标签:一起 技术 单位 image val 寻址 不能 multi 相对
由于透明混合在不同的绘制顺序下结果会不同,这就要求绘制前要对物体进行排序,然后再从后往前渲染。但即便是仅渲染一个物体(如上一章的水波),也会出现透明绘制顺序不对的情况,普通的绘制是无法避免的。如果要追求正确的效果,就需要对每个像素位置对所有的像素按深度值进行排序。本章将介绍一种仅DirectX11及更高版本才能实现的顺序无关的透明度(Order-Independent Transparency,OIT),虽然它是用像素着色器来实现的,但是用到了计算着色器里面的一些相关知识。
这一章综合性很强,在学习本章之前需要先了解如下内容:
| 章节内容 |
|---|
| 11 混合状态 |
| 12 深度/模板状态、平面镜反射绘制(仅深度/模板状态) |
| 14 深度测试 |
| 24 Render-To-Texture(RTT)技术的应用 |
| 28 计算着色器:波浪(水波) |
| 深入理解与使用缓冲区资源(结构化缓冲区、字节地址缓冲区) |
学习目标:
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
DirectCompute提供了三种内存模型:基于寄存器的内存、设备内存和组内共享内存。不同的内存模型在内存大小、速度、访问方式等地方有所区别。
基于寄存器的内存:它的访问速度非常快,但是寄存器不仅有数目限制,寄存器指向的资源内部也有大小限制。如纹理寄存器(t#),常量缓冲区寄存器(b#),无序访问视图寄存器(u#),临时寄存器(r#或x#)等。而且我们在使用寄存器时也不是直接指定某一个寄存器来使用,而是通过着色器对象(例如tbuffer,它是在GPU内部的内存,因此访问速度特别快)对应到某一寄存器,然后使用该着色器对象来间接使用该寄存器的。而且这些寄存器是随着着色器编译出来后定死了的,因此寄存器的可用情况取决于当前使用的着色器代码。
下面的代码展示了如何声明一个基于寄存器的内存:
tbuffer tb : register(t0)
{
float weight[256]; // 可以从CPU更新,只读
}设备内存:通常指的是D3D设备创建出来的资源(如纹理、缓冲区),这些资源可以长期存在,只要引用计数不为0。你可以给这些资源创建很大的内存空间来使用,并且你还可以将它们作为着色器资源或者无序访问资源绑定到寄存器中供使用。当然,这种作为着色器资源的访问速度还是没有直接在寄存器上创建的内存对象来得快,因为它是存储在GPU外部的显存中。尽管这些内存可以通过非常高的内部带宽来访问,但是在请求值和返回值之间也有一个相对较高的延迟。尽管无序访问视图可以用于在设备内存中实现与基于寄存器的内存相同的操作,但当执行频繁的读写操作时,性能将会收到严重影响。此外,由于每个线程都可以通过无序访问视图读取或写入资源中的任何位置,这需要手动同步对资源的访问,也可以使用原子操作,又或者定义一个合理的访问方式避免出现多个线程访问到设备内存的同一个数据。
组内共享内存:前面两种内存模型是所有可编程着色阶段都可使用的,但是group shared memory只能在计算着色器使用。它的访问速度比设备内存资源快些,比寄存器慢,但是也有明显的内存限制——每个线程组最多只能分配32KB内存,供内部所有线程使用。组内共享的内存必须确定线程将如何与内存交互和使用内存,因此它还必须同步对该内存的访问。这将取决于正在实现的算法,但它通常涉及到前面描述的线程寻址。
这三种类型的内存提供了不同的访问速度和可用的大小,使得它们可以用于与其能力相匹配的不同情况,这也给计算着色器提供了更大的内存操作灵活性。下表则是对内存模型的总结:
| 内存模型 | 访问速度 | 可用内存 | 使用方式 |
|---|---|---|---|
| 基于寄存器的内存 | 很快 | 小 | 声明寄存器内存对象、全局变量 |
| 设备内存 | 较慢 | 大 | 通过特定视图绑定到渲染管线 |
| 组内共享内存 | 较快 | 较小 | 仅支持计算着色器,在全局变量前面加groupshared |
由于大量线程同时运行,并且线程能够通过组内共享内存或通过无序访问视图对应的资源进行交互,因此需要能够同步线程之间的内存访问。与传统的多线程编程一样,许多线程可用读取和写入相同的内存位置,存在写后读(Read After Write,简称RAW)导致内存损坏的危险。如何在不损失GPU并行性带来的性能的情况下还能够高效地同步这么多线程?幸运的是,有几种不同的机制可用用于同步线程组内的线程。
这是一种最高级的同步技术。HLSL提供了许多内置函数,可用于同步线程组中所有线程的内存访问。需要注意的是,它只同步线程组中的线程,而不是整个调度。这些函数有两个不同的属性。第一个是调用函数时线程正在同步的内存类别(设备内存、组内共享内存,还是两者都有),第二个则指定给定线程组中的所有线程是否同步到其执行过程中的同一处。根据这两个属性,衍生出了下面这些不同版本的内置函数:
