标签:要求 遇到 相关 avg lap play 避免 登陆 vertica
第一部分 初始Mysql
关系型:如sqllite,db2,oracle,access,sql server,MySQL,注意:sql语句通用
非关系型:mongodb,redis,memcache
初识sql语句
#进入mysql客户端 $mysql mysql> select user(); #查看当前用户 mysql> exit # 也可以用\q quit退出 # 默认用户登陆之后并没有实际操作的权限 # 需要使用管理员root用户登陆 $ mysql -u root -p # mysql5.6默认是没有密码的 #遇到password直接按回车键 mysql> set password = password(‘root‘); # 给当前数据库设置密码 # 创建账号 mysql> create user ‘cui‘@‘192.168.10.%‘ IDENTIFIED BY ‘123‘;# 指示网段 mysql> create user ‘cui‘@‘192.168.10.5‘ # 指示某机器可以连接 mysql> create user ‘cui‘@‘%‘ #指示所有机器都可以连接 mysql> show grants for ‘cui‘@‘192.168.10.5‘;查看某个用户的权限 # 远程登陆 $ mysql -u root -p 123456 -h 192.168.10.3 # 给账号授权 mysql> grant all on *.* to cui‘@‘%‘; mysql> flush privileges; # 刷新使授权立即生效 # 创建账号并授权 mysql> grant all on *.* to ‘cui‘@‘%‘ identified by ‘123‘
sql的知识点整理
# 显示数据库
SHOW DATABASES;
# 创建数据库
# utf-8
create database 数据库名称 default charset utf8 collate utf8_general_ci;
# gbk
create database 数据库名称 default charseter set gbk collate gbk_chinese_ci;
# 使用数据库
use db_name
# 建表语法:所谓的建表就是声明列的过程 create table 表名( 列1声明 列1参数, 列2声明 列2参数, ... 列n声明 列n参数 )engine myisam/innodb/bdb charset utf8/gbk/latin1...

是否可空,null表示空,非字符串 not null - 不可空 null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值 create table tb1( nid int not null defalut 2, num int not null )
自增,如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列) create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null auto_increment, num int null, index(nid) ) 注意:1、对于自增列,必须是索引(含主键)。 2、对于自增可以设置步长和起始值 show session variables like ‘auto_inc%‘; set session auto_increment_increment=2; set session auto_increment_offset=10; shwo global variables like ‘auto_inc%‘; set global auto_increment_increment=2; set global auto_increment_offset=10;
主键,一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。 create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null, num int not null, primary key(nid,num) )
外键,一个特殊的索引,只能是指定内容 creat table color( nid int not null primary key, name char(16) not null ) create table fruit( nid int not null primary key, smt char(32) null , color_id int not null, constraint fk_cc foreign key (color_id) references color(nid) )
# 删除表
drop table 表名
# 修改表
添加列:alter table 表名 add 列名 类型 删除列:alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键:alter table 表名 drop foreign key 外键名称 修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; 删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
# 表内容操作
1 增 2 insert into 表 (列名,列名...) values (值,值,值...) 3 insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) 4 insert into 表 (列名,列名...) select (列名,列名...) from 表 5 6 删 7 delete from 表 8 delete from 表 where id=1 and name=‘alex‘ 9 10 改 11 update 表 set name = ‘alex‘ where id>1 12 13 查 14 select * from 表 15 select * from 表 where id > 1 16 select nid,name,gender as gg from 表 where id > 1
