标签:src eve col close 解析 mamicode continue ash append
前些日子学习了一些爬虫知识,鉴于时间较短,就只看了静态网页爬虫内容,而有关scrapy爬虫框架将在后续继续探索。
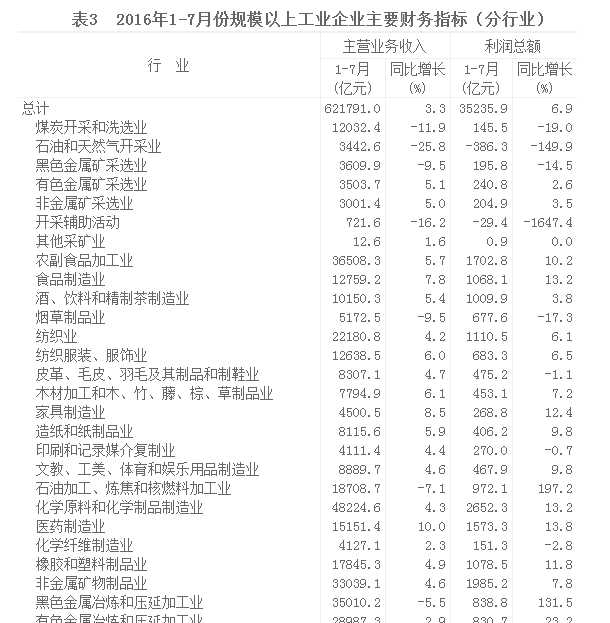
以下以重庆市统计局官网某页面爬取为例(http://tjj.cq.gov.cn/tjsj/sjjd/201608/t20160829_434744.htm):

1 import requests 2 from bs4 import BeautifulSoup 3 4 headers = {‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36‘} 5 url = ‘http://tjj.cq.gov.cn/tjsj/sjjd/201608/t20160829_434744.htm‘ 6 res = requests.get(url, headers=headers) 7 res.encoding = res.apparent_encoding 8 soup = BeautifulSoup(res.text, ‘html.parser‘) 9 trs = soup.find_all(‘table‘)[2].find_all(‘tr‘) 10 # print(trs) 11 data = [] 12 for tr in trs: 13 info = [] 14 tds = tr.find_all(‘td‘) 15 if(len(tds) ==5 ): 16 for td in tds: 17 info.append(td.text.replace(‘\u3000‘, ‘‘)) 18 print(info) 19 else: 20 continue 21 data.append(info)
1 import requests 2 from bs4 import BeautifulSoup
1 headers = {‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36‘} 2 url = ‘http://tjj.cq.gov.cn/tjsj/sjjd/201608/t20160829_434744.htm‘ 3 res = requests.get(url, headers=headers) 4 res.encoding = res.apparent_encoding
之前准备工作中,已经对网页源代码有了一定的分析。接下来,直接利用BeautifulSoup库完成网页解析。
1 soup = BeautifulSoup(res.text, ‘html.parser‘) 2 trs = soup.find_all(‘table‘)[2].find_all(‘tr‘) 3 # print(trs) 4 data = [] 5 for tr in trs: 6 info = [] 7 tds = tr.find_all(‘td‘) 8 if(len(tds) ==5 ): 9 for td in tds: 10 info.append(td.text.replace(‘\u3000‘, ‘‘)) 11 print(info) 12 else: 13 continue
利用pandas库可以将提取数据并形成Excel表格输出,优化后的代码如下:
1 # -*- coding: utf-8 -*- 2 3 import requests 4 from bs4 import BeautifulSoup 5 import pandas as pd 6 7 class CQstat(object): 8 def __init__(self): 9 self.headers = { 10 ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36‘ 11 } 12 13 def get_html(self,url): 14 try: 15 r = requests.get(url,headers=self.headers) 16 r.raise_for_status() 17 r.encoding = r.apparent_encoding 18 return r.text 19 except: 20 return None 21 22 def get_info(self): 23 url = ‘http://tjj.cq.gov.cn/tjsj/sjjd/201608/t20160829_434744.htm‘ 24 html = self.get_html(url) 25 soup = BeautifulSoup(html,‘lxml‘) 26 trs = soup.find_all(‘table‘)[2].find_all(‘tr‘) 27 data = [] 28 for tr in trs: 29 info = [] 30 tds = tr.find_all(‘td‘) 31 if len(tds) == 3: 32 for td in tds: 33 info.append(td.text.replace(‘\u3000‘,‘‘)) 34 info.insert(2,‘主营业务收入‘) 35 info.append(‘利润总额‘) 36 elif len(tds) == 4: 37 for td in tds: 38 info.append(td.text.replace(‘\u3000‘,‘‘)) 39 info.insert(0,‘行业‘) 40 elif len(tds) == 5: 41 for td in tds: 42 info.append(td.text.replace(‘\u3000‘,‘‘)) 43 else: 44 continue 45 data.append(info) 46 df = pd.DataFrame(data) 47 df.to_excel(‘1-7月份规模以上工业企业主要财务指标(分行业).xlsx‘,index=None,header=None) 48 49 cq = CQstat() 50 cq.get_info()
标签:src eve col close 解析 mamicode continue ash append
原文地址:https://www.cnblogs.com/chenmenghu/p/12268274.html