| 不带组内同步 | 带组内同步 |
|---|---|
| GroupMemoryBarrier | GroupMemoryBarrierWithGroupSync |
| DeviceMemoryBarrier | DeviceMemoryBarrierWithGroupSync |
| AllMemoryBarrier | AllMemoryBarrierWithGroupSync |
这些函数中都会阻止线程继续,直到满足该函数的特定条件位置。其中第一个函数GroupMemoryBarrior()阻塞线程的执行,直到线程组中的所有线程对组内共享内存的所有写入都完成。这用于确保当线程在组内共享内存中彼此共享数据时,所需的值在被其他线程读取之前有机会写入组内共享内存。这里有一个很重要的区别,即着色器核心执行一个写指令,而那个指令实际上是由GPU的内存系统执行的,并且写入内存中,然后在内存中它将再次对其他线程可用。从开始写入值到完成写入到目标位置有一个可变的时间量,这取决于硬件实现。通过执行阻塞操作,直到这些写操作被保证已经完成,开发人员可以确定不会有任何写后读错误引发的问题。
不过话说了那么多,总得实践一下。个人将双调排序项目中BitonicSort_CS.hlsl第15行的GroupMemoryBarrierWithGroupSync()修改为GroupMemoryBarrier(),执行后发现多次运行程序会出现一例排序结果不一致的情况。因此可以这样判断:GroupMemoryBarrier()仅在线程组内的所有线程组存在线程写入操作时阻塞,因此可能会出现阻塞结束时绝大多数线程完成了共享数据写入,但仍有少量线程甚至还没开始写入共享数据。因此实际上很少能够见到他出场的机会。
然后是GroupMemoryBarriorWithGroupSync()函数,相比上一个函数,他还阻止那些先到该函数的线程执行,直到所有的线程都到达该函数才能继续。很明显,在所有组内共享内存都加载之前,我们不希望任何线程前进,这使它成为完美的同步方法。
而第二对同步函数也执行类似的操作,只不过它们是在设备内存池上操作。这意味着在继续执行着色器程序前,可以同步通过无序访问视图写入资源的所有挂起内存的写入操作。这对于同步更大数目的内存更为有用,如果所需的共享存储器的大小太大不适合用组内共享内存,则可以将数据存在更大的设备内存的资源中。
第三对同步函数则是一起执行前面两种类型的同步,用于同时存在共享内存和设备内存的访问和同步上。
内存屏障对于同步线程中的所有线程非常有用。然而,在许多情况下,还需要较小规模的同步,可能一次只需要几个线程。在其他情况下,线程应该同步的位置可能在同一个执行点,也可能不在同一个执行点(例如,当线程组中的不同线程执行异构任务时)。Shader Model 5引入了许多新的原子操作,可以在线程之间提供更细力度的同步。这样在多线程访问共享资源时,能够确保所有其他线程都不能在统一时间访问相同资源。原子操作保证该操作一旦开始,就一直运行到结束:
| 原子操作 |
|---|
| InterlockedAdd |
| InterlockedMin |
| InterlockedMax |
| InterlockedOr |
| InterlockedAnd |
| InterlockedXor |
| InterlockedCompareStore |
| InterlockedCompareExchange |
| InterlockedExchange |
原子操作也可以用于组内共享内存和资源内存。这里举个使用的例子,如果计算着色器程序希望保留遇到特定数据值的线程数的计数,那么总计数可以初始化为0,并且每个线程可以在组内共享内存(以最快的访问速度)或资源(在调度调用之间持续存在)上执行InterLockedAdd函数。这些原子操作确保总计数正确递增,而不会被不同线程重写中间值。
每个函数都有其独特的输入要求和操作,因此在选择合适的函数时应参考Direct3D 11文档。像素着色阶段也可以使用这些函数,允许它跨资源同步(注意像素着色器不支持组内共享内存)。
现在让我们再回顾一下正确的透明计算法。对每一个像素来说,若当前的背景色为\(c_0\),然后待渲染的透明像素片元按深度值从大到小排序为\(c_1, c_2, ..., c_n\),透明度为\(a_1, a_2, ..., a_n\)则最终的像素颜色为:
\[
c=[a_n c_n + (1 - a_n)...[a_2 c_2 + (1 - a_2)[a_1 c_1 + (1 - a_1)c_0]...]
