标签:png 函数 爬取小说 port append 阅读 imp regex random
# 爬取小说:唐朝小闲人
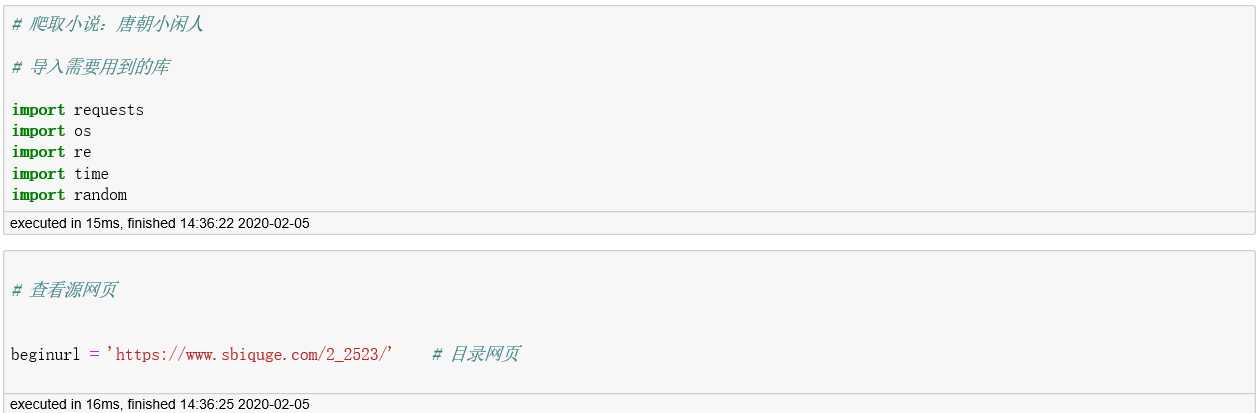
# 导入需要用到的库
import requests
import os
import re
import time
import random
# 查看源网页
beginurl = ‘https://www.sbiquge.com/2_2523/‘ # 目录网页
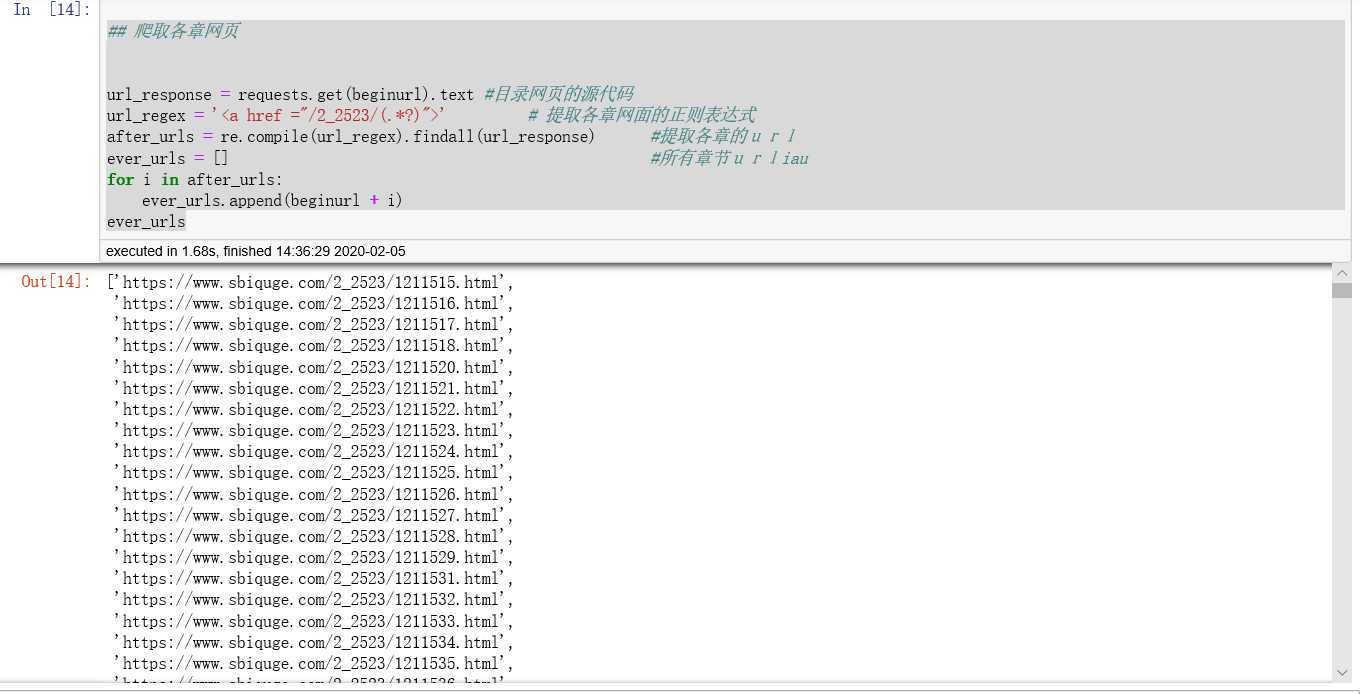
## 爬取各章网页
url_response = requests.get(beginurl).text #目录网页的源代码
url_regex = ‘<a href ="/2_2523/(.*?)">‘ # 提取各章网面的正则表达式
after_urls = re.compile(url_regex).findall(url_response) #提取各章的url
ever_urls = [] #所有章节url
for i in after_urls:
ever_urls.append(beginurl + i)
ever_urls