a、条件 select * from 表 where id > 1 and name != ‘alex‘ and num = 12; select * from 表 where id between 5 and 16; select * from 表 where id in (11,22,33) select * from 表 where id not in (11,22,33) select * from 表 where id in (select nid from 表) b、通配符 select * from 表 where name like ‘ale%‘ - ale开头的所有(多个字符串) select * from 表 where name like ‘ale_‘ - ale开头的所有(一个字符) c、限制 select * from 表 limit 5; - 前5行 select * from 表 limit 4,5; - 从第4行开始的5行 select * from 表 limit 5 offset 4 - 从第4行开始的5行 d、排序 select * from 表 order by 列 asc - 根据 “列” 从小到大排列 select * from 表 order by 列 desc - 根据 “列” 从大到小排列 select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序 e、分组 select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 特别的:group by 必须在where之后,order by之前 f、连表 无对应关系则不显示 select A.num, A.name, B.name from A,B Where A.nid = B.nid 无对应关系则不显示 select A.num, A.name, B.name from A inner join B on A.nid = B.nid A表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A left join B on A.nid = B.nid B表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A right join B on A.nid = B.nid g、组合 组合,自动处理重合 select nickname from A union select name from B 组合,不处理重合 select nickname from A union all select name from B
# 比较运算符 运算符 说 明 < 小于 <= 小于等于 = 等于 in 在某集合内 !=或<> 不等于 >= 大于等于 > 大于 between 在某范围内 # 逻辑运算符 运算符 说 明 NOT或! 逻辑非 OR 或 || 逻辑或 AND或&& 逻辑与 # 查询模型(重要): 列就是变量,在每一行上,列的值都在变化。Where条件是表达式,在哪一行上表达式为真,哪一行就取出来 # where是针对表进行操作 having 是对结果集进行操作 # 多字段排序 order by 列1 desc/asc, 列2 desc/asc , 列3 desc/asc # from型子查询:把内层的查询结果当成临时表,供外层sql再次查询。
# 连表
left join 以左边表为准
right join 以右边表为准
inner
# 视图 view 在查询中,我们经常把查询结果当作临时表来看。 创建视图的语法: create view 视图名 as select 语句 表与视图的关系? 表变了,视图跟着变; 某种情况下,视图变了表也就变了。要求视图与表之间是一一对应关系。 视图特点: 一张虚拟表,只存储表结构,解决表不能长时间存储问题 对视图表修改、删除会直接影响基本表 当视图来自多个基本表时,不允许添加和删除数据 创建视图 CREATE view 视图名字 as 查询sql语句 删除视图 drop view 视图名字 修改视图 alter view 视图名字 as 查询sql新语句 # 触发器 触发器:监听某种情况,并触发某种操作 触发器创建语法四要素: 1.监听地点(table) 2.监听事件(insert/update/delete) 3.触发时间(after/before) 4. 触发事件() -- 语法 create TRIGGER 触发器名字 afte/before insert/update/delete on 表名 for each row begin # 需要执行的sql语句 end 注意: 1. after/before; 只能选一个,after表示后置触发,before表示前置触发 2. insert/update/delete; 只能选一个 删除触发器:drop TRIGGER 触发器名字; # Procedure(存储过程)函数的用法 #存储过程:类似于函数方法,简单说存储过程是为了完成某个数据库中的特定功能而编写的语句集合,该语句包含SQL语句、条件语句和循环语句等。 1. 查看现有的存储过程 show PROCEDURE status 2. 删除存储过程 drop PROCEDURE 存储过程名称 3. 调用存储过程 call 存储过程名称(参数入/出类型 参数名 数据类型); # 存储引擎 innodb与MyISAM存储引擎的区别: 1. innodb是mysql5.5版本以后的默认存储引擎,而MyISAM是5.5版本以前的默认存储引擎 2. innodb支持事物,而MyISAM不支持事物 3. innodb支持行级锁,而MyISAM支持的是并发的表级锁 4. innodb支持外键,而MyISAM不支持外键 5. 二者存储引擎都采用B+TREE存储数据,但是innodb的索引与数据存储在一个文件中,这种方式称为聚合索引。而MyISAM则会单独创建一个索引文件,也就是说,数据与索引是分开的 6. 在效率方面MyISAM比innodb高,但是在性能方面innodb要好一点 # 事物 什么是事物? 一组sql语句批量执行,要么全部执行成功,要么全部执行失败。 事物的四个特点: 原子性 一致性 隔离性 持久性 # 索引 1.普通索引的操作方式 加速查询 create table t1( id int not null, name varchar(50), index idx_id(id) ) CREATE index idx_name on t1(name); # 单独创建索引 show index from t1; # 显示索引 drop index idx_id on t1; # 删除一个索引 2.唯一索引 有两个功能:加速查询和唯一约束 create table t2( id int not null, name varchar(50), UNIQUE index idx_id(id) ) CREATE UNIQUE index idx_name on t2(id,name); show index from t2; # 显示索引 3. 主键索引 create table t3( id int not null PRIMARY key, name varchar(50), UNIQUE index idx_id(id) # 多主键 PRIMARY key(id, name) 组合索引 ) # alter table t3 add PRIMARY key(id) show index from t3; 4.组合索引 # 自定义函数(有返回值) delimiter \set global log_bin_trust_function_creators=TRUE; create function f2( i1 int, i2 int) returns int BEGIN declare num int; set num = i1 + i2; return(num); END \delimiter ; select f2(25,25);
一:数据库操作 1.