\]
在以往的绘制方式,我们无法控制透明像素片元的绘制顺序,运气好的话还能正确呈现,一旦换了视角就会出现问题。要是场景里各种透明物体交错在一起,基本上无论你怎么换视角都无法呈现正确的混合效果。因此为了实现顺序无关透明度,我们需要预先收集这些像素,然后再进行深度排序,最后再计算出正确的像素颜色。
Direct3D 11硬件为许多新的渲染算法打开了大门,尤其是对PS写入UAV、附着在Buffer的原子计数器的支持,为Per-Pixel Linked Lists带来了可能,它可以实现诸如OIT,间接阴影,动态场景的光线追踪等。
但是,由于着色器只有按值传递,没有指针和引用,在GPU是做不到使用基于指针或引用的链表的。为此,我们使用的数据结构是静态链表,它可以在数组中实现,原本作为next的指针则变成了下一个元素的索引值。
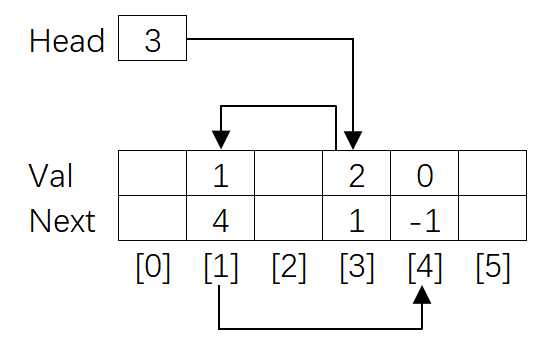
因为数组是一个连续的内存区域,我们还可以在一个数组中,存放多条静态链表(只要空间足够大)。基于这个思想,我们可以为每个像素创建一个链表,用来收集对应屏幕像素位置的待渲染的所有像素片元。
该算法需要历经两个步骤:
首先需要强调的是,这一步需要的是像素着色器5.0而不是计算着色器5.0。因为这一步实际上是把原本要绘制到渲染目标的这些像素片元给拦截下来,放到静态链表当中。而要写入Buffer就需要允许像素着色器支持无序访问视图(UAV),只有5.0及更高的版本才能这样做。
此外,我们还需要原子操作的支持,这也需要使用着色器模型5.0。
最后我们还需要创建两个支持读/写的缓冲区,用于绑定到无序访问视图:
RWStructuredBuffer才能够开启隐藏的计数器,而这个计数器又是实现静态链表必不可少的一部分,它用于统计缓冲区已经存放的链表节点数目。RWByteAddressBuffer,因为它能够支持原子操作。下图展示了通过像素着色器创建静态链表的过程:
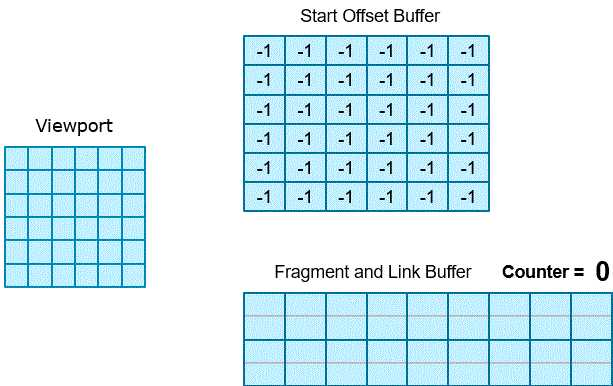
看完这个动图后其实应该基本上能理解了,可能你的脑海里已经有了初步的代码构造,但现在还是需要跟着现有的代码学习才能实现。
首先放出实现该效果需要用到的常量缓冲区、结构体和函数:
// OIT.hlsli
cbuffer CBFrame : register(b6)
{
uint g_FrameWidth; // 帧像素宽度
uint g_FrameHeight; // 帧像素高度
uint2 g_Pad2;
}
struct FragmentData
{
uint Color; // 打包为R8G8B8A8的像素颜色
float Depth; // 深度值
};
struct FLStaticNode
{
FragmentData Data; // 像素片元数据
uint Next; // 下一个节点的索引
};
// 打包颜色
uint PackColorFromFloat4(float4 color)
{
uint4 colorUInt4 = (uint4) (color * 255.0f);
return colorUInt4.r | (colorUInt4.g << 8) | (colorUInt4.b << 16) | (colorUInt4.a << 24);
}
// 解包颜色
float4 UnpackColorFromUInt(uint color)
{
uint4 colorUInt4 = uint4(color, color >> 8, color >> 16, color >> 24) & (0x000000FF);
return (float4) colorUInt4 / 255.0f;
}一个像素颜色的类型为float4,要是用它作为数据存储到缓冲区会特别消耗显存,因为最终显示到后备缓冲区的类型为R8G8B8A8_UNORM或B8G8R8A8_UNORM,要是能够将其打包成uint型,就可以节省这部分内存到原来的1/4。
当然,更狠的做法是,如果已知所有透明物体的Alpha值相同(都为0.5),那我们又可以将颜色压缩成R5G6B5_UNORM,然后再把深度值压缩成16为规格化浮点数,这样一个像素只需要一半的内存空间就能够表达了,当然代价为:颜色和深度都是有损的。
接下来是用于存储像素片元的着色器:
#include "Basic.hlsli"
#include "OIT.hlsli"
RWStructuredBuffer<FLStaticNode> g_FLBuffer : register(u1);
RWByteAddressBuffer g_StartOffsetBuffer : register(u2);
// 静态链表创建
// 提前开启深度/模板测试,避免产生不符合深度的像素片元的节点
[earlydepthstencil]
void PS(VertexPosHWNormalTex pIn)
{
// 省略常规的光照部分,最终计算得到的光照颜色为litColor
// ...
