标签:sea ima utf-8 项目 arch 命名 结果 linux 定义
「TRIGGER」 项目【2020新冠疫情实时监控】中,数据保存出现的问题。
「EXPERIENCE」
一开始以为是数据保存端出现问题,以为是fscanf输入每行以空格分隔字段的文件导致的错误,并修改为以逗号分隔。不曾想修改程序后仍有错误数据保存发生,后经前辈提醒发现错误保存的那一条数据字段栏数匹配之前的数据,只是每个字段的内容有点微妙。
进一步找原因的时候发现在有问题的那一条数据产生时,会提示"标准输入匹配到二进制文件"。于是本该有4个字段的数据文件因为这个原因导致生成的数据文件就只有一个date +"%s"的unix时间。随后c程序中定义的结构也没有初始化,导致fscanf读入的字段只有一个,而后面有五个错误数据就这样产生了。(还不够深入)
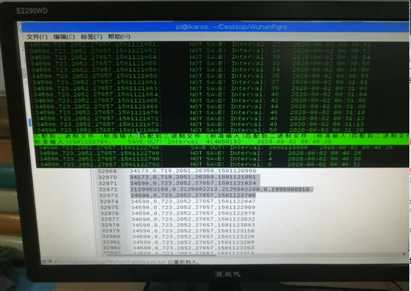
【图片描述:提示标准输入匹配到二进制文件】
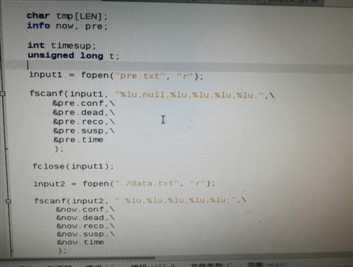
【图片描述:错误数据产生原因】
问题:“标准输入匹配到二进制文件”这一句是谁提示的,具体哪个命令遇到什么情况会提示?
上网查阅后推测,类似提示语句的命令来源为:grep
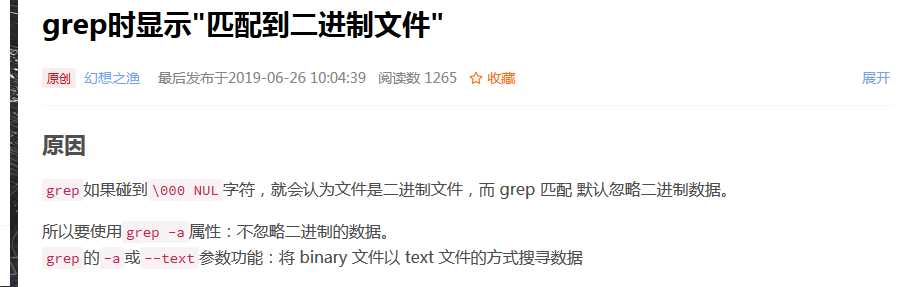
想起自己的数据筛选中好像源数据确实有经过grep筛选
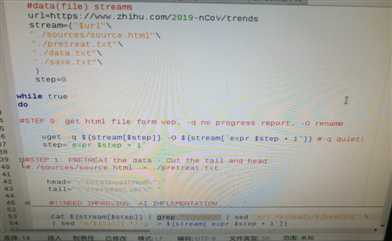
改进:grep -a "$head".
结果:抱着终于搞定了的心态运行了一段时间.. 又出现了问题,程序卡死了。
想起昨天好像也遇到过,但自己那时候居然给无视了...
遂再次请教前辈,前辈指出可能是源数据中有中文的原因。


改进:cat ${stream[$step]} LC_ALL=C grep -a | LC_ALL=C sed "s/^.*${head}"/${head}/g"
结果:前辈要有心理准备...不一定有效测试中...
问题:LC_ALL=C 能作用多长时间?sed前的LC_ALL=C是否重复了?导管会不会重置环境变量?环境变量的作用范围?
「 分支点(新产生的问题)」什么是"C"?

「 分支点」什么是POSIX -> 待填...
「 分支点」环境变量的作用范围 -> 待填...
「 分支点」子shell 父shell -> 待填...
「其他零碎的」
文件命名不能用的符号 / \ : * " < > | ?
grep: Globally search a Regular Expression and Print
不加export命令设置的环境变量只在本shell生效,加上export命令设置的环境变量不仅对本shell生效,对其子shell也生效。
字符编码: UTF-8(国际通用,英文一个字节,中文三个字节), GBK(国家编码,涵盖所有中文。中英文均双字节), GB2312(GBK的基础)
标签:sea ima utf-8 项目 arch 命名 结果 linux 定义
原文地址:https://www.cnblogs.com/shuuei/p/12276112.html