默认数据库 mysql- 用户权限相关数据 test- 用于用户测试数据 information-schema- Mysql本身架构相关数据 2.创建数据库 # utf-8 create databases 数据库名称 default charset utf8 # gbk create databases 数据库名称 default charset set gbk 3.使用数据库 use db_name 显示当前使用的数据库中的所有表:show tables; 4.用户管理 创建用户 create user ‘用户名‘@‘IP地址‘ identified by ‘密码‘; 删除用户 drop user ‘用户名‘@‘IP地址‘; 修改用户 rename user ‘用户名‘@‘IP地址‘; to ‘新用户名‘@‘IP地址‘;; 修改密码 set password for ‘用户名‘@‘IP地址‘ = Password(‘新密码‘) 二:数据表操作 1.创建表 create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空 )engine=inndb default charset=utf8; # 自增 create table tb1( nid int not null auto_increment primary key, num int null ) 注:对于自增列,必须是索引(含主键) # 主键 一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一 2.删除表 drop table 表名 3.清空表 delete from 表名 truncate table 表名 4.修改表 添加列: alter table 表名 add 列名 类型 删除列: alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; --类型 alter table 表名 change 原列名 新列名 类型; --列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; 5.基本数据类型 bit 二进制位 tinyint 有符号: -128~127 无符号:0~255 int bigint decimal 准确的小数值,因为其内部按照字符串存储 float double char 数据类型用于表示固定长度的字符串,可以包含最多达255个字符 varchar 用于变长的字符串,可以包含最多255个字符 注:char处理速度快 三:表内容操作 1.增 insert into 表(列名,列名...) values(值,值,...) insert into 表(列名,列名...) values(值,值,...),(值,值,...) 2.删 delete from 表 delete from 表 where id=1 and name=‘alex‘; 3.改 update 表 set name=‘alex‘ where id>1; 4.查 select *from 表 select *from 表 where id>1; select nid,gender from 表 where id >1; 5.其他 a.条件 select *from 表 where id>1 and name!=‘alex‘ and num=12; select *from 表 where id between 5 and 16; select *from 表 where id in (11,22,33); select *from 表 where id not in (11,22,33); select *from 表 where id in (select nid from 表); b.通配符 select *from 表 where name like ‘ale%‘ -- ale开头的所有(多个字符串) select *from 表 where name like ‘ale_‘ -- ale开头的所有(一个字符串) c.限制 select *from 表 limit 5; -- 前5行 select *from 表 limit 4,5 -- 从第4行开始的5行 select * from 表 limit 5 offset 4 -- 从第4行开始的5行 d.排序 select *from 表 order by 列 asc --根据列从小到大 select *from 表 order by 列 desc --根据列从大到小 select * from 表 order by 列1 desc,列2 asc -- 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序 e.分组 select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 注:group by 必须在where之后,order by之前 f.连表 无对应关系则不显示 select A.num,A.name,B.name from A,B where A.nid=B.nid; 无对应关系则不显示 select A.num,A.name,B.name from A inner join B on A.nid=B.nid; A表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A left join B on A.nid = B.nid B表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A right join B on A.nid = B.nid g.组合 组合,自动处理重合 select nickname from A union select name from B 组合,不处理重合 select nickname from A union all select name from B 四:视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需要使用[名称]即可获取结果集,并可以将其当作表来使用 1. 创建视图 -- 格式: create view视名称 as sql语句 2.删除视图 -- 格式: drop view 视图名称 3.修改视图 -- 格式 alter view 视图名称 as sql语句 4.使用视图 select *from v1 五:触发器 对某个表进行[增/删/改]操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行[增/删/改]前后的行为 1.