// 取得当前像素数目并自递增计数器
uint pixelCount = g_FLBuffer.IncrementCounter();
// 在StartOffsetBuffer实现值交换
uint2 vPos = (uint2) pIn.PosH.xy;
uint startOffsetAddress = 4 * (g_FrameWidth * vPos.y + vPos.x);
uint oldStartOffset;
g_StartOffsetBuffer.InterlockedExchange(
startOffsetAddress, pixelCount, oldStartOffset);
// 向片元/链接缓冲区添加新的节点
FLStaticNode node;
// 压缩颜色为R8G8B8A8
node.Data.Color = PackColorFromFloat4(litColor);
node.Data.Depth = pIn.PosH.z;
node.Next = oldStartOffset;
g_FLBuffer[pixelCount] = node;
}这里面多了许多有趣的部分,需要逐一仔细讲解一番。
首先是UAV寄存器,这里要先留个印象,寄存器索引初值不能从0开始,具体的原因要留到讲C++的某个API时才能说的明白。
来到PS,我们也可以给像素着色器添加属性,就像上面的[earlydepthstencil]那样。因为在绘制透明物体之前我们已经绘制了不透明的物体,而不透明的物体会阻挡它后面的透明像素片元。虽然一般情况下深度测试是在像素着色器之后,但也希望能拒绝掉那些被遮挡的像素片元写入到片元/链接缓冲区种。因此我们可以使用属性[earlydepthstencil],把深度/模板测试提前到光栅化后,像素着色阶段之前,这样就可以有效剔除被遮挡的像素,既减小了性能开销,又保证了渲染的正确。
然后是RWStructuredBuffer特有的方法IncrementCounter,它会返回当前的计数值,并给计数器+1.与之对应的逆操作为DecrementCounter。它也属于原子操作,因为涉及到大量的线程要访问一个计数器,必须要有相应的同步操作才能保证一个时刻只有一个线程访问该计数器,从而确保安全性。
这里又要再提一遍SV_POSITION,在作为顶点着色器的输出时,提供的是未经过透视除法的NDC坐标;而作为像素着色器的输入时,它历经了透视除法、视口变换,得到的是对应像素的坐标值。比如说第233行,154列的像素对应的xy坐标为(232.5, 153.5),抛弃小数部分正好可以用作同宽高纹理相同位置的索引。
紧接着是RWByteAddressBuffer的InterlockedExchange方法:
void InterlockedExchange(
in uint dest, // 目的地址
in uint value, // 要交换的值
out uint original_value // 取出来的原值
);你可以将其看作是一个写入缓冲区的函数,同时它又吐出原来存储的值。唯一要注意的是一切RWByteAddressBuffer的原子操作的地址值必须为4的倍数,因为它的读写单位都是32位的uint。
现在我们需要让片元/链接缓冲区和首节点偏移缓冲区都作为着色器资源。因为还需要准备一个存放渲染了场景中不透明物体的背景图作为混合初值,同时又还要将结果写入到渲染目标,这样的话我们还需要用到TextureRender类,存放与后备缓冲区等宽高的纹理,然后将场景中不透明的物体都渲染到此处。
对于顶点着色器来说,因为是渲染整个窗口,可以直接传顶点:
// OIT_Render_VS.hlsl
#include "OIT.hlsli"
// 顶点着色器
float4 VS(float3 vPos : POSITION) : SV_Position
{
return float4(vPos, 1.0f);
}而到了像素着色器,我们需要对当前像素对应的链表进行深度排序。由于访问设备内存的效率相对较低,而且排序又涉及到频繁的内存操作,在UAV进行链表排序的效率会很低。更好的做法是将所有像素拷贝到临时寄存器数组,然后再做排序,这样效率会更高,其实也就是在像素着色器开辟一个全局静态数组来存放这些链表节点的元素。由于是静态数组,数组元素固定,开辟较大的空间并不是一个比较好的选择,这不仅涉及到排序的复杂程度,还涉及到显存开销。因此我们需要限制排序的像素片元数目,同时也意味着只需要读取链表的前面几个元素即可,这是一种比较折中的做法。
由于排序算法的好坏也会影响最终的效率,对于小规模的排序,可以使用插入排序,它不仅是原址操作,对于已经有序的序列不会有多余的交换操作。又因为是线程内的排序,不能使用双调排序。
像素着色器的代码如下:
// OIT_Render_PS.hlsl
#include "OIT.hlsli"
StructuredBuffer<FLStaticNode> g_FLBuffer : register(t0);
ByteAddressBuffer g_StartOffsetBuffer : register(t1);
Texture2D g_BackGround : register(t2);
#define MAX_SORTED_PIXELS 8
static FragmentData g_SortedPixels[MAX_SORTED_PIXELS];
// 使用插入排序,深度值从大到小
void SortPixelInPlace(int numPixels)