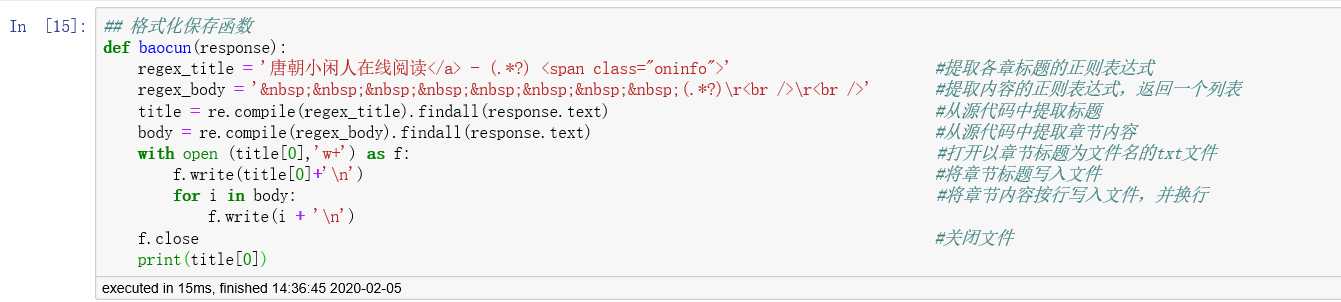
## 格式化保存函数
def baocun(response):
regex_title = ‘唐朝小闲人在线阅读</a> - (.*?) <span class="oninfo">‘
regex_body = ‘ (.*?)\r<br />\r<br />‘
title = re.compile(regex_title).findall(response.text)
body = re.compile(regex_body).findall(response.text)
with open (title[0],‘w+‘) as f:
f.write(title[0]+‘\n‘)
for i in body:
f.write(i + ‘\n‘)
f.close
print(title[0])
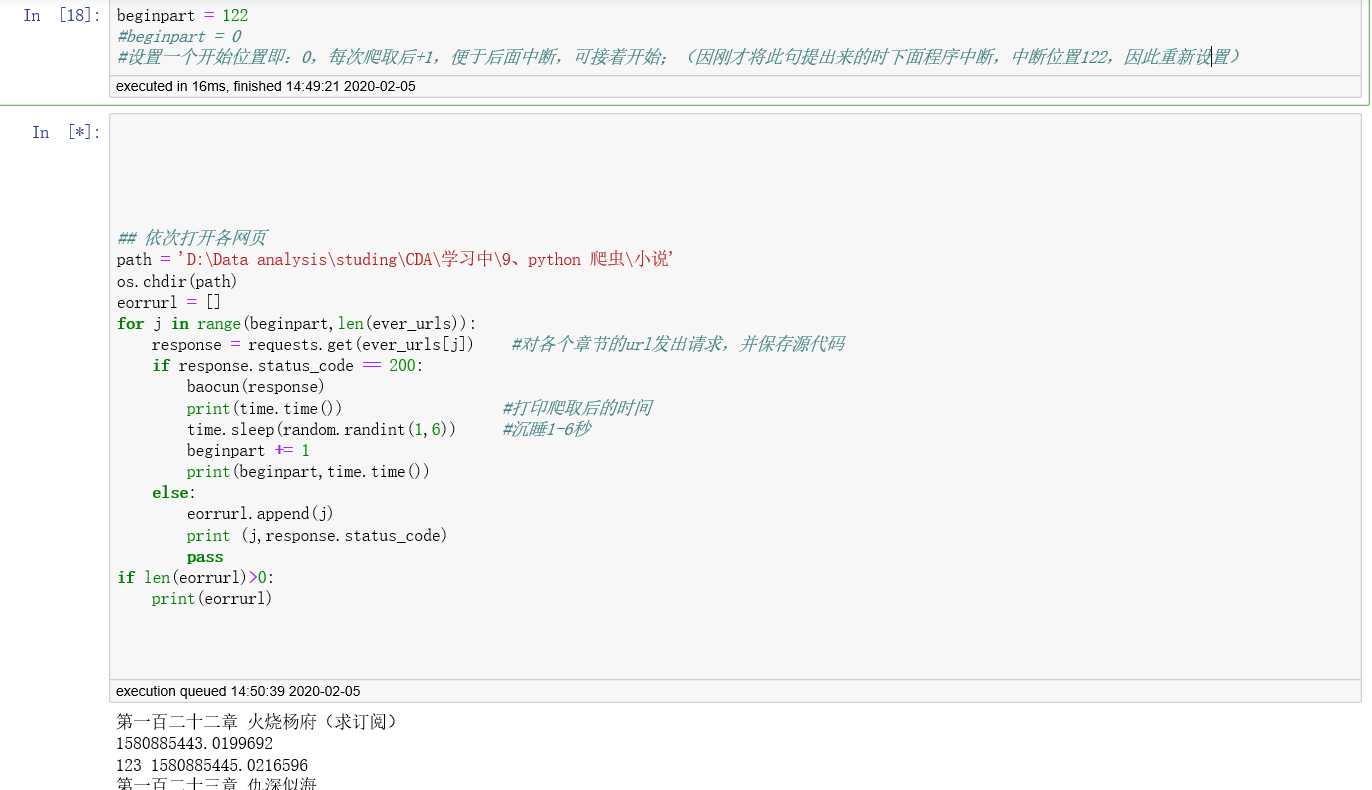
完成情况如下:
标签:png 函数 爬取小说 port append 阅读 imp regex random
原文地址:https://www.cnblogs.com/xuezhongdelang/p/12263838.html