创建基本语法 # 插入前 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW BEGIN ... END # 插入后 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW BEGIN ... END # 删除前 CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW BEGIN ... END # 删除后 CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW BEGIN ... END # 更新前 CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW BEGIN ... END # 更新后 CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW BEGIN ... END # 使用触发器 insert into tb1(num) values(666) # 传入自己的值 delimiter // -- 更改终止符 create trigger t1 before insert on student for each row begin -- insert into teacher(tname) values(‘光辉‘); insert into teacher(tname) values(new.sname); end // delimiter ; -- 还原终止符 insert into student(sname,gender,class_id) values(‘娥‘,‘女‘,1),(‘花‘,‘女‘,1); -- new 代表新数据 -- old 代表老数据 # 删除触发器 drop trigger t1; 六:存储过程 存储过程是一个SQL语句集合。当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。 -- 创建存储过程 delimiter // create procedure p1() begin select *from t1; end // delimiter ; -- 执行存储过程 call p1() # 对于存储过程,可以接收参数,其参数有三类: in 仅用于传入参数用 out 仅用于返回值用 inout 既可以传入又可以当作返回值 # 创建存储过程 delimiter // create procedure p2( in i1 int, in i2 int, inout i3 int, out r1 int ) begin declare temp1 int; declare temp2 int default 0; set temp1=1; set r1=i1+i2+temp1+temp2; set i3=i3+100; end // delimiter ; --执行 set @t1=4; set@t2=0; call p2(1,2,@t1,@t2); select @t1,@t2; # 创建存储函数 -- delimiter // CREATE PROCEDURE p3( in n1 int, out n2 int -- 用于标识存储过程的执行结果 ) begin set n2=123; select *from student where sid>n1; end// delimiter; 执行 set @v1=0; call p3(4,@v1); select @v1; 可以返回两个值 n1=4 @v1=123 # 执行存储过程 -- 无参数 call t1() -- 有参数,全in call t1(1,2) -- 有参数,有in,out,inout set @t1=0; set @t2=3; call t1(1,2,@t1,@t2) 七:函数 1.内置函数: CHAR_LENGTH(str):返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符 CONCAT(str1,str2,...) 字符串拼接 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV(‘a‘,16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D),以四舍五入的方式保留小数点后 D 位 INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 2.自定义函数 delimiter \create function f2( i1 int, i2 int) returns int BEGIN declare num int; set num = i1 + i2; return(num); END \delimiter ; -- 执行函数 select f2(25,25); -- 删除函数 drop function f2; 八:事务 事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。 九:索引 是数据库中专门用于帮助用户快速查询数据的一种数据结构。类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可
常用函数:
数学函数: abs(x) 返回x的绝对值 bin(x) 返回x的二进制(oct 返回八进制,hex返回十六进制) ceiling(x) 返回大于x的最小整数值 exp(x) 返回e的x次方 floor(x) 返回小于x的最大整数值 greatest(x1,x2,...,xn) 返回集合中最大的值 least(xq,x2,....,xn) 返回集合中最小的值 ln(x) 返回x的自然对数 log(x,y) 返回x的以y为底的对数 mod(x,y) 返回x/y的模 rand() 返回0-1内的随机值 round(x,y) 返回参数x的四舍五入的有y位小数的值 sign(x) 返回代表数字x的符号的值 sqrt(x) 返回x的平方根 truncate(x,y) 返回数字x截断y位小数的结果 聚合函数 avg(col) 返回指定列的平均值 count(col) 返回指定列中非null值的个数 min(col) 返回指定列的最小值 max(col) 返回指定列的最大值 sum(col) 返回指定列的所有值之和 group_concat(col) 返回由属于一组的列值连接组合而成的结果 字符串函数 ascii(char) 返回字符的ascii码值 bit_length(str) 返回字符串的比特长度 length(x) 返回字符串长度 concat_ws(sep,s1,s2,...,sn) 将s1,s2,...,sn连接成字符串,并用sep字符间隔 insert(str,x,y,instr) 将字符串str从第x位置开始,y个字符长度的字串替换为字符串instr left(str,x) 返回字符串str中最左边的x个字符 length(x) 返回字符串长度 ltrim(str) 从字符串str中切掉开头的空格 position(substr in str) 返回子串substr在字符串str第一次出现的位置,从1开始索引。 日期时间函数: select now() 当下时间 curdate() 或 current_date() 返回当前的日期 curtime() 或 current_time() 返回当前的时间 dayofweek() 某日是那一周的第几天 date_add(date,interval int keyword) 返回日期date加上间隔时间int的结果 date_format(date,fmt) 按照指定的fmt格式格式化日期date值