{
FragmentData temp;
for (int i = 1; i < numPixels; ++i)
{
for (int j = i - 1; j >= 0; --j)
{
if (g_SortedPixels[j].Depth < g_SortedPixels[j + 1].Depth)
{
temp = g_SortedPixels[j];
g_SortedPixels[j] = g_SortedPixels[j + 1];
g_SortedPixels[j + 1] = temp;
}
else
{
break;
}
}
}
}
float4 PS(float4 posH : SV_Position) : SV_Target
{
// 取出当前像素位置对应的背景色
float4 currColor = g_BackGround.Load(int3(posH.xy, 0));
// 取出当前像素位置链表长度
uint2 vPos = (uint2) posH.xy;
int startOffsetAddress = 4 * (g_FrameWidth * vPos.y + vPos.x);
int numPixels = 0;
uint offset = g_StartOffsetBuffer.Load(startOffsetAddress);
FLStaticNode element;
// 取出链表所有节点
while (offset != 0xFFFFFFFF)
{
// 按当前索引取出像素
element = g_FLBuffer[offset];
// 将像素拷贝到临时数组
g_SortedPixels[numPixels++] = element.Data;
// 取出下一个节点的索引,但最多只取出前MAX_SORTED_PIXELS个
offset = (numPixels >= MAX_SORTED_PIXELS) ?
0xFFFFFFFF : element.Next;
}
// 对所有取出的像素片元按深度值从大到小排序
SortPixelInPlace(numPixels);
// 使用SrcAlpha-InvSrcAlpha混合
for (int i = 0; i < numPixels; ++i)
{
// 将打包的颜色解包出来
float4 pixelColor = UnpackColorFromUInt(g_SortedPixels[i].Color);
// 进行混合
currColor.xyz = lerp(currColor.xyz, pixelColor.xyz, pixelColor.w);
}
// 返回手工混合的颜色
return currColor;
}HLSL部分结束了,但C++端还有很多棘手的问题要处理。
在进行OIT像素收集时,需要通过替换像素着色器的手段来完成,因此它需要依附于BasicEffect,不好作为一个独立的Effect使用。在此先放出OITRender类的定义:
class OITRender
{
public:
template<class T>
using ComPtr = Microsoft::WRL::ComPtr<T>;
OITRender() = default;
~OITRender() = default;
// 不允许拷贝,允许移动
OITRender(const OITRender&) = delete;
OITRender& operator=(const OITRender&) = delete;
OITRender(OITRender&&) = default;
OITRender& operator=(OITRender&&) = default;
HRESULT InitResource(ID3D11Device* device,
UINT width, // 帧宽度
UINT height, // 帧高度
UINT multiple = 1); // 用多少倍于帧像素数的缓冲区存储像素片元
// 开始收集透明物体像素片元
void BeginDefaultStore(ID3D11DeviceContext* deviceContext);
// 结束收集,还原状态
void EndStore(ID3D11DeviceContext* deviceContext);
// 将背景与透明物体像素片元混合完成最终渲染
void Draw(ID3D11DeviceContext * deviceContext, ID3D11ShaderResourceView* background);
void SetDebugObjectName(const std::string& name);
private:
struct {
int width;
int height;
int pad1;
int pad2;
} m_CBFrame; // 对应OIT.hlsli的常量缓冲区
private:
ComPtr<ID3D11InputLayout> m_pInputLayout; // 绘制屏幕的顶点输入布局
ComPtr<ID3D11Buffer> m_pFLBuffer; // 片元/链接缓冲区
ComPtr<ID3D11Buffer> m_pStartOffsetBuffer; // 起始偏移缓冲区
ComPtr<ID3D11Buffer> m_pVertexBuffer; // 绘制背景用的顶点缓冲区
