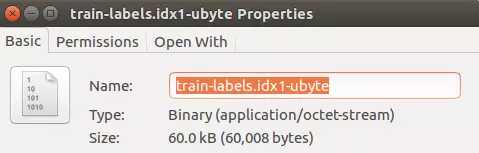
另外两个文件,即测试集图像文件、测试集标签文件的存储方式和训练图像文件、训练标签文件相似,只是图像数量由60000变为10000。
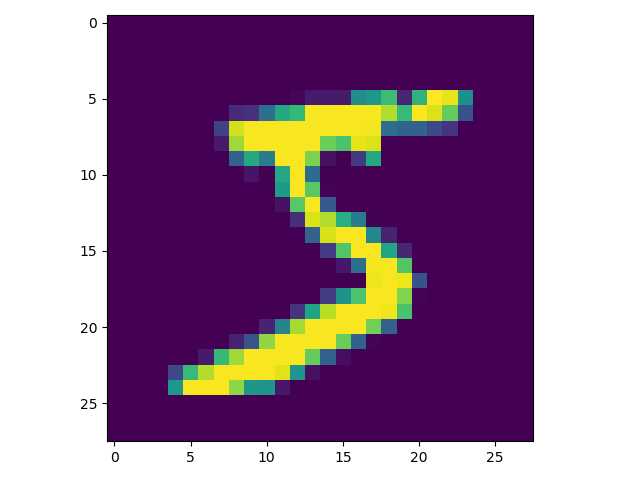
train-images-idx3-ubyte为例:import numpy as np import matplotlib.pyplot as plt ‘‘‘试验transpose() def back (a,b): return a,b if __name__ == ‘__main__‘: a = np.array([[1,2,3],[11,12,13],[21,22,23]]) print(a) b = np.array([[31,32,33],[41,42,43],[51,52,53]]) print(b) a, b = transpose(back(a,b)) #a, b = back(a, b) print(a) print(b) ‘‘‘ # 数据加载器基类 class Loader(object): def __init__(self, path, count): ‘‘‘ 初始化加载器 path: 数据文件路径 count: 文件中的样本个数 ‘‘‘ self.path = path self.count = count def get_file_content(self): ‘‘‘ 读取文件内容 ‘‘‘ f = open(self.path, ‘rb‘) content = f.read() f.close() return content def to_int(self, byte): ‘‘‘ 将unsigned byte字符转换为整数 ‘‘‘ #print(byte) #return struct.unpack(‘B‘, byte)[0] return byte # 图像数据加载器 class ImageLoader(Loader): def get_picture(self, content, index): ‘‘‘ 内部函数,从文件中获取图像 ‘‘‘ start = index * 28 * 28 + 16 picture = [] for i in range(28): picture.append([]) for j in range(28): picture[i].append( self.to_int(content[start + i * 28 + j])) return picture def get_one_sample(self, picture): ‘‘‘ 内部函数,将图像转化为样本的输入向量 ‘‘‘ sample = [] for i in range(28): for j in range(28): sample.append(picture[i][j]) return sample def load(self): ‘‘‘ 加载数据文件,获得全部样本的输入向量 ‘‘‘ content = self.get_file_content() data_set = [] for index in range(self.count): data_set.append( self.get_one_sample( self.get_picture(content, index))) return data_set # 标签数据加载器 class LabelLoader(Loader): def load(self): ‘‘‘ 加载数据文件,获得全部样本的标签向量 ‘‘‘ content = self.get_file_content() labels = [] for index in range(self.count): labels.append(self.norm(content[index + 8])) return labels def norm(self, label): ‘‘‘ 内部函数,将一个值转换为10维标签向量 ‘‘‘ label_vec = [] label_value = self.to_int(label) for i in range(10): if i == label_value: label_vec.append(0.9) else: label_vec.append(0.1) return label_vec def get_training_data_set(): ‘‘‘ 获得训练数据集 ‘‘‘ image_loader = ImageLoader(‘train-images.idx3-ubyte‘, 60000) label_loader = LabelLoader(‘train-labels.idx1-ubyte‘, 60000) return image_loader.load(), label_loader.load() def get_test_data_set(): ‘‘‘ 获得测试数据集 ‘‘‘ image_loader = ImageLoader(‘t10k-images.idx3-ubyte‘, 10000) label_loader = LabelLoader(‘t10k-labels.idx1-ubyte‘, 10000) return image_loader.load(), label_loader.load() if __name__ == ‘__main__‘: train_data_set, train_labels = get_training_data_set() line = np.array(train_data_set[0]) img = line.reshape((28,28)) plt.imshow(img) plt.show()
输出图片如下:
参考:
标签:二进制 loader close 路径 识别 style 解压 压缩 文件内容
原文地址:https://www.cnblogs.com/ratels/p/12262241.html