#1.查询商品主键是32的商品 select goods_id,goods_name,shop_price from goods where goods_id=32; #2.查询不属于第三个栏目的所有商品 select goods_id,cat_id,goods_name,shop_price from goods where cat_id !=3; # != 等价于 <> #3.本店价格高于3000元商品 select goods_id,goods_name,shop_price from goods where shop_price > 3000; #4.取出第四个栏目和第十一个栏目商品 select goods_id,goods_name,cat_id from goods where cat_id in (4,11); #cat_id在4和11集合里 #5.取出商品价格在100到500之间的商品 select goods_id,goods_name,shop_price from goods where shop_price between 100 and 500; #6.取出不在第三个栏目且不在第十一个栏目的商品,用not in和 and 分别实现。即栏目是三的和十一的都不要 select goods_id,goods_name,cat_id from goods where cat_id not in (3,11); # in 是散点的集合 #用and实现 select goods_id,good_name,cat_id from goods where cat_id !=3 and cat_id!=11; #7.取出价格在[100,300]或者[4000,5000]之间的 待检验:select goods_id,goods_name,shop_price from goods where shop_price between 100 and 300 or between 4000 and 5000; select goods_id,goods_name,shop_price from goods where shop_price >=100 and shop_price<=300 or shop_price>=3000 and shop_price<=5000; #8.取出第三个栏目下价格小于1000或者大于3000,同时点击量大于等于5的商品 select goods_id,shop_price,cat_id,click_count where cat_id=3 and (shop_price <1000 or shop_price>3000) and click_count>=5; #9.查出名称以诺基亚开头的商品 eg:诺基亚N95,诺基亚原装充电器 模糊查询 select goods_id,goods_name,shop_price from goods where goods_name like ‘诺基亚%‘; #理解查询语句 把列看成变量,把where后面看成php中if(exp)里的exp表达式。 哪些行被取出来?----哪一行能让exp为真,哪一行就能取出来。 #10.取出商品id,商品名,本店价比市场价省多少钱 select goods_id,goods_name,market_price-shop_price from goods where 1; #列的运算结果可以当成列看,还可以起列别名 select goods_id,goods_name,(market_price-shop_price) as discount from goods where cat_id!=3; 注意:如果想选出店价比市场价省2000元以上的商品 select goods_id,goods_name,market_price-shop_price from goods where (market_price-shop_price)>2000; 错误:select goods_id,goods_name,market_price-shop_price from goods where discount >2000; 分析:where是对表中的数据发挥作用,查询出数据来。where发挥作用时,表上并没有discount列,发挥完作用形成的结果里才有discount。对于结果中的列。如再筛选,需用having。
python操作Mysql
两种方式:
原生模块pymysql
ORM框架SQLAchemy
# pymsql
使用操作:
1. 执行SQL
1 import pymysql 2 3 # 创建连接 4 conn = pymysql.connect(host=‘127.0.0.1‘, port=3306, user=‘root‘, passwd=‘123456‘, db=‘t1‘) 5 # 创建游标 6 cursor = conn.cursor() 7 8 # 执行SQL,并返回收影响行数 9 effect_row = cursor.execute("update hosts set host = ‘1.1.1.2‘") 10 11 # 执行SQL,并返回受影响行数 12 #effect_row = cursor.execute("update hosts set host = ‘1.1.1.2‘ where nid > %s", (1,)) 13 14 # 执行SQL,并返回受影响行数 15 #effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)]) 16 17 18 # 提交,不然无法保存新建或者修改的数据 19 conn.commit() 20 21 # 关闭游标 22 cursor.close() 23 # 关闭连接 24 conn.close()
2. 登陆校验
import pymysql # 获取用户输入 username = input("输入用户名:") pwd = input("请输入密码:") # 连接数据库检索有没有该用户 conn = pymysql.connect( host="localhost", port=3306, database="userinfo", user="root", password="123456", charset="utf8" ) # 获取光标 cursor = conn.cursor() sql = "select *from info where username=‘%s‘ and password=‘%s‘" % (username, pwd) ret = cursor.execute(sql) if ret: print("登陆成功") else: print("登陆失败!") # 关闭光标对象 cursor.close() # 关闭连接 conn.close()
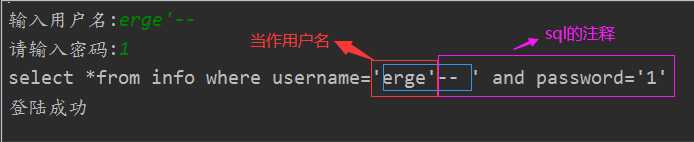
3. 避免sql注入
import pymysql # 获取用户输入 username = input("输入用户名:") pwd = input("请输入密码:") # 连接数据库检索有没有该用户 conn = pymysql.connect( host="localhost", port=3306, database="userinfo", user="root", password="123456", charset="utf8" ) # 获取光标id cursor = conn.cursor()