ComPtr<ID3D11Buffer> m_pIndexBuffer; // 绘制背景用的索引缓冲区
ComPtr<ID3D11Buffer> m_pConstantBuffer; // 常量缓冲区
ComPtr<ID3D11ShaderResourceView> m_pFLBufferSRV; // 片元/链接缓冲区的着色器资源视图
ComPtr<ID3D11ShaderResourceView> m_pStartOffsetBufferSRV; // 起始偏移缓冲区的着色器资源视图
ComPtr<ID3D11UnorderedAccessView> m_pFLBufferUAV; // 片元/链接缓冲区的无序访问视图
ComPtr<ID3D11UnorderedAccessView> m_pStartOffsetBufferUAV; // 起始偏移缓冲区的无序访问视图
ComPtr<ID3D11VertexShader> m_pOITRenderVS; // 透明混合渲染的顶点着色器
ComPtr<ID3D11PixelShader> m_pOITRenderPS; // 透明混合渲染的像素着色器
ComPtr<ID3D11PixelShader> m_pOITStorePS; // 用于存储透明像素片元的像素着色器
ComPtr<ID3D11PixelShader> m_pCachePS; // 临时缓存的像素着色器
UINT m_FrameWidth; // 帧像素宽度
UINT m_FrameHeight; // 帧像素高度
UINT m_IndexCount; // 绘制索引数
};这里不放出初始化的代码,但在调用初始化的时候需要注意提供合理的帧像素的倍数,若设置的太低,则缓冲区可能不足以容纳透明像素片元而渲染异常。
不管写什么渲染类,渲染状态的管理是最复杂的,一处错误都会导致渲染结果的不理想。
该方法首先要解决两个主要问题:UAV的初始化、绑定到像素着色阶段。
void ClearUnorderedAccessViewUint(
ID3D11UnorderedAccessView *pUnorderedAccessView, // [In]待清空UAV
const UINT [4] Values // [In]清空值/向量
);该方法对任何UAV都有效,它是以二进制位的形式来清空值。若为DXGI特定类型,如R16G16_UNORM,则该方法会根据Values的前两个元素取出各自的低16位分别复制到每个数组元素的x分量和y分量。若为原始内存的视图或结构化缓冲区的视图,则只取Values的第一个元素来复制到缓冲区的每一个4字节内。
既然像素着色器能够使用UAV,一开始找了半天都没找到ID3D11DeviceContext::PSSetUnorderedAccessViews,结果发现居然是在OM阶段的函数提供UAV绑定。
void ID3D11DeviceContext::OMSetRenderTargetsAndUnorderedAccessViews(
UINT NumRTVs, // [In]渲染目标数
ID3D11RenderTargetView * const *ppRenderTargetViews, // [In]渲染目标视图数组
ID3D11DepthStencilView *pDepthStencilView, // [In]深度/模板视图
UINT UAVStartSlot, // [In]UAV起始槽
UINT NumUAVs, // [In]UAV数目
ID3D11UnorderedAccessView * const *ppUnorderedAccessViews, // [In]无序访问视图数组
const UINT *pUAVInitialCounts // [In]各个无序访问视图的计数器初始值
);前三个参数和后三个参数应该都没什么问题,但中间的那个参数是一个大坑。对于像素着色器,UAVStartSlot应当等于已经绑定的渲染目标视图数目。渲染目标和无序访问视图在写入的时候共享相同的资源槽,这意味着必须为UAV指定偏移量,以便于它们放在待绑定的渲染目标视图之后的插槽中。因此在前面的HLSL代码中,u寄存器需要从1开始就是这里来的。
注意:RTV、DSV、UAV不能独立设置,它们都需要同时设置。
两个绑定了同一个子资源(也因此共享同一个纹理)的RTV,或者是两个UAV,又或者是一个UAV和RTV,都会引发冲突。
OMSetRenderTargetsAndUnorderedAccessViews在以下情况才能运行正常:
当NumRTVs != D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL且NumUAVs != D3D11_KEEP_UNORDERED_ACCESS_VIEWS时,需要满足下面这些条件:
当NumRTVs == D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL时,说明OMSetRenderTargetsAndUnorderedAccessViews只绑定UAVs,需要满足下面这些条件:
它还会解除绑定下面这些东西:
提供的深度/模板缓冲区会被忽略,并且已经绑定的深度/模板缓冲区并没有被卸下。
当NumUAVs == D3D11_KEEP_UNORDERED_ACCESS_VIEWS时,说明OMSetRenderTargetsAndUnorderedAccessViews只绑定RTVs和DSV,需要满足下面这些条件
NumRTVs <= 8
这些RTVs相互没有资源冲突
DSV的纹理必须匹配RTV的纹理(但不是相同)
它还会解除绑定下面这些东西:
所有在slots < NumRTVs的UAVs
所有与待绑定的RTVs发生资源冲突的UAVs
所有当前绑定的资源(SOTargets,CS UAVs, SRVs)冲突的RTVs
提供的UAVStartSlot忽略。
选择可以把目光放回到OITRender::BeginDefaultStore上:
void OITRender::BeginDefaultStore(ID3D11DeviceContext* deviceContext)
{
deviceContext->RSSetState(RenderStates::RSNoCull.Get());
UINT numClassInstances = 0;
deviceContext->PSGetShader(m_pCachePS.GetAddressOf(), nullptr, &numClassInstances);
deviceContext->PSSetShader(m_pOITStorePS.Get(), nullptr, 0);
// 初始化UAV
UINT magicValue[1] = { 0xFFFFFFFF };
deviceContext->ClearUnorderedAccessViewUint(m_pFLBufferUAV.Get(), magicValue);
deviceContext->ClearUnorderedAccessViewUint(m_pStartOffsetBufferUAV.Get(), magicValue);
// UAV绑定到像素着色阶段
ID3D11UnorderedAccessView* pUAVs[2] = { m_pFLBufferUAV.Get(), m_pStartOffsetBufferUAV.Get() };
UINT initCounts[2] = { 0, 0 };
deviceContext->OMSetRenderTargetsAndUnorderedAccessViews(D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL,
nullptr, nullptr, 1, 2, pUAVs, initCounts);
// 关闭深度写入
deviceContext->OMSetDepthStencilState(RenderStates::DSSNoDepthWrite.Get(), 0);
// 设置常量缓冲区
deviceContext->PSSetConstantBuffers(6, 1, m_pConstantBuffer.GetAddressOf());
}上面的代码有两个点要特别注意:
方法如下:
void OITRender::EndStore(ID3D11DeviceContext* deviceContext)
{
// 恢复渲染状态
deviceContext->PSSetShader(m_pCachePS.Get(), nullptr, 0);
ComPtr<ID3D11RenderTargetView> currRTV;
ComPtr<ID3D11DepthStencilView> currDSV;
ID3D11UnorderedAccessView* pUAVs[2] = { nullptr, nullptr };
deviceContext->OMSetRenderTargetsAndUnorderedAccessViews(D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL,
nullptr, nullptr, 1, 2, pUAVs, nullptr);
m_pCachePS.Reset();
}方法如下,到这一步其实已经没那么复杂了:
void OITRender::Draw(ID3D11DeviceContext* deviceContext, ID3D11ShaderResourceView* background)
{
UINT strides[1] = { sizeof(VertexPos) };
UINT offsets[1] = { 0 };
deviceContext->IASetVertexBuffers(0, 1, m_pVertexBuffer.GetAddressOf(), strides, offsets);
deviceContext->IASetIndexBuffer(m_pIndexBuffer.Get(), DXGI_FORMAT_R32_UINT, 0);
deviceContext->IASetInputLayout(m_pInputLayout.Get());
deviceContext->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
deviceContext->VSSetShader(m_pOITRenderVS.Get(), nullptr, 0);
deviceContext->PSSetShader(m_pOITRenderPS.Get(), nullptr, 0);
deviceContext->GSSetShader(nullptr, nullptr, 0);