sql = "select *from info where username=%s and password=%s" ret = cursor.execute(sql, [username, pwd]) # 让pymysql帮我们拼接sql语句 if ret: print("登陆成功") else: print("登陆失败!") # 关闭光标对象 cursor.close() # 关闭连接 conn.close() # 若对数据库进行了修改,则最后需要加上conn.commit() # sql注入知识点
sql的注释:
"-- "用于单行注释。格式:-- 注释内容
注意这里的注释‘-- ‘符号后需要一个空格,注释才生效

1 import pymysql 2 conn=pymysql.connect( 3 host="localhost", 4 port=3306, 5 database="userinfo", 6 user="root", 7 password="123456", 8 charset="utf8" 9 ) 10 11 # cursor = conn.cursor() 12 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 指定返回的数据格式为字典格式 13 sql = "select *from info" 14 15 # ret = cursor.execute(sql) # 返回的不是具体的数据 而是受影响的行数 16 # print("{} rows in set.".format(ret)) 17 cursor.execute(sql) 18 # ret = cursor.fetchall() # 返回所有数据 19 # ret = cursor.fetchone() # 返回第一条效果 20 # print(ret) 21 # ret = cursor.fetchone() # 返回第二条效果 22 # print(ret) 23 ret = cursor.fetchmany(3) 24 print(ret) 25 cursor.scroll(1, mode="absolute") # absolute -> 移动到1上 26 # cursor.scroll(1, mode="relative") # relative -> 光标相对向下移动一个 27 28 ret = cursor.fetchall() 29 print(ret) 30 31 32 33 cursor.close() 34 conn.close()
# SQLAlchemy
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,将对象转换成SQL,然后使用数据API执行SQL并获得结果
SQLAlchemy本身无法操作操作数据库,其必须以pymsql等第三方插件组合,根据配置文件的不同调用不同的数据库API。如:
MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
ORM功能使用
使用ORM/Schema Type/ Engine/Dialect所有组件对数据进行操作。根据组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。
1. 创建表
1 from sqlalchemy.ext.declarative import declarative_base 2 from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index 3 from sqlalchemy.orm import sessionmaker, relationship 4 from sqlalchemy import create_engine 5 6 engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/s4day63db", max_overflow=5) 7 8 Base = declarative_base() 9 10 11 # 创建单表 12 class Users(Base): 13 __tablename__ = ‘users‘ 14 id = Column(Integer, primary_key=True) 15 name = Column(String(32)) 16 extra = Column(String(16)) 17 18 __table_args__ = ( 19 UniqueConstraint(‘id‘, ‘name‘, name=‘uix_id_name‘), 20 Index(‘ix_id_name‘, ‘name‘, ‘extra‘), 21 ) 22 23 24 # 一对多 25 class Favor(Base): 26 __tablename__ = ‘favor‘ 27 nid = Column(Integer, primary_key=True) 28 caption = Column(String(50), default=‘red‘, unique=True) 29 30 31 class Person(Base): 32 __tablename__ = ‘person‘ 33 nid = Column(Integer, primary_key=True) 34 name = Column(String(32), index=True, nullable=True) 35 favor_id = Column(Integer, ForeignKey("favor.nid")) 36 user_type = relationship("Favor", backref=‘xxoo‘) # backref 反向关系 37 38 # 多对多 39 class Group(Base): 40 __tablename__ = ‘group‘ 41 id = Column(Integer, primary_key=True) 42 name = Column(String(64), unique=True, nullable=False) 43 port = Column(Integer, default=22) 44 45 46 class Server(Base): 47 __tablename__ = ‘server‘ 48 49 id = Column(Integer, primary_key=True, autoincrement=True) 50 hostname = Column(String(64), unique=True, nullable=False) 51 52 53 class ServerToGroup(Base): 54 __tablename__ = ‘servertogroup‘ 55 nid = Column(Integer, primary_key=True, autoincrement=True) 56 server_id = Column(Integer, ForeignKey(‘server.id‘)) 57 group_id = Column(Integer, ForeignKey(‘group.id‘)) 58 59 60 def init_db(): 61 Base.metadata.create_all(engine) 62 63 def drop_db(): 64 Base.metadata.drop_all(engine) 65 66 67 Session = sessionmaker(bind=engine) 68 session = Session()