deviceContext->RSSetState(nullptr);
ID3D11ShaderResourceView* pSRVs[3] = {
m_pFLBufferSRV.Get(), m_pStartOffsetBufferSRV.Get(), background};
deviceContext->PSSetShaderResources(0, 3, pSRVs);
deviceContext->PSSetConstantBuffers(6, 1, m_pConstantBuffer.GetAddressOf());
deviceContext->OMSetDepthStencilState(nullptr, 0);
deviceContext->OMSetBlendState(nullptr, nullptr, 0xFFFFFFFF);
deviceContext->DrawIndexed(m_IndexCount, 0, 0);
// 绘制完成后卸下绑定的资源即可
pSRVs[0] = pSRVs[1] = pSRVs[2] = nullptr;
deviceContext->PSSetShaderResources(0, 3, pSRVs);
}现在场景中除了山体、波浪,还有两个透明相交的立方体。只考虑开启OIT的GameApp::DrawScene方法如下:
void GameApp::DrawScene()
{
assert(m_pd3dImmediateContext);
assert(m_pSwapChain);
m_pd3dImmediateContext->ClearRenderTargetView(m_pRenderTargetView.Get(), reinterpret_cast<const float*>(&Colors::Silver));
m_pd3dImmediateContext->ClearDepthStencilView(m_pDepthStencilView.Get(), D3D11_CLEAR_DEPTH | D3D11_CLEAR_STENCIL, 1.0f, 0);
// 渲染到临时背景
m_pTextureRender->Begin(m_pd3dImmediateContext.Get(), reinterpret_cast<const float*>(&Colors::Silver));
{
// ******************
// 1. 绘制不透明对象
//
m_BasicEffect.SetRenderDefault(m_pd3dImmediateContext.Get(), BasicEffect::RenderObject);
m_BasicEffect.SetTexTransformMatrix(XMMatrixIdentity());
m_Land.Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
// ******************
// 2. 存放透明物体的像素片元
//
m_pOITRender->BeginDefaultStore(m_pd3dImmediateContext.Get());
{
m_RedBox.Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
m_YellowBox.Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
m_pGpuWavesRender->Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
}
m_pOITRender->EndStore(m_pd3dImmediateContext.Get());
}
m_pTextureRender->End(m_pd3dImmediateContext.Get());
// 渲染到后备缓冲区
m_pOITRender->Draw(m_pd3dImmediateContext.Get(), m_pTextureRender->GetOutputTexture());
// ******************
// 绘制Direct2D部分
//
// ...
HR(m_pSwapChain->Present(0, 0));
}下面演示了关闭OIT和深度写入、关闭OIT但开启深度写入、开启OIT下的场景渲染效果:
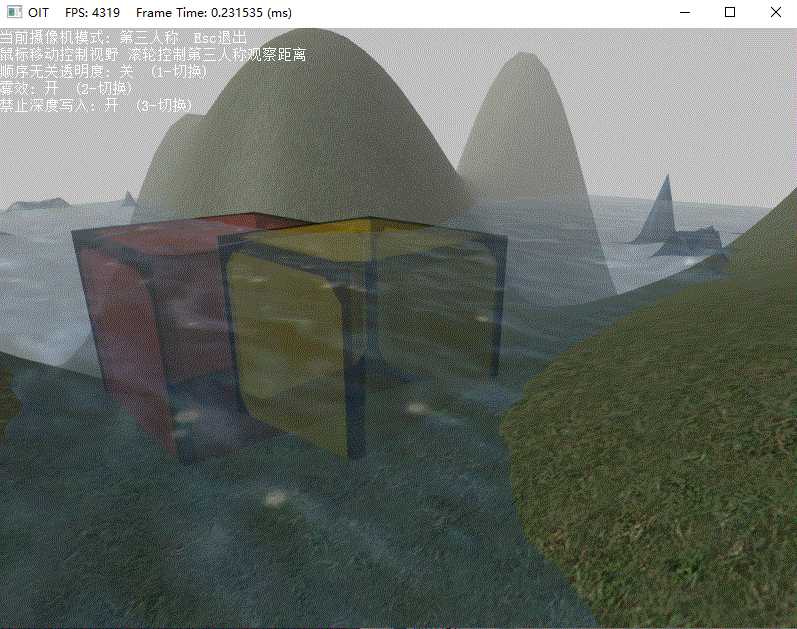
开启OIT的平均帧数为2700,而默认平均帧数为4200。可见影响渲染性能的主要因素有:RTT的使用、场景中透明像素的复杂程度、排序算法的选择和n的限制。因此要保证渲染效率,最好是能够减少透明物体的复杂程度、场景中透明物体的数目,必要时甚至是避免透明混合。
R5G6B5_UNORM(规定透明物体Alpha统一为0.5),然后再把深度值压缩成16为规格化浮点数。同时也要改动C++端代码来适配。DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
DirectX11 With Windows SDK--29 计算着色器:内存模型、线程同步;实现顺序无关透明度(OIT)
标签:一起 技术 单位 image val 寻址 不能 multi 相对
原文地址:https://www.cnblogs.com/X-Jun/p/12272328.html