2. 操作表
1 obj = Users(name="alex0", extra=‘dalao‘) 2 session.add(obj) 3 session.add_all([ 4 Users(name="alex1", extra=‘lb‘), 5 Users(name="alex2", extra=‘db‘), 6 ]) 7 session.commit()
1 session.query(Users).filter(Users.id > 1).delete() 2 session.commit()
1 session.query(Users).filter(Users.id > 2).update({‘name‘: ‘099‘}) 2 session.query(Users).filter(Users.id > 2).update({Users.name: Users.name + "099"}, synchronize_session=False) 3 session.query(Users).filter(Users.id > 0).update({"id": Users.id + 1}, synchronize_session="evaluate") 4 session.commit()
1 print(session.query(Users)) # 表达式 2 3 ret = session.query(Users).all() 4 for row in ret: 5 print(row.id,row.name) 6 7 ret = session.query(Users.name, Users.extra).all() 8 ret = session.query(Users).filter_by(name=‘alex1‘).first() 9 print(ret)
1 # 条件 2 ret = session.query(Users).filter_by(name=‘alex‘).all() 3 ret = session.query(Users).filter(Users.id > 1, Users.name == ‘eric‘).all() 4 ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == ‘eric‘).all() 5 ret = session.query(Users).filter(Users.id.in_([1,3,4])).all() 6 ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() 7 ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name=‘eric‘))).all() 8 from sqlalchemy import and_, or_ 9 ret = session.query(Users).filter(and_(Users.id > 3, Users.name == ‘eric‘)).all() 10 ret = session.query(Users).filter(or_(Users.id < 2, Users.name == ‘eric‘)).all() 11 ret = session.query(Users).filter( 12 or_( 13 Users.id < 2, 14 and_(Users.name == ‘eric‘, Users.id > 3), 15 Users.extra != "" 16 )).all() 17 18 19 # 通配符 20 ret = session.query(Users).filter(Users.name.like(‘e%‘)).all() 21 ret = session.query(Users).filter(~Users.name.like(‘e%‘)).all() 22 23 # 限制 24 ret = session.query(Users)[1:2] 25 26 # 排序 27 ret = session.query(Users).order_by(Users.name.desc()).all() 28 ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() 29 30 # 分组 31 from sqlalchemy.sql import func 32 33 ret = session.query(Users).group_by(Users.extra).all() 34 ret = session.query( 35 func.max(Users.id), 36 func.sum(Users.id), 37 func.min(Users.id)).group_by(Users.name).all() 38 39 ret = session.query( 40 func.max(Users.id), 41 func.sum(Users.id), 42 func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() 43 44 # 连表 45 46 ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() 47 48 ret = session.query(Person).join(Favor).all() 49 50 ret = session.query(Person).join(Favor, isouter=True).all() 51 52 53 # 组合 54 q1 = session.query(Users.name).filter(Users.id > 2) 55 q2 = session.query(Favor.caption).filter(Favor.nid < 2) 56 ret = q1.union(q2).all() # 去重 57 58 q1 = session.query(Users.name).filter(Users.id > 2) 59 q2 = session.query(Favor.caption).filter(Favor.nid < 2) 60 ret = q1.union_all(q2).all() # 不去重
标签:要求 遇到 相关 avg lap play 避免 登陆 vertica
原文地址:https://www.cnblogs.com/pythoncui/p/12273702.html
